Notas para el curso de Animación por Computadora
Joel Espinosa Longi
Universidad Nacional Autónoma de México
Fondo Editorial RED Descartes
Córdoba (España)
2024
Título de la obra:
Notas para el curso de Animación por Computadora
Autor:
Joel Espinosa Longi
Código JavaScript para el libro: Joel Espinosa Longi, IMATE,
UNAM.
Imagen de portada: Joel Espinosa Longi
Tipografía: WorkSans, Aleo y UbuntuMono
Fórmulas matemáticas: $\KaTeX$
Red Educativa Digital Descartes
Córdoba (España)
descartes@proyectodescartes.org
https://proyectodescartes.org
Proyecto iCartesiLibri
https://proyectodescartes.org/iCartesiLibri/index.htm
https://prometeo.matem.unam.mx/recursos/VariosNiveles/iCartesiLibri/
ISBN: 978-84-18834-98-1

El contenido de esta obra esta bajo una licencia Creative Commons (Atribución-NoComercial-CompartirIgual).
Estas notas surgen con la finalidad de proporcionar un soporte al contenido de un curso “Animación por Computadora”, y presentan de manera general e integrada los temas más relevantes que un estudiante debe conocer sobre la Animación por Computadora. Esta obra aborda la parte teórica del curso y se excluye de este documento gran parte de la información de implementación y prácticas sobre software de modelado y animación, para evitar que la obra se vuelva más extensa de lo debido. Además, la implementación y el software a utilizar puede variar dependiendo del profesor que imparta el curso, por lo que partiendo de la libertad de cátedra no se pretende imponer ninguna metodología para impartir el curso.
Los temas expuestos en estas notas se encuentran ordenados siguiendo en gran medida el pipeline de producción de una animación en 3D, conjuntando conceptos de narración, diseño y computación.

La animación por computadora es omnipresente en el mundo actual y se emplea en numerosos contextos y situaciones. Este fenómeno se atribuye principalmente a la importancia que han adquirido los sistemas informáticos en la vida moderna, lo que ha permitido la creación de animaciones más complejas y realistas. Para comenzar a entender qué es la animación por computadora, es importante definirla y examinar los diferentes tipos y medios en los que se puede encontrar.
La palabra animación (https://dle.rae.es/animación) según la RAE se define como la acción y efecto de animar. El verbo animar (https://dle.rae.es/animar) se deriva del verbo latino animāre que significa: vivificar, reanimar, alegrar, infundir o dar ánimo. Entonces, el término animación se refiere a la acción de otorgar o infundir vida, por lo general, a objetos inanimados que no la poseen de forma natural.
El objetivo de la animación por computadora es crear la ilusión de vida para objetos y personajes que existen en un mundo virtual o digital. Para lograr esto, se llevan a cabo cambios en los atributos de los objetos animados, siendo estos atributos los encargados de definir diversas características como la posición, rotación, escala, color, texturas, visibilidad, entre otras más.
La animación por computadora, también conocida como animación digital, es una subárea de la graficación por computadora que se enfoca en estudiar los algoritmos y técnicas para crear objetos y personajes virtuales que se muevan e interactúen, dando la ilusión de vida. Así mismo la animación se trata del arte de crear imágenes en movimiento mediante el uso de una computadora, y como tal, la computadora es una herramienta esencial en este proceso, ya que facilita y acelera tareas que de otra manera serían monótonas y tediosas para un animador. Algunas de estas tareas incluyen la creación de objetos en dos y tres dimensiones, la simulación de fenómenos físicos, la creación de imágenes para el enriquecimiento visual, la interpolación de valores y la generación de las imágenes finales que componen la animación.
Existen tres formas principales de controlar el movimiento o los cambios que pueden presentar los objetos animados en la animación por computadora: animación artística, animación basada en datos y animación procedural.
La animación artística es la forma más artesanal o manual de realizar una animación, ya que aquí el animador controla y coordina directamente el movimiento de los objetos animados. En este proceso, el animador decide la apariencia de los objetos, su movimiento e interacción con otros elementos, todo con el fin de expresar una idea.
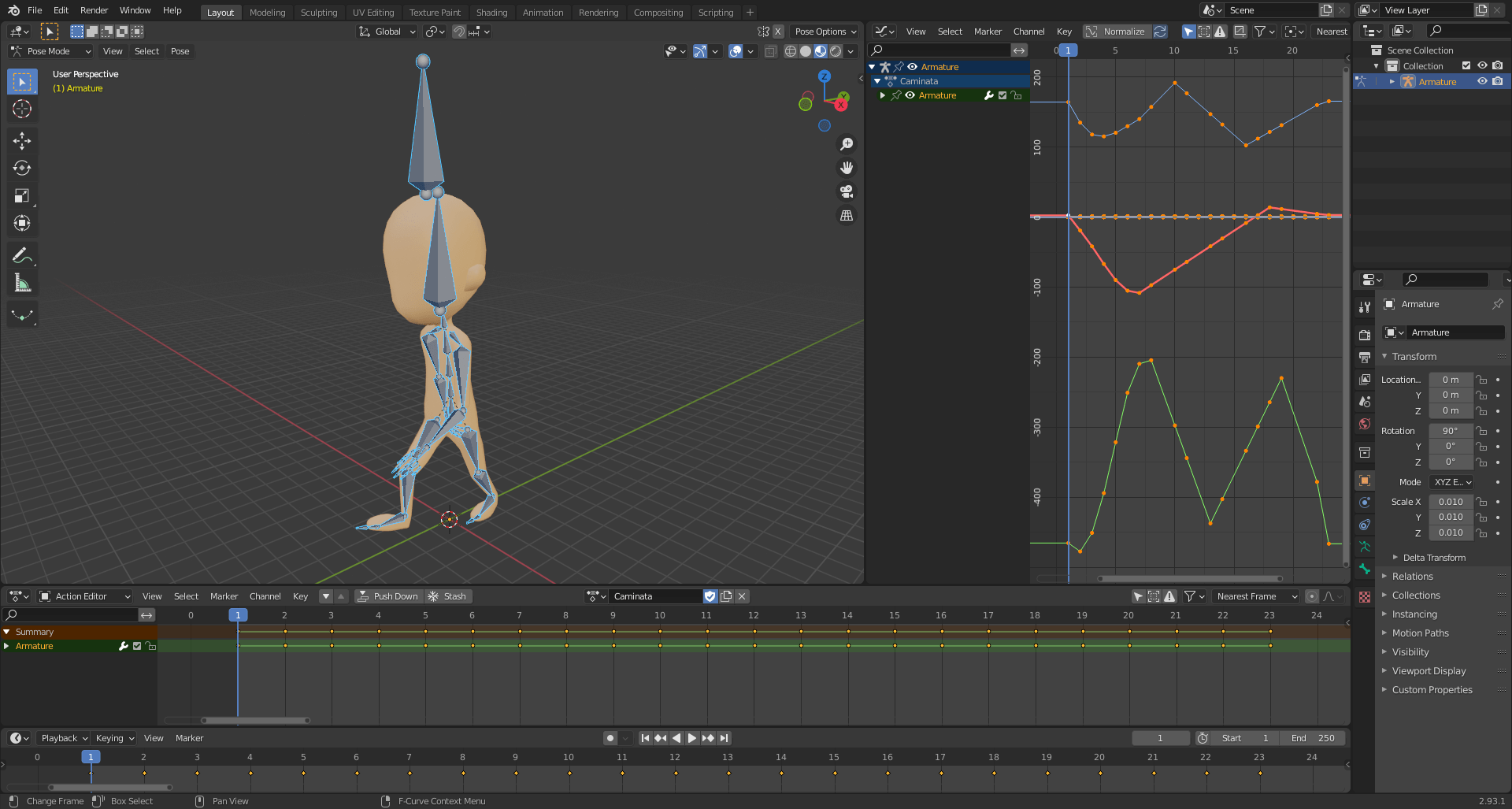
Para lograr este objetivo existen programas de modelado y animación como: Blender, 3ds Max, Maya, entre otros más; los cuales son aplicaciones muy sofisticadas que ofrecen diversas herramientas que permiten al artista manipular, controlar y modificar diferentes atributos de los objetos animados. En la se pueden observar algunas de las herramientas que proporciona Blender para este fin, como la línea de tiempo (parte inferior) y el editor de curvas (a la derecha).
La animación basada en datos (data-driven animation) es un proceso en el que se utilizan datos de movimiento para animar los objetos virtuales. Para ello se emplean diversos sensores que recopilan información del mundo real, con la que se construye una representación computacional de dicha información. Aquí, no se requiere la interacción directa de un animador, ya que los datos de movimiento provienen del mundo real, solo es necesario que intervenga un animador en caso de que los datos requieran algún tipo de ajuste, depuración o modificación particular.
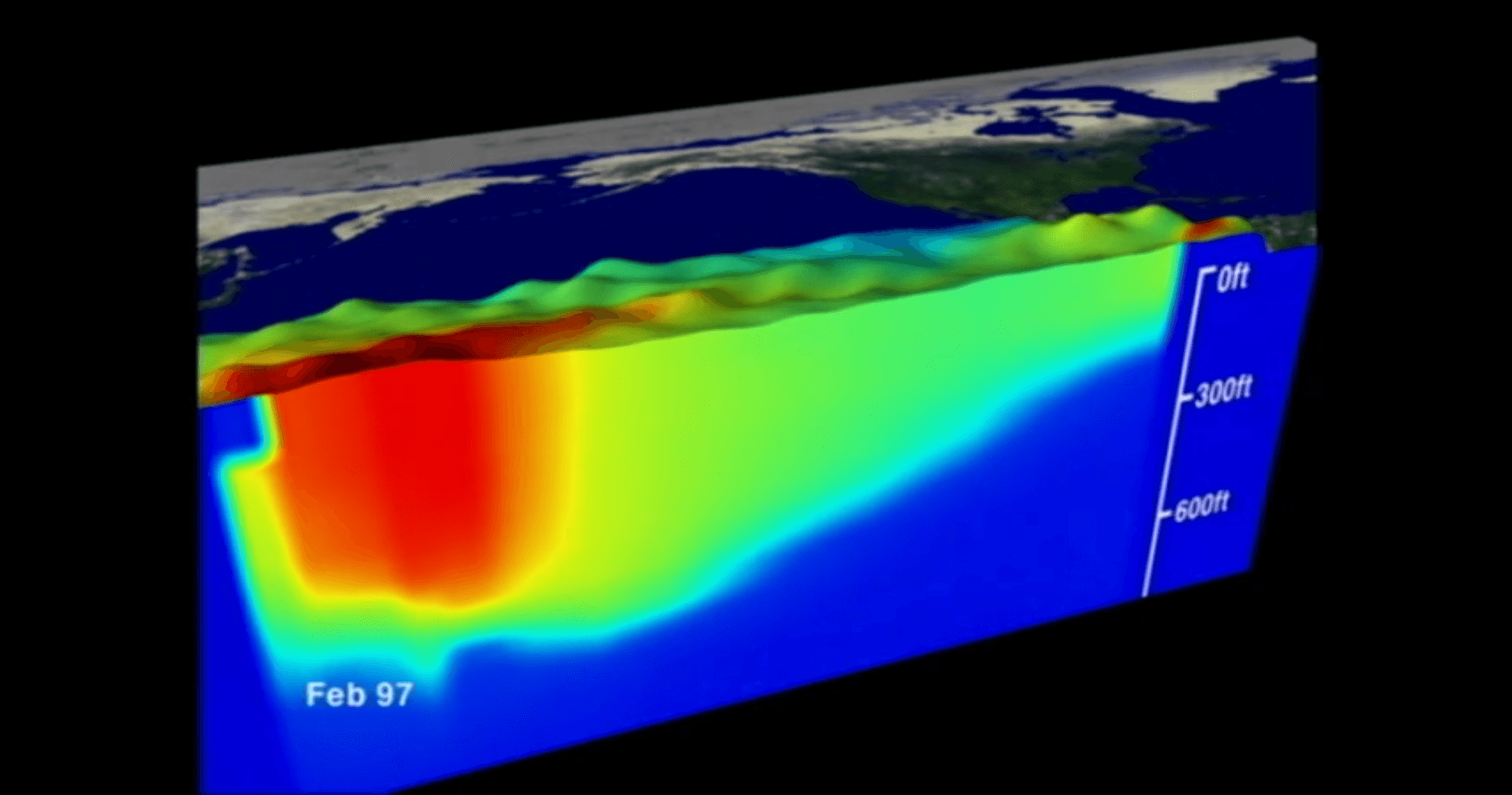
Esta forma de realizar una animación es útil para observar y estudiar fenómenos naturales, por ejemplo, si se tiene un arreglo de boyas en el mar que detectan diversos parámetros, como la temperatura del agua a diferentes profundidades, es posible crear una animación para visualizar los cambios en la temperatura del océano y tener una idea más clara de lo que sucede (ver ). Las animaciones de este estilo se utilizan ampliamente en el campo de la Visualización científica a veces llamada Visualización por Computadora.
Otro uso común de la animación basada en datos es la captura de movimiento (motion capture), donde se registra el movimiento de una persona o animal mediante un traje o marcadores especiales para copiar o replicar dicho movimiento dentro de una animación ().

La animación procedural se basa en un modelo físico que controla los movimientos y cambios de los objetos. Este tipo de animación se utiliza ampliamente en motores de física de videojuegos para simular partículas, trayectorias balísticas, colisiones, reacciones entre objetos, fluidos y otros efectos más. Las animaciones procedurales por lo general se basan en modelos físicos como las leyes de mecánica de Newton, que dotan a los objetos de atributos como masa, velocidad, aceleración y densidad, así como las diversas fuerzas que interactúan con ellos.
Debido a que estas animaciones están basadas en reglas físicas, los animadores tienen poca participación en su creación, solo intervienen definiendo las condiciones iniciales del sistema y las propiedades de los elementos que serán parte de la simulación.

Estas tres formas de controlar los cambios en el tiempo no son excluyentes y pueden utilizarse conjuntamente para diferentes objetos o momentos dentro de una animación. Por ejemplo, es posible tener un personaje que realiza sus movimientos gracias a información de captura de movimiento (animación basada en datos), mientras que su ropa se mueve por medio de un motor de física que determina cómo las prendas deben comportarse (animación procedural), y para movimientos complicados que no son realizables por un actor, un animador puede realizar dichos movimientos de forma manual (animación artística), creando así una animación completa.
Actualmente, la animación por computadora se utiliza en diversos ámbitos y medios, siendo la ciencia y el entretenimiento los principales exponentes y usuarios de estas técnicas. Aún así existen otros campos que también exploran el uso de la animación por computadora para presentar información de manera creativa y atractiva. En general, la animación por computadora se emplea en cualquier situación en la que se requiere transmitir información de manera visual y mostrar cambios a lo largo del tiempo. Los objetivos de las animaciones pueden variar desde entretener hasta comprender los cambios que ocurren en algún fenómeno natural.
El entretenimiento es una actividad que las personas realizan para disfrutar del tiempo libre, a lo largo del tiempo, esta actividad ha evolucionado, adaptándose a las tendencias y tecnologías de la época. La animación por computadora se ha convertido en un medio importante para el entretenimiento, debido a que aprovecha los avances tecnológicos modernos para contar historias cada vez más diversas e interesantes.
Las películas u obras cinematográficas son un medio de entretenimiento que narra una historia a través de actores, escenarios y las acciones que se desarrollan. La animación por computadora ha ganado importancia en la producción de películas, ya que su uso facilita la creación de imágenes para componer la obra, permitiendo crear escenarios y personajes fantásticos que no pueden ser creados fácilmente en la vida real.
Hay dos categorías principales de películas creadas mediante la animación por computadora: las completamente animadas y las que utilizan efectos especiales generados por computadora.
Las películas totalmente animadas son un ejemplo claro de lo qué es la animación por computadora, ya que combinan de forma integral técnicas y conceptos de cine, animación tradicional y graficación por computadora. En este tipo de películas, todas las imágenes que componen la obra son generadas enteramente por una computadora.
Es importante destacar que las películas totalmente animadas han ganado una gran popularidad en la industria del cine, ya que al no depender de actores o escenarios reales, se pueden crear mundos y personajes fantásticos que no serían posibles de otra manera. Además, la animación por computadora permite alcanzar un nivel de detalle y precisión que sería muy difícil de lograr con métodos tradicionales.
Actualmente, hay numerosas películas totalmente animadas, y muchos estudios de animación se dedican a su creación. Algunos ejemplos de películas totalmente animadas incluyen:




Los ejemplos anteriores vienen por parte de estudios Hollywoodenses, que son de los más conocidos a nivel mundial, aún así existen diversos estudios de animación en todo el mundo que desarrollan animaciones generadas por computadora.
Por ejemplo, la fundación Blender con sede en Amsterdam, a través de Blender Studio ha creado varios cortos animados para probar las características y necesidades de la herramienta Blender. Algunas de las animaciones que han realizado son:




México cuenta con algunos estudios de animación, como Ánima Estudios y Huevocartoon, que comenzaron desarrollando animaciones en 2D, pero actualmente también desarrollan animaciones en 3D. Algunos ejemplos de sus producciones en 3D son:


Otras películas completamente animadas por computadora, desarrolladas en otras partes del mundo, incluyen:








Las películas que utilizan efectos especiales generados por computadora son aquellas en las que se filman actores o escenarios en el mundo real y se agregan elementos generados por computadora, como fondos, personajes u otros elementos. El término “efectos especiales” es muy amplio y puede incluir cualquier elemento visual agregado a una grabación del mundo real mediante una computadora. En estas películas, las gráficas y animaciones generadas por computadora siempre se combinan con elementos producidos y grabados en la vida real.
Un ejemplo clásico de película que utiliza la animación por computadora como efectos especiales es: Tron de 1982 producida por “Walt Disney Productions” (); que se considera la primera película que mezcla imágenes generadas por computadora o CGI (Computer Generated Imagery) con acción en vivo, y es un buen ejemplo de una película que utiliza la animación por computadora como efectos especiales.

Otros ejemplos de películas que utilizan efectos especiales:






La animación por computadora en películas que la utilizan como efectos especiales ofrece la posibilidad de crear elementos difíciles de construir o crear en la vida real, enriqueciendo las posibilidades narrativas del medio permitiendo explorar ideas fuera de la realidad y presentarlas en una pantalla de una manera más realista y convincente.
La televisión es un medio de entretenimiento que presenta obras audiovisuales en horarios predeterminados, que a menudo incluyen pausas para comerciales. Se pueden ver en la televisión, muchos años después, películas que fueron estrenadas en cines; así como programas específicos para este medio, como series televisivas, que cuentan historias largas divididas en varios episodios.
Los servicios de streaming han cambiado algunas cosas de la televisión tradicional, como la forma en que se accede al contenido, lo que permite ver programas sin pausas comerciales en el momento y horario que el espectador desee. Aunque la forma de acceder al contenido ha cambiado, el concepto de serie televisiva sigue siendo popular en los medios de streaming actuales ya que permite dosificar el contenido de una historia en diversos episodios o capítulos.
En cuanto al uso de la animación por computadora en la televisión, se encuentran las mismas dos categorías que en el cine: completamente generadas por computadora y como efectos especiales. Hay que mencionar que las producciones televisivas o de streaming suelen tener más restricciones de presupuesto, tiempo y alcance, que las producciones cinematográficas, lo que se puede observar en la reducción de la calidad visual de las producciones televisivas. Algunos ejemplos de animación en la televisión generada completamente por computadora son:






También es posible encontrar producciones donde se utilizan diversos medios para generar la animación, como es el caso del “El asombroso mundo de Gumball”, donde se pueden observar animación 2D tradicional, animación 3D y elementos de acción en vivo, todo mezclado de forma coherente y que le imprime vida propia a la producción.

Ejemplos de animación en la televisión (o streaming) donde se utiliza la animación por computadora como efectos especiales:




Un videojuego es un sistema electrónico que permite la interacción de un jugador con un mundo virtual, principalmente a través de elementos gráficos como textos, menús, modelos 3D e imágenes. La animación por computadora se utiliza en los videojuegos para presentar el estado del juego a través de gráficas interactivas, como la animación del personaje principal y las interacciones con otros objetos, y para videos pregrabados que cuentan la historia del juego.
La animación por computadora se utiliza en los videojuegos con dos propósitos principales:
Hace muchos años atrás, se apreciaba una gran diferencia en la calidad visual entre las gráficas interactivas y las cinemáticas, ya que las cinemáticas solían utilizar animaciones generadas previamente u offline (como en una película), mientras que las gráficas interactivas se generan en tiempo real por lo que su calidad depende del poder de cómputo de la máquina que ejecuta el videojuego. Sin embargo, con el avance de la tecnología la distinción se ha vuelto cada vez menor, haciendo que en la actualidad muchas de las animaciones presentadas en las cinemáticas utilicen las mismas gráficas de la parte interactiva, limitando solo la interacción del jugador y ecualizando su presentación.
Los videojuegos clásicos como Pong, Space Invaders, Pac Man, entre otros muchos más, a pesar de su apariencia simple en comparación con los videojuegos modernos, utilizan elementos esenciales de la animación por computadora para presentar los cambios e interacciones entre los objetos. La animación de personajes y objetos, detección de colisiones, programación de inteligencia artificial y física del juego que se desarrollaron en estos juegos sentaron las bases para muchos videojuegos modernos, siendo pioneros en el desarrollo de videojuegos al proporcionar las bases de muchos de los elementos que se utilizan actualmente.
Debido a las limitaciones tecnológicas de la época en la que fueron desarrollados, estos juegos no podían hacer uso de gráficos avanzados en 3D o animaciones complejas. En su lugar, se valieron de animaciones simples pero efectivas para mejorar la interacción y la presentación del juego. Por ejemplo, en el caso de Pong, la animación del movimiento de la pelota y las paletas, la detección de colisiones y el cambio de dirección de la pelota se realiza mediante técnicas de simulación, graficación y animación por computadora.



Con el avance de la tecnología, los videojuegos han experimentado un cambio significativo logrando representaciones visuales más ricas y atractivas. Un elemento fundamental en esta evolución ha sido el uso de imágenes conocidas como sprites, que son gráficos en 2D empleados para representar personajes, objetos y elementos del escenario dentro del juego. Los sprites han estado presentes desde las etapas iniciales del desarrollo de videojuegos, siendo un recurso esencial para la presentación visual de los mismos. Estos gráficos se han vuelto cada vez más complejos y detallados; y en la actualidad, los desarrolladores pueden crear sprites de alta resolución y detalles diseñados minuciosamente, permitiendo una representación atractiva de los elementos del juego.
Además de su uso para representar elementos del juego, los sprites pueden ser manipulados de diferentes maneras para crear efectos visuales interesantes. Por ejemplo, se puede hacer que un sprite cambie de tamaño o se desvanezca en la pantalla para crear una sensación de profundidad y movimiento, así mismo se pueden crear capas de sprites para crear un efecto de paralaje, que da la sensación de que los elementos del juego se mueven a diferentes velocidades.
Algunos ejemplos de juegos que utilizan sprites se muestran a continuación:






Existen juegos que combinan imágenes en 2D (sprites) con mundos tridimensionales, donde se conjuntan las técnicas de animación 2D con las 3D, a este tipo de mezcla se le conoce como 2.5D haciendo referencia a algo intermedio entre dos y tres dimensiones. En este tipo de videojuegos, aunque los mundos y a veces los personajes sean tridimensionales, el movimiento está restringido a dos dimensiones, es decir, a diferencia de los juegos completamente en 3D, el movimiento está limitado a un plano de acción o a una cámara que generalmente se encuentra fija durante el movimiento del personaje, por lo que no es posible manipular libremente la cámara para explorar el entorno. Algunos ejemplos serían:


Una de las ventajas de los juegos en 2.5D es que pueden utilizar sprites detallados con los que se ofrecen mundos visualmente atractivos, sin la necesidad de tener una computadora muy potente, como se requeriría para un juego completamente en 3D.


El aumento en el poder de cómputo ha permitido la representación de mundos virtuales cada vez más complejos, estas mejoras en las capacidades computacionales ha dado lugar a la creación de nuevos algoritmos que representan la realidad de manera más fiel y proporcionan herramientas más sofisticadas para la creación y animación de estos mundos.
Los avances en la tecnología de motores de videojuegos y herramientas de creación han permitido a los desarrolladores diseñar entornos virtuales más detallados y realistas que nunca, lo cual contribuye a experiencias de juego más inmersivas y atractivas. Las grandes producciones de videojuegos suelen utilizar gráficos en 3D para ofrecer una representación del juego lo más realista o estilizada posible.
Con los avances tecnológicos en motores de videojuegos como Unreal Engine y Unity, y en herramientas para la creación de modelos, texturas y animaciones como MetaHuman o Blender, el realismo en los videojuegos se ha convertido en un factor que los jugadores valoran y buscan. Gracias a esto, los desarrolladores pueden crear mundos virtuales cada vez más detallados y realistas, lo que permite a los jugadores sumergirse en experiencias de juego cada vez más estimulantes e inmersivas. Además, los motores de videojuegos modernos ofrecen una amplia gama de herramientas para crear efectos visuales impresionantes, como iluminación dinámica, sombras y efectos climáticos, lo que contribuye aún más a la sensación de realismo.




Algunos ejemplos de juegos en 3D que buscan el fotorrealismo:



En los videojuegos, se busca tanto la representación realista en 3D como la emulación de diferentes estilos artísticos. Por ejemplo, los juegos con estilo anime o caricaturesco utilizan técnicas como texturas y sombras, colores saturados y formas simplificadas para lograr una apariencia estilizada y artística. Estos estilos pueden ser atractivos para los jugadores en busca de una experiencia visualmente única y creativa.
Ejemplos de juegos 3D que intentan parecer 2D:



A continuación se presentan un par de videos y , donde se pueden ver las gráficas utilizadas en el juego Final Fantasy VII original de 1997 y su remake lanzado en 2020. Al observar los videos se puede apreciar cómo la tecnología ha permitido a los desarrolladores crear gráficas más avanzadas y realistas en el remake, lo que refleja la evolución de la industria de los videojuegos en los últimos años. Además, el remake realiza una reinterpretación del estilo artístico del juego original para adaptarse a las expectativas de los consumidores y su capacidad para crear gráficas más detalladas y realistas.

La principal diferencia entre la animación utilizada en cine y televisión con la empleada en videojuegos, radica en el grado de interacción que tiene el usuario (o espectador). En el cine y la televisión, el espectador es un mero receptor pasivo que observa un contenido pregrabado, mientras que en los videojuegos, el usuario se convierte en un actor que controla las acciones de un personaje y se vuelve un elemento fundamental de la experiencia. Aunque es cierto que algunos videojuegos utilizan cinemáticas para narrar partes de la historia, esto no es una característica presente en todos ellos y, en cualquier caso, no constituye la totalidad del videojuego.
La publicidad tiene tres objetivos fundamentales:
Siguiendo estos tres objetivos, la animación publicitaria se enfoca en presentar un producto o servicio de forma concisa, creativa y dinámica, con la intención de fomentar su consumo. Los anuncios publicitarios, también conocidos como comerciales o spots, suelen ser animaciones breves y claras que buscan atraer la atención de los posibles clientes y vender un producto o servicio de la manera más rápida y eficiente posible.
La animación por computadora ofrece una serie de ventajas para la creación de anuncios publicitarios. Una de las más importantes es que permite a los publicistas crear escenas que serían imposibles de filmar en la vida real, lo que proporciona una gran libertad creativa para diseñar anuncios que sean memorables y que capten la atención de los consumidores. Otra ventaja es que los publicistas pueden hacer cambios y ajustes fácilmente a lo largo del proceso de producción, lo que es muy útil para cumplir con plazos y presupuestos ajustados, y así mismo permite a los publicistas explorar diferentes opciones creativas antes de decidir cuál es la mejor para su anuncio.
Ejemplos de publicidad:




La animación desempeña un papel vital en el ámbito científico al facilitar la explicación y comprensión de fenómenos físicos, químicos o biológicos. Su objetivo principal es proporcionar una visualización clara que permita estudiar e interpretar las características fundamentales de dichos procesos.
Desde una perspectiva educativa, la animación ha adquirido un rol crucial en la ciencia, al ofrecer una herramienta invaluable para presentar procedimientos médicos y biológicos difíciles de observar directamente. Esto no solo facilita la enseñanza del conocimiento, sino que también hace que la comprensión de estos conceptos sea más accesible para los estudiantes.
En el contexto de las animaciones científicas, se enfatiza la transmisión de información precisa y efectiva sobre un fenómeno en particular. Muchas representaciones basadas en datos reales permiten replicar procesos naturales con una alta grado de precisión, no obstante, es igualmente posible emplear técnicas más artísticas siempre que se pueda transmitir la información de manera clara y eficiente.
La animación 3D es ampliamente utilizada en el campo de la medicina para visualizar y exponer procesos biológicos complejos y diversas enfermedades. También desempeña un papel fundamental en la comunicación de procedimientos clínicos, proporcionando una representación detallada que facilita la comprensión del paciente y del personal médico, principalmente en situaciones donde las grabaciones reales no son posibles.
Ejemplos de procesos biológicos:

Ejemplos de procedimientos médicos:


La animación también se utiliza en el análisis forense, especialmente para recrear escenas de crímenes, esto proporciona una visión más clara de los sucesos que tuvieron lugar en diferentes tipos de delitos y facilita una comprensión más completa de los hechos.
Para recrear las circunstancias en las que ocurrió un delito, se aplican técnicas de simulación y animación, que incluye la localización de los objetos e individuos involucrados, así como la trayectoria de las balas y otros datos obtenidos en el lugar del crimen. La animación forense se ha convertido en una herramienta esencial para los criminalistas, ya que proporciona información relevante en situaciones donde los testigos son limitados o poco confiables.
Además, es posible analizar estos elementos desde múltiples perspectivas, lo cual permite obtener una comprensión más completa y precisa de los hechos, de esta manera la animación forense puede aportar información vital en el desarrollo de pruebas sólidas que contribuyen a resolver los delitos.
Algunos ejemplos de animación en el análisis forense:



La utilización del software de diseño asistido por computadora (Computer-Aided Design, CAD) se remonta prácticamente al inicio de la graficación por computadora, ofreciendo la posibilidad de simplificar y mejorar el proceso de creación y diseño de planos arquitectónicos.

La animación por computadora se ha convertido en una herramienta útil para los arquitectos, ya que les permite mostrar la construcción de estructuras arquitectónicas como parte del proceso de diseño y planificación. De esta forma, pueden manipular y visualizar la construcción antes de comenzar con el trabajo en el mundo real, lo que facilita la exploración de diferentes tipos de materiales y acabados, así como de diversas técnicas de construcción.
Algunos ejemplos de animación en la arquitectura:


Además, la animación por computadora ofrece la posibilidad de realizar reconstrucciones virtuales para visualizar áreas dañadas o lugares que ya no existen en la actualidad, lo que permite preservar y estudiar el patrimonio arqueológico de forma no destructiva, brindando una visión tridimensional del pasado. A este uso de la animación se le conoce como arqueología virtual.
Algunos ejemplos se muestran a continuación:


Los sistemas CAD también se utilizan para el diseño y visualización de productos, y en este caso la animación permite mostrar el procedimiento de ensamblado de los diversos componentes que forman un producto. Esta técnica ayuda en la manufactura y construcción, permitiendo probar el procedimiento más efectivo para desarrollar y producir un producto antes de llevarlo a las líneas de producción.
Ejemplos de productos y prototipos:




La animación por computadora no solo es una herramienta utilizada en la industria del entretenimiento o en la ciencia, sino que también desempeña un papel relevante en diversos campos como el arte, los medios experimentales y las plataformas de interacción social.
En el arte, la animación va más allá del cine (también conocido como el séptimo arte), ya que se han explorando nuevas formas de utilizar la animación por computadora para enriquecer, para mejorar y potenciar diferentes tipos de expresiones artísticas.
Una técnica que se ha utilizado en los últimos años es el projection mapping o video mapping, la cual se encarga de proyectar imágenes generadas por computadora dentro de espacios físicos reales, como galerías de arte, museos o construcciones urbanas; con la finalidad de hacer la experiencia más lúdica, interesante y entretenida para el público.
Algunos ejemplos:




Se han realizado diversos experimentos para usar la animación por computadora y complementar o mejorar las experiencias musicales, desde la creación de artistas virtuales y vídeos musicales animados, así como la integración de tecnologías de realidad virtual y aumentada. Estos desarrollos no solo enriquecen la experiencia musical, sino que también abren nuevas oportunidades para la creatividad y la innovación en la industria de la música. Con el avance constante de la tecnología, se espera que aparezcan más formas innovadoras de combinar música y animación, llevando la experiencia auditiva y visual a nuevos niveles.




Dado el progreso tecnológico, la realidad aumentada y la realidad virtual se han convertido en herramientas cada vez más populares y accesibles para una amplia variedad de personas, desde los usuarios de dispositivos móviles hasta los desarrolladores de juegos y aplicaciones.
La realidad aumentada superpone información virtual en el mundo real, mejorando la experiencia del usuario en sectores como la educación, el turismo, comercio electrónico, entre otros.
Ejemplos de realidad aumentada:


Por otro lado, la realidad virtual crea entornos virtuales completamente inmersivos que pueden ser experimentados a través de dispositivos como visores de realidad virtual o controladores de movimiento. Esto puede generar experiencias emocionantes y realistas en áreas como el entretenimiento, el entrenamiento o terapias de rehabilitación.
Algunos ejemplos de realidad virtual:


En ambos tipos de realidades (virtual y aumentada) la creación de personajes y escenarios generados por computadora es esencial para crear experiencias convincentes y realistas. Los personajes virtuales pueden interactuar con el usuario en tiempo real y proporcionar información útil, mientras que los escenarios pueden ser diseñados para ser detallados y realistas, permitiendo al usuario sentir que están realmente dentro del mundo virtual. La capacidad de crear mundos virtuales también permite a los desarrolladores de software experimentar con diseños y escenarios que serían imposibles o demasiado peligrosos de probar en la vida real.
Motion graphics es una técnica de animación que se utiliza para presentar información de manera visualmente atractiva y comprensible, donde por medio del movimiento de texto y gráficos, se busca comunicar de manera efectiva un mensaje o idea. Esta técnica es utilizada en diversos campos, como el diseño gráfico, la publicidad, el cine y la televisión, y ha ganado gran popularidad en los últimos años debido a su capacidad para capturar la atención del espectador y comunicar información compleja de manera clara y concisa.


Los avances en la animación por computadora permite crear avatares cada vez más realistas y personalizados, lo que contribuye a mejorar la experiencia del usuario en las interacciones virtuales. Los avatares se utilizan en diversas aplicaciones, desde juegos en línea hasta reuniones virtuales de trabajo, permitiendo a los usuarios interactuar en un entorno virtual de manera natural y efectiva.
En los videojuegos, por ejemplo, los avatares se utilizan para crear personajes personalizados que los jugadores pueden controlar para explorar un mundo virtual. Los avatares también se utilizan en redes sociales y aplicaciones de mensajería, permitiendo a los usuarios comunicarse y compartir información en un entorno virtual personalizado.
En el ámbito educativo el uso de avatares ha ganando popularidad, ya que se utilizan para representar a los estudiantes en entornos virtuales de aprendizaje, permitiendo a los educadores crear experiencias de aprendizaje más interactivas y personalizadas; permitiendo que los estudiantes puedan participar en discusiones en línea, realizar tareas y experimentos virtuales, así como participar en actividades de aprendizaje colaborativo.




Existen distintos tipos de animación por computadora y su uso dependerá principalmente de los siguientes factores:
En conclusión, la animación por computadora se utiliza en diversos contextos como películas, videojuegos, publicidad y presentaciones virtuales. Su uso está influenciado por el presupuesto, la calidad de la imagen y el tipo de interacción requerida. La capacidad de la animación por computadora para mejorar la experiencia del usuario hace que su uso sea cada vez más común y diverso en la industria del entretenimiento y la ciencia.
El sistema visual de muchos seres vivos ha evolucionado para percibir e interpretar el movimiento con el fin de sobrevivir en entornos peligrosos y en constante cambio.
La animación se basa en una ilusión óptica que se produce cuando se presenta una serie de imágenes con pequeñas variaciones, a una velocidad lo suficientemente alta para que el espectador interprete las diversas imágenes como una única imagen en movimiento. Este efecto se logra gracias al complejo mecanismo ojo-cerebro que permite ver e interpretar el mundo.
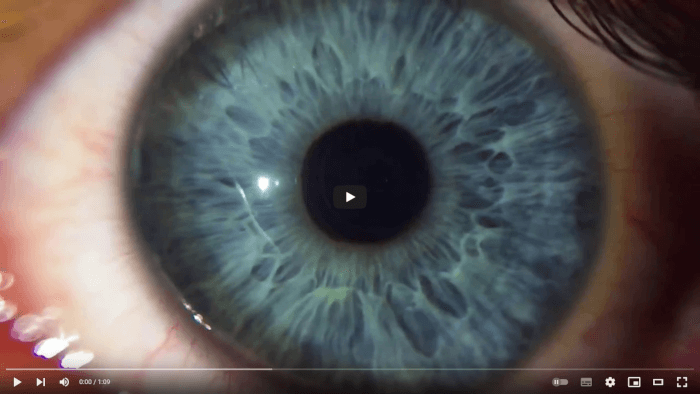
Los ojos humanos tienen diversas partes con funciones muy específicas que permiten observar y percibir imágenes. En la se muestran las diferentes partes que componen el ojo humano. Y a continuación, se describe brevemente cómo se percibe una imagen.
Lo primero que se necesita para percibir una imagen es una fuente de iluminación, ya que sin ella no sería posible ver nada. En un entorno, la luz procedente de una fuente de iluminación llega a diversos objetos y al interactuar con el material que los compone, una parte de dicha luz se refleja hasta llegar al ojo.
Para ingresar en el ojo la luz pasa a través de la córnea, que es una membrana transparente situada en el exterior del ojo y que sirve como protección contra elementos dañinos.
Una vez que la luz ha pasado a través de la córnea, llega a la pupila, que es el centro del iris y la entrada por donde accede la luz al interior del ojo.
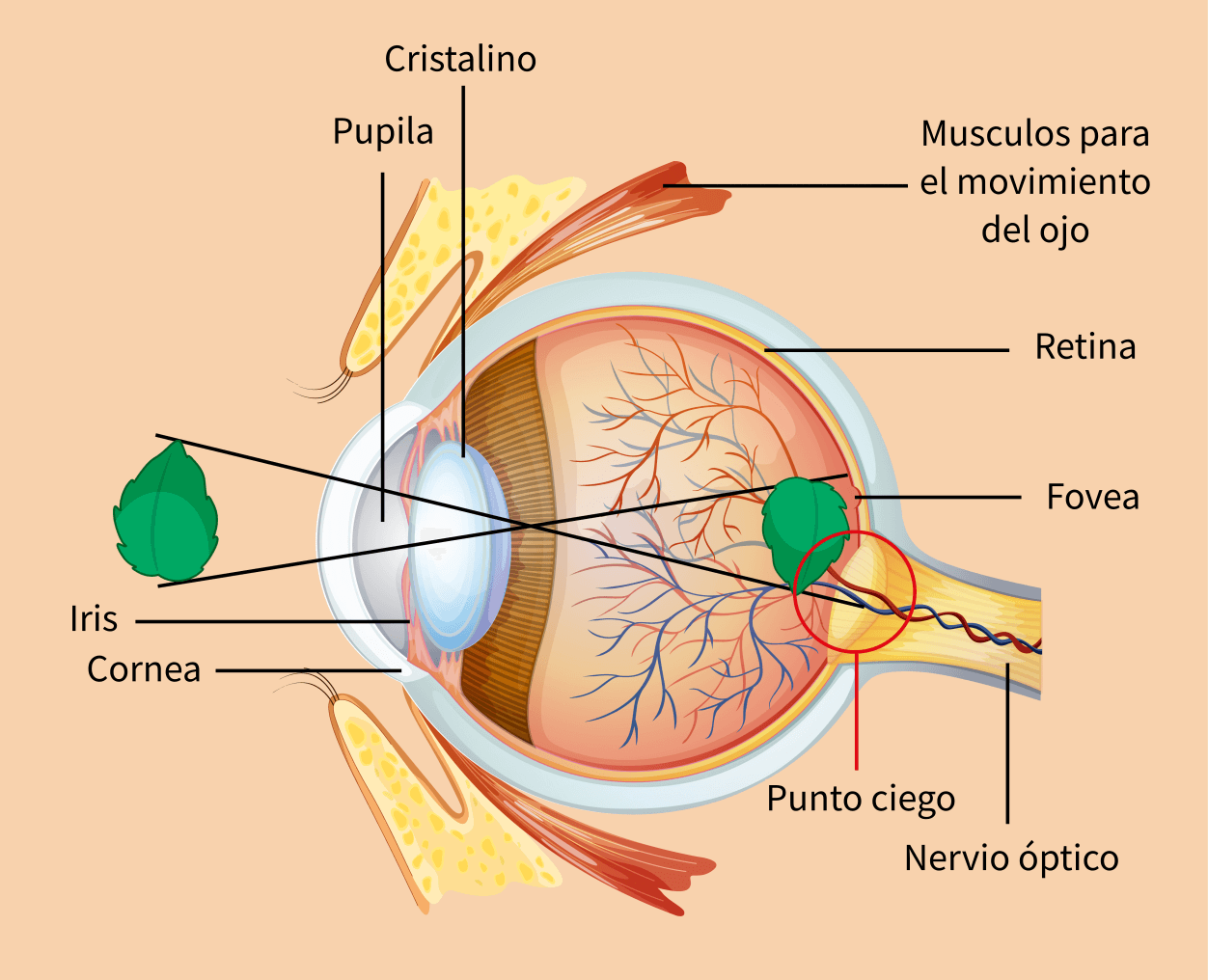
El iris es un músculo que regula la cantidad de luz que entra en el ojo, relajándose o contrayéndose en función de la cantidad de luz presente en el ambiente. Esto provoca que la pupila se dilate en condiciones de poca luz para permitir que entre más luz en el ojo, lo que permite ver en ambientes con poca iluminación. O que se contraiga en ambientes muy iluminados, con la finalidad de prevenir daños en las estructuras internas del ojo.
La luz que pasa por la pupila llega al cristalino, un pequeño lente dentro del ojo que es flexible y puede cambiar su forma para que la luz llegue a la retina o fondo de ojo, enfocando o desenfocando objetos a diferentes distancias.
Finalmente, la luz llega al fondo del ojo donde se encuentra la retina, una estructura que contiene dos tipos de células fotosensibles: los conos y los bastones; los cuales se encargan de enviar impulsos eléctricos a través del nervio óptico hacía el cerebro. Los conos y los bastones toman su nombre de su forma y tienen diferentes funciones.
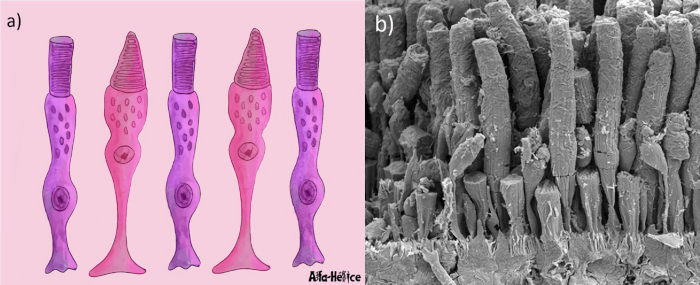
Los bastones son responsables de la percepción visual fuera de la zona de atención, también conocida como la visión periférica. Así mismo son las encargadas de la visión nocturna, ya que son sensibles a los cambios de iluminación.
Los conos por su parte se encargan de la agudeza visual, permitiendo percibir detalles finos, así como la percepción de los colores.
Dentro de la retina existe una pequeña área llamada fovea, que contiene una gran cantidad de conos y es la zona donde las imágenes se ven con mayor nitidez y definición.
En el ojo humano existen tres tipos de conos especializados en percibir diferentes longitudes de onda de la luz:
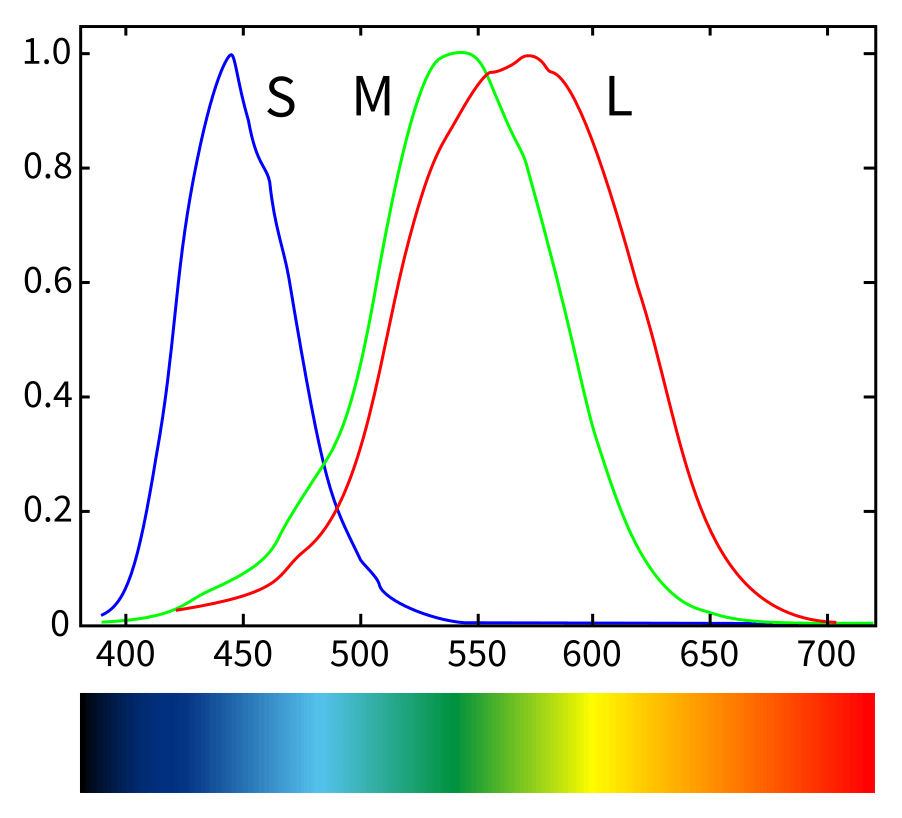
Entonces, una vez que la luz interactúa con los objetos y se refleja hasta entrar en el ojo, se estimulan los conos y los bastones en la retina (y la fovea) creando señales eléctricas que pasan por el nervio óptico hasta llegar al cerebro, donde finalmente se interpreta la información y se crea una imagen.
Para convertir la luz en una señal eléctrica, los conos y los bastones realizan un proceso químico que toma aproximadamente 25 milisegundos en ocurrir. Además, cuando los fotorreceptores son estimulados, requieren de un breve periodo para relajarse y regresar a su estado original para continuar procesando la información lumínica recibida.
La persistencia de la visión es un fenómeno que ocurre en el sistema visual humano y que permite que una imagen se mantenga durante un breve período de tiempo en el sistema de visión, incluso después de que el estímulo visual haya desaparecido. Este efecto se produce gracias a la capacidad del cerebro para retener la información visual que ha sido percibida y para integrarla con la nueva información visual que se está recibiendo en tiempo real.
Este efecto se debe al hecho de que las células fotosensibles del ojo necesitan un cierto tiempo para recuperarse después de haber sido estimuladas por la luz. Durante este breve período de recuperación, que dura aproximadamente una quinceava parte de segundo, la imagen anterior que se ha percibido se mantiene en la memoria visual a corto plazo.
Si se muestra una secuencia de imágenes a una velocidad similar o mayor a la del tiempo de recuperación de las células fotosensibles, el cerebro es capaz de integrar estas imágenes en una sola imagen en movimiento o en una secuencia de imágenes que parecen estar en movimiento.
La persistencia de la visión es un fenómeno que ha sido ampliamente estudiado en el campo de la psicología visual y la neurociencia, y es un efecto fundamental para entender cómo funciona el sistema de visión humano y cómo se percibe el mundo.
Es importante mencionar que la persistencia de la visión es clave en el funcionamiento de muchas tecnologías y formas de entretenimiento, como el cine, la televisión, los videojuegos y la animación; permitiendo crear la ilusión de movimiento y haciendo que una secuencia de imágenes parezca cobrar vida.
El parpadeo o flicker ocurre cuando las imágenes no se muestran a una velocidad adecuada y no logran crear la ilusión de movimiento, lo que provoca una secuencia intermitente de imágenes. Esto puede ser molesto y cansado para algunos espectadores debido a los continuos cambios visuales, sin embargo, es utilizado intencionalmente en técnicas de animación y producción de efectos visuales. El parpadeo ocurre cuando la velocidad de presentación de las imágenes es demasiado lenta en comparación con el tiempo que las células fotosensibles del ojo necesitan para recuperarse, lo que crea una brecha temporal entre la información visual procesada y la siguiente, interrumpiendo así el flujo de información visual.
Los cuadros por segundo también conocidos como fotogramas por segundo (fps), es un término utilizado en la animación por computadora y otros medios audiovisuales para medir la cantidad de imágenes que se muestran durante un segundo (). Esta métrica es importante ya que determina la fluidez y la calidad del movimiento en la animación.
Para crear la ilusión de movimiento, es necesario presentar una secuencia de imágenes que cambian ligeramente en cada cuadro o fotograma. Cuanto mayor sea la cantidad de cuadros por segundo, más suave y natural será el movimiento percibido por el espectador. Por otro lado, si la velocidad de los cuadros es demasiado baja, el movimiento se percibirá como entrecortado y poco natural.
Es importante tener en cuenta que la cantidad de cuadros por segundo también puede afectar el tiempo y el costo de producción de una animación, ya que cuantos más cuadros se utilicen, mayor será el esfuerzo necesario para crear y renderizar cada imagen. Por lo tanto, los animadores deben encontrar un equilibrio entre la calidad de la animación, el tiempo y el costo de producción.
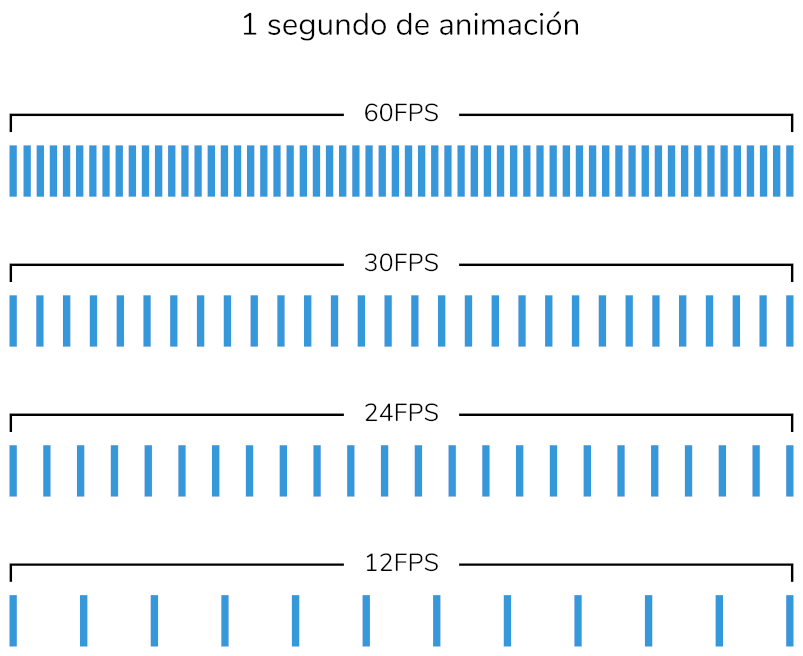
Los seres humanos pueden percibir una sucesión de imágenes como movimiento a partir de los 10 cuadros por segundo, aunque el efecto mejora al presentar más fotogramas. Por ejemplo, en la animación tradicional se utilizan 24 fotogramas por segundo y, por lo general, se repite una misma imagen durante dos cuadros consecutivos, lo que se conoce como dibujar en dos.
Durante la época de la televisión analógica, la mayoría de los países en Norte y Centro América, así como Japón, utilizaban el sistema de televisión NTSC (National Television System Committee), que tenía una tasa de cuadros de 29.97fps. Por otro lado, en Europa y África se utilizaba el sistema PAL (Phase Alternating Line), que tenía una tasa de cuadros de 25fps.
Con la llegada de la televisión digital, se han ampliado las posibilidades de tasa de cuadros, ya que ahora se pueden transmitir entre 23.976fps hasta 60fps. Las tasas de cuadros que se utilizan en la televisión digital dependen de la televisora y del tipo de contenido que se está transmitiendo. Una mayor tasa de cuadros permite una imagen más fluida y suave, especialmente en escenas de acción o movimiento rápido. En los videojuegos, una tasa de cuadros más alta también puede mejorar la jugabilidad al hacer que los movimientos del jugador se sientan más responsivos y precisos. Por otro lado, una tasa de cuadros más baja puede ser suficiente para la transmisión de ciertos tipos de contenido, como programas de televisión con un ritmo más lento o películas con escenas estáticas.
La película El hobbit: un viaje inesperado fue pionera al ser filmada y proyectada en 48fps, el doble de la tasa de cuadros de las películas tradicionales. Este aumento en la cantidad de cuadros por segundo permitió mostrar tomas más suaves y definidas, sin embargo, algunos espectadores expresaron que esta técnica hace que la película se sienta diferente a lo que están acostumbrados con los 24fps, lo que afecta la experiencia del cine tradicional.

En lo que respecta a los fotogramas por segundo, se ha argumentado que no es posible ver o distinguir más de 30 cuadros en un segundo, algunos dicen que el límite es 60fps; sin embargo, la capacidad de percibir una gran cantidad de cuadros por segundo depende de factores fisiológicos como la edad y la estructura ocular del espectador, ya que como se mencionó anteriormente las células fotosensibles necesitan de un breve periodo de tiempo para que perciban nueva información y esto varía de persona en persona y se vuelve más lento con la edad.
Es importante tener en cuenta que incluso si no es posible distinguir más de 30 fotogramas por segundo, tener una mayor cantidad de fotogramas puede ayudar a reducir el efecto de parpadeo (o flicker) y hacer que la animación se sienta más fluida y realista para la mayoría de los espectadores.
El desenfoque de movimiento o motion blur es un efecto visual que ocurre cuando se observan objetos que se mueven a una velocidad mayor a la que el sistema visual puede procesar. En otras palabras, el cerebro no puede construir una imagen nítida de lo que se observa debido a la velocidad del movimiento, lo que da lugar a una imagen borrosa. Este efecto es algo muy común en la vida cotidiana, por ejemplo, cuando se observa un coche que pasa a gran velocidad, o cuando se mueve la cabeza rápidamente mientras se mira un objeto.
En la animación por computadora, el desenfoque de movimiento es una técnica muy importante para conseguir un resultado más realista y natural en las escenas que involucran movimiento. En las películas que utilizan animación por computadora, replicar el efecto de desenfoque es esencial para que la animación parezca más natural y se acerque a la realidad.

El desenfoque de movimiento también se puede producir debido al movimiento propio del ojo. A pesar de que los ojos parecen rígidos, en realidad son un objeto gelatinoso que presenta cierta inercia en su estructura al moverse. Esto puede causar un ligero desenfoque de movimiento en la imagen que se percibe, especialmente si se mueve la cabeza o los ojos rápidamente.
La animación es una forma de arte que ha existido durante siglos y que ha evolucionado significativamente a lo largo del tiempo. Desde los dibujos animados tradicionales hasta la animación por computadora, esta forma de arte ha sido una herramienta poderosa para contar historias y transmitir mensajes a través de imágenes en movimiento.
La animación por computadora, ha surgido gracias a una serie de avances tecnológicos que se han producido en los últimos años. Sin embargo, para entender completamente la historia de la animación por computadora, es importante mirar en conjunto los diversos desarrollos tecnológicos y considerar el contexto en el que se han producido. La fotografía, el cine y la computación han sido elementos clave en el surgimiento de la animación por computadora, y cada uno de ellos ha tenido un papel significativo en su evolución.
En este capítulo, se exploran algunos de los eventos más significativos de la historia de la animación por computadora, desde sus orígenes hasta su posición actual en la industria del entretenimiento. También se presenta cómo los avances tecnológicos y las innovaciones creativas han impulsado el desarrollo de la animación por computadora y cómo esta forma de arte ha transformado la manera en que se crean producciones audiovisuales.
El taumátropo es un dispositivo mecánico que consta de un disco plano unido por una cuerda en sus bordes, con imágenes diferentes en cada lado, de tal manera que al girarlo rápidamente se observa una superposición de las imágenes, dando la impresión de una sola imagen compuesta.
Este dispositivo demuestra cómo la velocidad de presentación de las imágenes puede engañar al cerebro y crear una ilusión visual, lo que se conoce como la persistencia de visión. Este fenómeno es fundamental para el desarrollo de la animación y otros medios de entretenimiento visual. A pesar de que el taumátropo es un juguete sencillo, su valor radica en su capacidad para mostrar de forma simplificada cómo la mezcla de imágenes puede crear una ilusión visual.

En el siglo XIX, Joseph Nicéphore Niépce (), un inventor francés, estaba obsesionado con la idea de capturar imágenes de la realidad y almacenarlas de forma permanente. Para ello, trabajó en la creación de un material fotosensible que permitiera fijar una imagen de manera más eficiente y permanente que los métodos utilizados hasta ese momento.
Después de varios años de experimentación, en 1826 Niépce logró capturar lo que se considera la primera imagen fotográfica de la historia. Para ello, utilizó una cámara oscura y un material fotosensible conocido como betún de Judea, que se aplicaba sobre una placa de metal pulido. La imagen que capturó Niépce fue una vista desde el balcón de su casa en Le Gras, Francia (). La exposición de la placa de metal a la luz de la cámara oscura duró alrededor de ocho horas, tiempo durante el cual la luz fue proyectando la imagen en la placa y el betún fue fijando los detalles.
Aunque la imagen resultante era poco clara y tenía una resolución baja, la fotografía de Niépce fue un hito en la historia de la fotografía, ya que demostró que era posible fijar de manera permanente una imagen capturada por una cámara oscura. Además, sentó las bases para el desarrollo de la fotografía tal como se conoce hoy en día.
La fotografía de Niépce es considerada una obra maestra de la técnica y la persistencia, ya que para conseguirla tuvo que superar múltiples dificultades técnicas y trabajar durante años en el desarrollo de su método. Su legado ha sido fundamental para el avance de la fotografía y ha permitido a la humanidad capturar momentos únicos y preciosos para la posteridad.


El folioscopio o flip book es un dispositivo que consiste en un conjunto de páginas dispuestas en forma de libro, en las cuales se encuentran una serie de imágenes que varían ligeramente de una página a otra. Al pasar rápidamente las páginas con el pulgar, las imágenes parecen moverse y crear una animación. Es otro mecanismo en el que se puede explorar la persistencia de visión de forma sencilla.
El folioscopio es una forma popular de entretenimiento, ya que permite a las personas crear sus propias animaciones de forma sencilla y sin necesidad de equipos especializados. La importancia del folioscopio radica en que permitió la creación y difusión de la animación de forma accesible y económica, sentando las bases para la posterior evolución de la animación como medio artístico y de entretenimiento.

En la actualidad, el folioscopio sigue siendo utilizado por animadores y artistas para crear animaciones de estilo tradicional, y su formato ha sido adaptado a las nuevas tecnologías, como la animación digital. Además, sigue siendo una forma de entretenimiento popular entre niños y adultos por su simplicidad y efectividad en crear animaciones caseras. Algunos ejemplos modernos se puede observar en los siguientes vídeos:


El fenaquistoscopio es un juguete óptico que consiste en un disco plano que tiene varias imágenes ligeramente diferentes entre sí distribuidas en forma radial. Cuando el disco se gira rápidamente y se observa una posición fija dentro del disco, se puede ver cómo las imágenes se combinan para formar una animación. En otras palabras, cada imagen se superpone a la anterior de forma suave y continua, creando una ilusión de movimiento o cambio. La razón por la que el fenaquistoscopio es tan efectivo es porque la rotación del disco permite que las imágenes cambien a una velocidad y estable, de esta manera, la animación se muestra de forma más fluida y sin saltos o interrupciones en el movimiento.
Este juguete óptico fue un gran avance en su época, ya que permitió a las personas experimentar con la animación de una forma mucho más sencilla que antes. Además ayudó a sentar las bases para el desarrollo de tecnologías más avanzadas en el futuro.

El zoótropo o máquina estroboscópica es un dispositivo que consta de un cilindro con cortes verticales a través de los cuales se puede ver hacia su interior. Dentro del cilindro, se coloca una tira con una secuencia de imágenes, y al girar el cilindro y mirar por uno de los cortes, se percibe el cambio de las imágenes. Este juguete al igual que el fenaquistoscopio utiliza la rotación para mostrar de forma estable las diferentes imágenes que componen una animación.

El efecto que se logra con las imágenes al interior del cilindro del zoótropo también se puede obtener con objetos tridimensionales.

El praxinoscopio consiste en un tambor con espejos colocados alrededor de su borde interior, y una serie de imágenes dibujadas en una tira de papel o cartón que se coloca en el centro del tambor. Cuando el tambor gira, las imágenes se reflejan en los espejos y parecen moverse, creando la ilusión de una animación. Este dispositivo representó un avance sobre los dispositivos previos, ya que al usar espejos en su interior las imágenes se ven con mayor claridad y nitidez, lo que permite apreciar la animación desde diferentes ángulos sin perder calidad.

Todos estos dispositivos se utilizaron como entretenimiento o simples curiosidades, pero en el fondo incorporan y emplean los conceptos fundamentales en los que se basa la animación. Gracias a estos artefactos, posteriormente fue posible idear y construir mecanismos más sofisticados, que dieron lugar al cine y, en particular, a la animación.
El fonógrafo fue uno de los primeros dispositivos mecánicos capaces de grabar y reproducir sonido. Su funcionamiento se basaba en el uso de cilindros de cera, que se grababan mediante la vibración de un diafragma que se conectaba a un punzón o aguja. El punzón era el encargado de dejar una huella en la cera, que posteriormente podía ser reproducida mediante un proceso inverso.

El fonógrafo fue un gran avance en su época, ya que permitió la grabación y reproducción de sonidos de forma mecánica, lo que representó una revolución en el mundo de la música y la comunicación. Además, el fonógrafo sentó las bases para la incorporación del sonido al cine, ya que los mecanismos utilizados para grabar y reproducir el sonido en los cilindros de cera, posteriormente se adaptaron para ser utilizados en las películas sonoras.
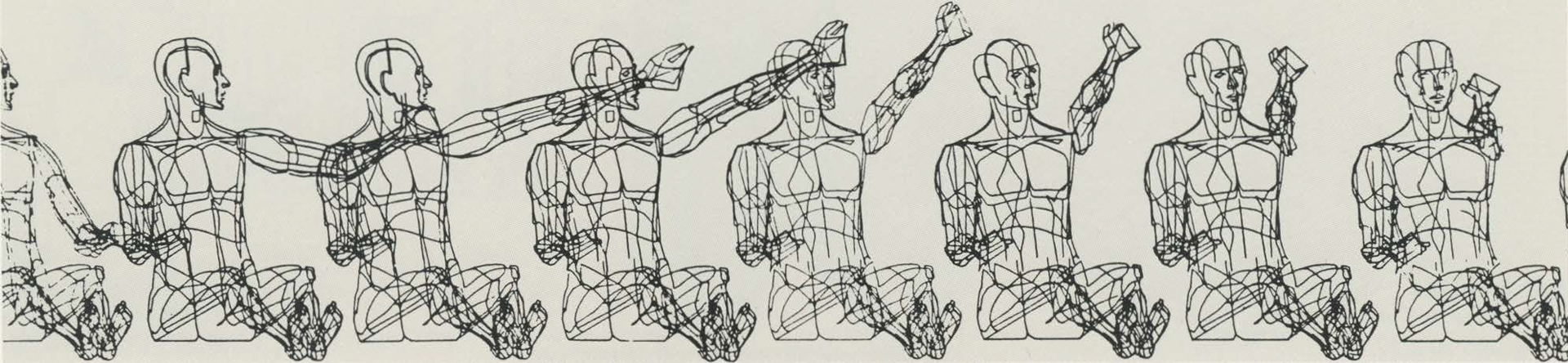
Eadweard Muybridge fue un fotógrafo e investigador del siglo XIX que realizó importantes experimentos fotográficos que serían fundamentales para el desarrollo del cine. Una de sus principales contribuciones fue el desarrollo de técnicas para capturar imágenes consecutivas de alta velocidad, lo que le permitió fotografiar el movimiento de objetos en movimiento, como caballos, personas y otros animales.
En uno de sus trabajo más conocidos, Muybridge colocó múltiples cámaras a lo largo de una pista de carreras y utilizó estas cámaras para capturar imágenes consecutivas de un caballo en movimiento. Al analizar estas imágenes en secuencia, Muybridge pudo observar que los cuatro cascos de un caballo están en el aire al mismo tiempo durante ciertas fases del galope, lo que contradecía la creencia común en la época de que los cascos delanteros y traseros nunca estaban en el aire al mismo tiempo ().

Muybridge también realizó fotografías de personas y animales en diferentes actividades, utilizando la técnica de la fotografía estroboscópica para capturar el movimiento de los sujetos en una secuencia de imágenes fijas. Estos experimentos fueron muy importantes para el desarrollo del cine, ya que demostraron que era posible crear la ilusión de movimiento a partir de una serie de fotografías, lo que fue una de las bases para el futuro cinematógrafo.
Además de las técnicas para capturar las imágenes Muybridge desarrollo un dispositivo para la presentación y proyección de dichas imágenes, el zoopraxiscopio.
El zoopraxiscopio es un dispositivo de proyección que utiliza un disco de cristal para almacenar las imágenes a proyectar, de manera similar al fenaquistoscopio. Las imágenes que se presentan son dibujadas o pintadas a mano en el disco, de manera distorsionada para permitir su posterior proyección.

El quinetoscopio fue un dispositivo que consistía en una caja de madera con un visor en la parte superior y un carrete de película en su interior. Al mirar a través del visor, se podían ver películas cortas que eran creadas por una serie de fotografías presentadas rápidamente.

Aunque el quinetoscopio solo podía ser usado por un espectador a la vez, fue un gran avance para su época ya que a diferencia de sus predecesores, permitió visualizar una mayor cantidad de imágenes, sentando el precedente en la manera en que se almacenarían las imágenes de las películas, ya que al utilizar una tira perforada se abrió la posibilidad de mover y presentar un conjunto de imágenes mediante engranajes para mantener una velocidad constante y adecuada para aprovechar la persistencia de la visión.
El quinetoscopio fue un paso importante hacia lo que actualmente se conoce como el cine, proporcionando una experiencia que se centraba en un solo espectador donde era posible ver una película corta por una moneda. Además, el quinetoscopio fue uno de los primeros dispositivos en incorporar el uso del fonógrafo para presentar películas con sonido, lo que también lo convierte en el precursor del cine sonoro. Esta innovación permitió agregar una dimensión adicional a la experiencia cinematográfica.
El cinematógrafo fue un invento desarrollado por los hermanos Lumière en 1895 y consistía en una cámara y un proyector de cine portátil, con el cual es posible filmar imágenes que se almacenan en una tira de película y además se pueden proyectar en una habitación oscura para ser vistas por el público.

En 1895 se presento la primera película de los hermanos Lumière, “La sortie de l'usine Lumière à Lyon” (); donde se muestra la salida de los trabajadores de la fábrica Lumière. Estos 46 segundos marcaron un punto de inflexión, dando origen a lo que en la actualidad se conoce como el séptimo arte y es considerada como la primera película documental de la historia del cine.

The Humpty Dumpty Circus fue la primera película en utilizar la técnica de animación cuadro a cuadro (stop motion) para crear la ilusión de movimiento en objetos reales inanimados. Aunque desafortunadamente no se dispone de una copia de The Humpty Dumpty Circus, se sabe que la película mostraba una serie de actos circenses realizados por juguetes, que incluían malabarismos, equilibrios y trapecios.
La técnica de animación cuadro a cuadro consiste en tomar una serie de fotografías de un objeto inanimado en diferentes posiciones, y luego reproducir esas fotografías en secuencia para crear la ilusión de movimiento.

Una vez que el cinematógrafo se popularizó y el concepto de película se hizo conocido, al igual que con cualquier nueva tecnología, surgió una etapa de experimentación en la que se puso a prueba cuán lejos se podía llevar dicha tecnología. En el cine, varias personas comenzaron a realizar experimentos en torno a las películas, tratando de aprovechar de forma efectiva todas las cualidades que ofrecía.
Georges Méliès fue un ilusionista y cineasta francés que vivió a finales del siglo XIX y principios del siglo XX. Es conocido por haber sido un pionero en la realización de efectos especiales en el cine, así como en el uso de técnicas de producción y narrativas que revolucionaron la forma en que se hacían las películas en su época.
Entre sus contribuciones más importantes al cine se encuentra el uso de la exposición múltiple, la cámara rápida, la disolución de imágenes y otras técnicas innovadoras para crear efectos especiales. Méliès también fue uno de los primeros cineastas en utilizar guiones gráficos, un método para planificar una película en el que se dibujan los escenarios y los movimientos de cámara antes de filmarlos.
A través de sus películas, Méliès logró contar historias fantásticas y mágicas, utilizando la técnica de la ilusión cinematográfica para crear mundos imaginarios y transportar al espectador a lugares nunca antes vistos. Sus innovaciones técnicas y narrativas abrieron el camino para el desarrollo del cine como una forma de arte y entretenimiento, y su legado continúa influyendo en la industria del cine hasta el día de hoy. En el se presenta una animación en un video de 360º que ofrece un tributo a las diversas películas y aportes de Georges Méliès.

Le Voyage dans la Lune, también conocida como El viaje a la luna, es una película muda francesa realizada en 1902 por el cineasta Georges Méliès. Se inspiró en la novela “De la tierra a la luna” de Julio Verne y en otras obras de ficción científica de la época.
La película sigue las aventuras de un grupo de astrónomos que construyen un cohete para viajar a la luna. Una vez allí, los astronautas exploran el terreno lunar, encuentran una tribu de alienígenas hostiles y finalmente regresan a la Tierra. Esta película es considerada como la primera película de ciencia ficción.

Humorous Phases of Funny Faces es una caricatura animada muda, en la que cada imagen de la animación fue dibujada a mano en un pizarrón y luego fotografiada con una cámara.
Esta animación no cuenta con una trama estructurada, sino que se enfoca en explorar las posibilidades creativas que ofrece la técnica de animación de dibujo cuadro a cuadro, donde el animador dibuja y borra imágenes sobre el pizarrón para crear efectos cómicos y mostrar diferentes expresiones faciales.

The Haunted Hotel es una película muda de terror y comedia que se estrenó en 1907. La trama sigue a un viajero que decide pasar la noche en un hotel embrujado y se enfrenta a diversas escenas espeluznantes y divertidas. Es considerada una de las primeras películas de terror y se destacó por el uso de técnicas innovadoras de efectos especiales, las cuales impresionaron a los espectadores de la época. Además, la película fue pionera en el uso de la comedia como género complementario al terror, sentando un precedente para futuras producciones.
El cortometraje tenía como objetivo representar una casa encantada y para ello se utilizaron técnicas de animación de stop motion para animar los objetos “embrujados” que se mueven por sí solos.

Fantasmagories es una obra pionera en el cine de animación que utilizó la idea de Humorous Phases of Funny Faces, consistente en dibujar y fotografiar imágenes para crear una animación.
La trama de la película es sencilla pero muy imaginativa, y sigue a un personaje que se transforma y se mueve a través de diversos escenarios surrealistas y fantásticos, enfrentando obstáculos y aventuras en su camino. En esta pequeña animación, se pueden apreciar movimientos más sofisticados de animación, con personajes que realizan una variedad de acciones e interacciones. Se considera que Fantasmagorie es la primera caricatura animada en la historia del cine.

Winsor McCay fue un caricaturista estadounidense, reconocido por ser uno de los primeros en introducir historias narrativas en las tiras cómicas. Además, se destacó como un pionero en el ámbito de la animación, siendo uno de los primeros en crear películas animadas populares.
McCay experimentó con técnicas avanzadas para su época, como el uso del color en las animaciones, así como la interacción de personajes animados con personas reales en las películas. La importancia de Winsor McCay en la historia del cine de animación radica en que abrió un camino para el desarrollo del género, al demostrar las posibilidades narrativas y estéticas de la animación y al inspirar a otros animadores a experimentar con nuevas técnicas y estilos.

La animación Little Nemo de Winsor McCay se basa en el personaje homónimo de sus tiras cómicas, y fue su primer intento de crear una película animada con un argumento y personajes expresivos. En la película, Nemo tiene una serie de aventuras oníricas y surrealistas en un mundo imaginario, que es una representación de su propia mente. Este pequeño corto dura alrededor de 11 minutos y fue presentado con una orquesta en vivo que ambientaba la animación.
En esta animación es posible observar una evolución en comparación con los experimentos anteriores, ya que poco a poco las animaciones se vuelven más expresivas y detalladas.

La animación de Gertie el Dinosaurio es una obra destacada por presentar una interesante interacción entre personas del mundo real y un dinosaurio dibujado (en hojas de tamaño de 6.5 por 8.5 pulgadas), pero animado de manera magistral. Gertie logra transmitir una personalidad muy definida, gracias a las simples pero muy atractivas animaciones que la caracterizan; logrando una gran expresividad y demostrando el potencial que puede alcanzar una animación bien hecha.
McCay introdujo técnicas de animación innovadoras, como el uso de fotogramas clave o keyframes, así como la reutilización de dibujos, siendo técnicas que influenciaron la forma en la que se crean las animaciones.

A medida que la animación se consolidaba como una forma de expresión, se desarrollaron tecnologías que permitían mejorar y optimizar la creación de animaciones. Una de estas tecnologías es el rotoscopio, un dispositivo que proyecta imágenes en una pantalla para que los animadores puedan utilizarlas como referencia para los cuadros de una animación. El rotoscopio fue inventado por Max Fleischer en 1915 y se utilizó por primera vez en los cortos The Out of the Inkwell de Fleischer.
Al utilizar el rotoscopio, los animadores pueden reproducir movimientos del mundo real en personajes animados, lo que permite crear animaciones con acciones más detalladas y realistas. De hecho, se puede considerar al rotoscopio como el precursor de la tecnología de captura de movimiento moderna, ya que permite ambos se basan en replicar movimientos del mundo real.
Felix el gato es un personaje de animación creado en 1919 por el caricaturista Pat Sullivan y animado por Otto Messmer. Es considerado como uno de los primeros personajes de dibujos animados con personalidad propia y con animaciones que presentaban una trama más elaborada. Siendo la caricatura muda más popular y lucrativa de mediados de 1920.
Felix el gato fue importante para la animación por varias razones. Primero, su popularidad ayudó a consolidar la animación como una forma de entretenimiento en la cultura popular. Además, Felix fue un precursor de los personajes animados con características humanas y con personalidades distintivas. Su diseño simple pero icónico lo convirtió en un símbolo reconocible para la audiencia, lo que inspiró la creación de otros personajes de animación con características similares.

The Lost World es una película estadounidense de aventuras y ciencia ficción, dirigida por Harry O. Hoyt y estrenada en 1925. La película está basada en la novela homónima de Arthur Conan Doyle y cuenta la historia de un grupo de exploradores que viajan a una meseta aislada en Sudamérica donde descubren una tierra perdida en el tiempo habitada por dinosaurios y otros animales prehistóricos.
Uno de los mayores aportes de The Lost World fue su uso pionero de técnicas de animación cuadro a cuadro o stop motion para crear las animaciones de los dinosaurios y otros animales prehistóricos. El animador Willis O'Brien (quien posteriormente trabajó en la película “King Kong”), fue el encargado de crear los modelos animados de los dinosaurios y logró que estos se mezclaran con los actores reales en las escenas de la película. El uso de la técnica de stop motion fue un gran logro técnico en su época y permitió crear animaciones impresionantes.
Esta película ha sido seleccionada para su preservación en el Registro Nacional de Películas (National Film Registry) debido a su gran importancia cultural, histórica y estética. Puede ser vista a través del siguiente enlace:
https://upload.wikimedia.org/wikipedia/commons/2/2e/The_Lost_World_(1925).webm

The Jazz Singer es una película estadounidense de 1927, dirigida por Alan Crosland, que cuenta la historia de un joven llamado Jakie Rabinowitz (interpretado por Al Jolson) que quiere convertirse en cantante de jazz, pero su padre, un rabino ortodoxo, quiere que siga la tradición familiar y se convierta en cantor en la sinagoga. La película explora los conflictos entre el deseo de Jakie de seguir su pasión y su lealtad a su familia y su herencia cultural.
Lo que hace que The Jazz Singer sea una película históricamente importante es que se considera el primer largometraje comercial con sonido sincronizado. Antes de esta producción, el sonido en las películas era incorporado de forma separada, por ejemplo, con orquestas tocando en vivo durante la proyección de la película.

Con The Jazz Singer se utilizó el sistema Vitaphone desarrollado por la compañía Warner Bros. (), que permitía grabar el sonido en discos para ser reproducidos de forma sincronizada con la proyección de la película. El sistema Vitaphone se convirtió en un importante avance en la tecnología del cine sonoro, al permitir la sincronización precisa de la música y el diálogo con la imagen en la pantalla. A partir de aquí, las películas sonoras se fueron convirtiendo poco a poco en la norma de la industria del cine y rápidamente fueron desplazando a las películas mudas.

Steamboat Willie es un corto animado dirigido por Walt Disney y Ub Iwerks, que cuenta la historia de Mickey Mouse, quien trabaja como timonel en un barco de vapor y se enfrenta a situaciones cómicas mientras trata de realizar sus tareas.
Este cortometraje es significativo porque fue el primer corto animado en tener sonido sincronizado, lo que significa que los efectos de sonido y la música se ajustan perfectamente a la animación. En ese momento, la tecnología de sonido en el cine aún estaba en sus primeras etapas, por lo que esta innovación allanó el camino para la incorporación de sonido en las animaciones. La técnica de sincronización de sonido se logró utilizando el sistema de grabación y reproducción de sonido llamado Powers Cinephone, desarrollado por la empresa británica DeForest Phonofilm.

A pesar de ser la tercera animación de Mickey Mouse, se considera su verdadero debut ya que fue la primera vez que se presentó al público con las características que acompañarían al ratón animado en el futuro. Además, fue el primer cortometraje distribuido por Disney que tuvo gran popularidad, lo que ayudó al éxito futuro de la compañía.
En la actualidad, los primeros segundos de este corto se han convertido en parte de la animación de introducción de algunas películas de Disney, como un pequeño guiño a las raíces de la compañía. Y desde el 1 de enero de 2024, después de más de 95 años de su debut, Steamboat Willie entró en el dominio público.
Skeleton Dance es un cortometraje animado producido y dirigido por Walt Disney en el que cuatro esqueletos se levantan de sus tumbas para bailar y jugar en un cementerio. La música y los efectos de sonido, junto con los movimientos divertidos y rítmicos de los personajes, crean una atmósfera alegre y característica del estilo de Disney.
Uno de los aspectos más importantes de Skeleton Dance es que se destacó por ser una de las primeras animaciones que presentó la idea de que la personalidad del personaje es lo que impulsa sus acciones y movimientos. Es decir, más allá de mostrar las capacidades de la tecnología, se enfocó en crear personajes con una personalidad única que conectara con el público.
Skeleton Dance fue el primer corto animado de la serie Silly Symphonies, que fue una colección de cortometrajes musicales producidos por Disney durante los años 30.

El proceso utilizado por Technicolor, de forma simplificada, se basa en la separación de los colores de una imagen por medio de prismas para grabarlos en películas en blanco y negro, que luego pasando por filtros se proyectan de forma simultánea en el cine para obtener una imagen a todo color. Esta técnica revolucionó la producción y consumo de películas al ser la primera en producir imágenes a todo color, y su utilización transformó la industria cinematográfica.
Con el tiempo, las películas en blanco y negro fueron reemplazadas gradualmente por las nuevas películas a todo color, lo que supuso un gran avance tecnológico en el cine. La capacidad de Technicolor para crear películas en color fue crucial para este cambio, y su legado se puede apreciar en las películas actuales que usan tecnologías similares para crear imágenes más vibrantes y realistas.
Con la intención de mantenerse a la vanguardia de la tecnología en la industria cinematográfica, Disney no solo aprovechó la tecnología sonora, sino que también exploró las posibilidades inherentes a las tecnologías emergentes, como fue el uso del color en producciones animadas.
En 1932, Walt Disney Productions produjo Flowers and Trees, un cortometraje animado que se convirtió en la primera película animada en color de la serie Silly Symphonies. Este cortometraje utilizó el proceso Technicolor de tres colores y relata la competencia entre árboles y flores por la atención de una hermosa dama. Es importante mencionar que, Flowers and Trees ganó el primer Premio de la Academia otorgado a un cortometraje animado en color.

El estudio de animación de Disney no sólo utilizaba las tecnologías desarrolladas por otros, sino que también desarrollaron sus propias innovaciones tecnológicas para mejorar sus animaciones y destacar frente a otros estudios de animación.
La cámara multiplano es un mecanismo creado por Disney que permite separar un cuadro de una animación en múltiples planos o capas, lo que proporciona una mayor sensación de profundidad en las tomas y simplifica la producción de composiciones complejas. La importancia de la cámara multiplano radica en que permitió a los animadores de Disney crear escenas más complejas y detalladas que eran visualmente impresionantes y únicas.
Con la cámara multiplano, los animadores podían separar diferentes elementos de una escena en diferentes capas y controlar su movimiento y velocidad individualmente para crear una sensación de profundidad y perspectiva. Además, esta técnica permitió a los animadores agregar detalles más realistas a las escenas, lo que hizo que las animaciones de Disney se destacaran por su belleza y realismo.
Actualmente los programas de dibujo digital, edición de imágenes y de video utilizan este concepto y separan los elementos visuales en diversas capas virtuales, logrando de esta manera aislar los diferentes elementos que componen una imagen y así permitir su edición de forma independiente.
La película King Kong cuenta la historia de un gorila gigante que vive en una isla remota y que es capturado y llevado a la ciudad de Nueva York, donde se libera y comienza a causar destrozos subiendo al Empire State llevando a ser atacado para que al final caiga del edificio y muera. Es considerada un hito en la historia del cine debido a que los efectos especiales realizados por O'Brien fueron innovadoras para la animación e influyeron en la industria durante varias décadas.

Los escenarios de la isla de Kong se crearon utilizando modelos en miniatura y proyecciones en pantalla, mientras que los efectos especiales de los animales de la isla se crearon por medio de animación stop motion. Para las escenas en las que King Kong interactuaba con actores humanos, estas se filmaron por separado y luego se combinaron en postproducción. La película fue filmada en blanco y negro y se utilizó música y efectos de sonido para aumentar el drama.
La creación de King Kong fue un gran logro técnico y artístico y ha dejado un legado en la historia del cine, ya que en gran medida, determinó diversas técnicas que se siguen utilizando hoy en día en la animación hecha por stop motion, como por ejemplo, el uso de marionetas con un esqueleto metálico con el que se logran diversas poses de los personajes, así como la combinación de imágenes del mundo real con los personajes animados.
La computadora Z1, diseñada por el ingeniero alemán Konrad Zuse, fue una de las primeras computadoras electromecánicas programables en el mundo. A pesar de su diseño mecánico la Z1 incluía muchos componentes que se encuentran en las computadoras modernas, como memoria, operaciones de punto flotante, dispositivos de entrada y salida, así como una unidad central de procesamiento o unidad de control. Además, la Z1 utilizaba una cinta de película perforada para proporcionar instrucciones al sistema, lo que la convierte en una de las primeras computadoras programables. En esencia, esta máquina permitía realizar cálculos complejos y estaba diseñada para ejecutar cálculos estadísticos, así como funciones de matemáticas e ingeniería.
Desafortunadamente, la computadora Z1 no se construyó completamente antes del inicio de la Segunda Guerra Mundial y fue dañada durante un ataque aéreo en 1943. A pesar de esto, se continuó trabajando en el diseño de computadoras y eventualmente Zuse creó otras máquinas, como la Z2 y la Z3, que fueron versiones mejoradas de la Z1 y utilizadas en aplicaciones militares durante la guerra.

Durante la Segunda Guerra Mundial, la máquina de cifrado Lorenz era utilizada por las fuerzas alemanas para comunicarse con sus fuerzas en el campo de batalla. El cifrado era tan complejo que los expertos en criptografía de los aliados no podían descifrar los mensajes. Para enfrentar este desafío, un equipo de ingenieros liderado por el matemático y científico de la computación Alan Turing, en la base secreta de Bletchley Park, Inglaterra, desarrolló la primera computadora digital electrónica programable de propósito especial del mundo: la computadora Colossus.
La Colossus se basó en la tecnología de tubos de vacío y su capacidad de procesamiento superó con creces a las máquinas electromecánicas anteriores utilizadas para la criptografía. Fue capaz de procesar grandes cantidades de información y descifrar mensajes en minutos, lo que antes llevaba días o incluso semanas.
A través de su innovadora tecnología de computación digital, Colossus pudo resolver problemas matemáticos y lógicos extremadamente complejos de manera más rápida y eficiente que cualquier otra máquina anterior.
El uso de la computadora Colossus se mantuvo en secreto durante muchos años después del fin de la Segunda Guerra Mundial, pero finalmente se reveló al público. La creación y uso de Colossus en la guerra ha sido acreditada como una contribución significativa a la victoria de los aliados, ya que permitió descifrar mensajes enemigos y anticipar sus movimientos, permitiendo que los aliados tomarán medidas para frustrar los planes del enemigo y ganar ventaja en el campo de batalla.



Tennis for two es un videojuego pionero creado por el físico estadounidense William Higinbotham en 1958.
El juego se considera una de las primeras incursiones en la creación de videojuegos y es conocido por utilizar un osciloscopio para dibujar sus gráficos. Un osciloscopio es una pantalla que se utiliza para medir la amplitud de las señales eléctricas, y en este caso se utilizó para mostrar una vista lateral de una cancha de tenis en la que los jugadores interactuaban con una pelota de luz mediante un control mecánico sencillo.


La secuencia de créditos de la película Vértigo es una animación icónica en la historia del cine y la animación por computadora. Fue creada por John Whitney utilizando una computadora antiaérea de la Segunda Guerra Mundial y una plataforma giratoria con un péndulo colgando sobre ella ().


Para crear los elementos en espiral que aparecen en la secuencia, Whitney programó la computadora para generar patrones matemáticos y geométricos que se combinaron para crear la animación. Estos patrones incluyen formas en espiral, líneas curvas y círculos concéntricos.
La secuencia se considera la primera animación por computadora utilizada en un largometraje.

William Fetter fue un diseñador gráfico e industrial, pionero en el campo de la graficación por computadora. Durante la década de 1960, trabajó en la compañía de aviones Boeing, donde creó el primer modelo 3D de una persona: el Boeing man. Este modelo se utilizó para diseñar cabinas de aviones y mejorar la ergonomía de los asientos.
Fetter es reconocido por haber acuñado el término “Computer Graphics” el cual utilizó para referirse a su trabajo.
Catalog es una animación experimental generada por computadora, creada por John Whitney, el mismo que estuvo a cargo de los créditos de la película Vértigo. La animación presenta patrones abstractos que cambian y se mueven al ritmo de la música, todo ello realizado mediante el uso de la computadora analógica mecánica que construyó.

Es importante destacar que Catalog fue una recopilación (o catalogo) de los efectos visuales que Whitney había generado previamente.
Spacewar! es un videojuego de acción espacial en 2D desarrollado por Steve Russell en colaboración con Martin Graetz, Wayne Wiitanen, Bob Saunders, Steve Piner y otros, para el Programa de Modelado Avanzado del Massachusetts Institute of Technology (MIT).
El juego enfrenta a dos jugadores, cada uno controlando una nave espacial, con el objetivo de destruir la nave del oponente mientras se evita colisionar con los planetas y estrellas del fondo. Spacewar! es considerado por muchos como el primer videojuego de la historia.
Sensorama fue el primer sistema de realidad virtual inmersivo, imaginado y descrito en papel en 1956 por Morton Heiling (). No fue hasta 1962 que se desarrolló un prototipo en el que se exhibían 6 películas cortas. El objetivo de Sensorama era crear una experiencia de cine completamente inmersiva, que incluyera no solo imágenes en movimiento, sino también sonido, olor, vibraciones y simulación de viento. El dispositivo tenía una pantalla estereoscópica que mostraba imágenes en 3D, altavoces, ventiladores, dispositivos de olor y vibración para estimular todos los sentidos, y un asiento con movimiento para crear una experiencia aún más inmersiva ().
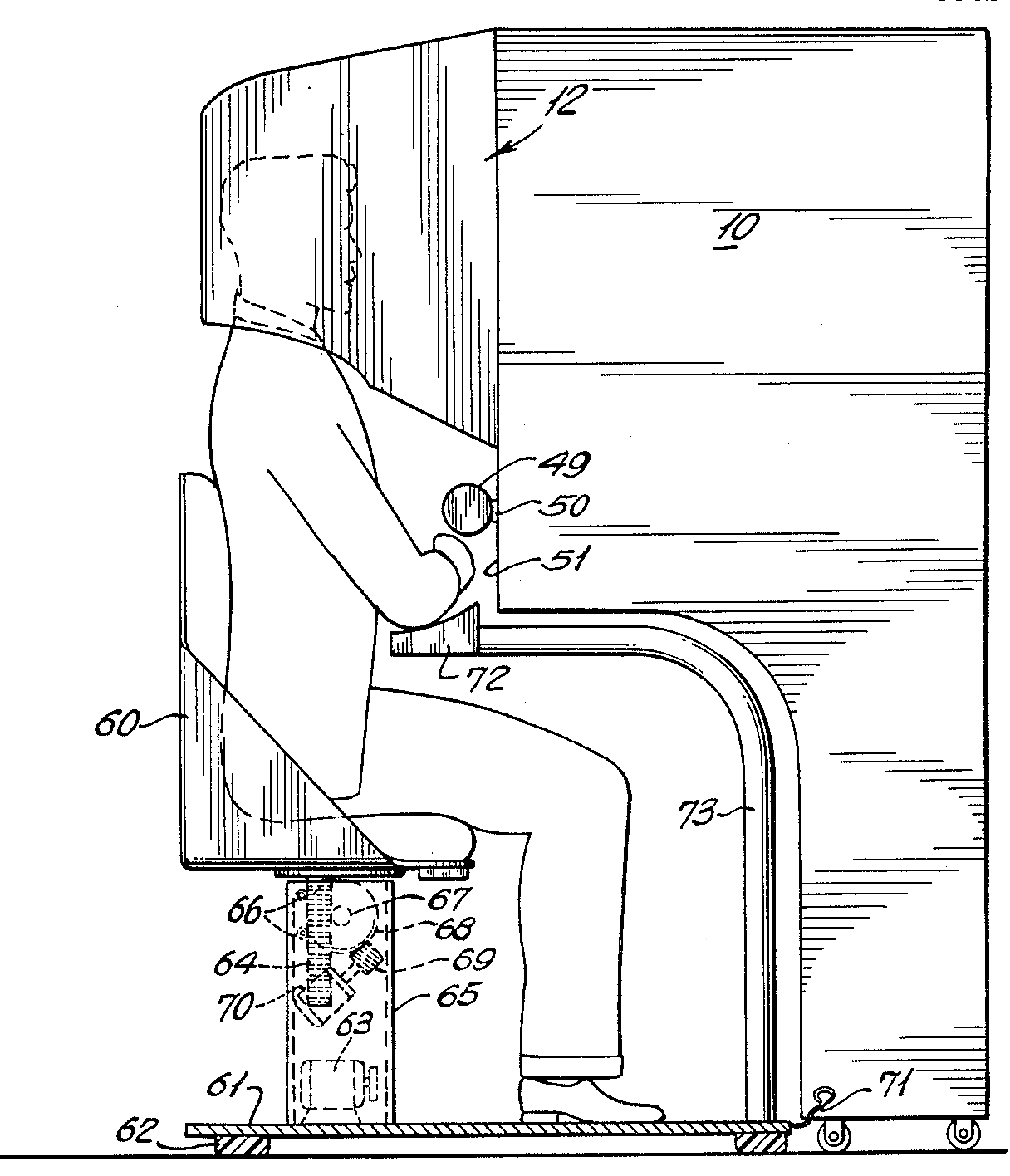

Heiling creía que su sistema Sensorama sería el futuro del cine y que eventualmente se convertiría en una forma popular de entretenimiento. A pesar de que la tecnología fue revolucionaria para su época, no tuvo éxito comercial y nunca llegó a ser adoptada por el público en general, por lo que solo se construyeron unas pocas unidades.
En gran manera Sensorama fue el precursor de los sistemas de realidad virtual actuales y ejerció una influencia positiva en el desarrollo de los ambientes virtuales y las experiencias multisensoriales inmersivas.

Sketchpad es un programa de computadora desarrollado por Ivan Sutherland en el Laboratorio Lincoln del Massachusetts Institute of Technology (MIT). Es considerado un programa pionero en la interacción humano computadora (Human Computer Interaction, HCI) y el ancestro de los sistemas de diseño asistido por computadora (Computer Aided Design, CAD). Permitió a los usuarios crear dibujos y diseños mediante una pantalla de computadora y un lápiz óptico (común en esa época), y presentaba innovaciones técnicas como la manipulación y visualización de objetos en 3D en tiempo real.
El programa fue diseñado como tesis doctoral de Sutherland y proporcionó diversos conceptos útiles para la interacción con las computadoras mediante elementos figurativos interactivos. Además, este trabajo ha sido reconocido con varios premios y honores, incluido el Premio Turing en 1988, considerado el equivalente al Premio Nobel de la informática.

El primer ratón de computadora fue creado por Douglas C. Engelbart y se trata de un dispositivo rudimentario con una estructura principal de madera y dos ruedas metálicas en la parte inferior que se movían perpendicularmente y que se conectaba a la computadora mediante un cable. Engelbart buscaba una forma más eficiente de interactuar con la computadora, ya que los métodos previos, como los joysticks o los lápices de luz, resultaban poco precisos o incómodos.
Inicialmente, este dispositivo no gozó de gran popularidad, pero su creación sentó las bases para una nueva manera de interactuar con la computadora. Con la introducción de las interfaces gráficas en la computación, el ratón de computadora se convirtió en un dispositivo fundamental para la navegación en pantalla, permitiendo una interacción mucho más sencilla, precisa y eficiente.

Hummingbird es una animación digital creada por Chuck Csuri utilizando un programa de gráficos por computadora que él mismo desarrolló.
La animación presenta la imagen de un colibrí doblando y separándose, y fue realizada mediante la técnica de interpolación de movimiento y el uso de keyframes. Sorprendentemente, esta animación está compuesta por más de 30,000 imágenes individuales, lo cual son muchos elementos gráficos para la época en la que se desarrollo.

El sombreado de Gouraud es un método de iluminación utilizado en gráficos 3D que fue desarrollado por Henri Gouraud en 1971. Este método permite representar superficies curvas de una manera más suave y realista. Básicamente, lo que hace es calcular la intensidad de la luz en cada vértice de un objeto 3D y luego interpolar esos valores suavemente en toda la superficie del objeto, logrando una apariencia más homogénea.
Antes del sombreado de Gouraud, los objetos en gráficos 3D se representaban utilizando modelos dibujados por líneas (wireframe) o con colores completamente sólidos mediante el sombreado plano (flat shading), sin embargo, estos métodos no lograban representar de manera realista la apariencia de objetos curvos, ya que en las superficies se notaban los polígonos planos que las componían.
Esta técnica de sombreado fue un avance significativo en el campo de la generación de gráficos 3D por computadora, ya que permitió la creación de imágenes más realistas y detalladas en comparación con las técnicas anteriores.
Pong es uno de los primeros videojuegos de arcade, fue creado por el ingeniero y empresario Nolan Bushnell, y el diseñador de videojuegos Allan Alcorn para su compañía Atari.
El juego recrea el tenis de mesa en un plano cenital (visto desde arriba), con dos paletas que se mueven hacia arriba y hacia abajo en la pantalla, y una pelota que rebota al golpear las paredes superior e inferior y las paletas. El objetivo del juego es que cada jugador trate de hacer pasar la pelota por detrás de la paleta del oponente para anotar un punto, y el jugador con más puntos al final del juego gana.
Pong fue un éxito inmediato y se considera el primer videojuego comercial exitoso, y su popularidad ayudó a establecer la industria de los videojuegos tal como la conocemos hoy en día.

A Computer Animated Hand es un cortometraje creado por Ed Catmull en 1972, quien fue un pionero en la animación generada por computadora y uno de los fundadores de Pixar. Catmull hizo este cortometraje mientras estudiaba su posgrado en la Universidad de Utah. El corto tiene una duración de un minuto y muestra una mano humana tridimensional que se mueve y dobla de manera realista.
Para hacer el cortometraje, Catmull y sus colegas desarrollaron un sistema para crear el modelo de la mano y luego programar el movimiento de los dedos y la articulación. Este corto representa el primer intento exitoso de animar una mano humana en 3D.

El modelo de reflexión de Phong es un modelo de iluminación que se utiliza para dar apariencia realista a objetos con superficies reflectantes. Este modelo fue creado por el científico de la computación Bui Tuong Phong, mientras estudiaba su posgrado en la Universidad de Utah.
El modelo de Phong se basa en tres tipos de reflexión de la luz, a saber: la reflexión ambiental, la reflexión difusa y la reflexión especular. Siendo la reflexión ambiental la luz indirecta que se dispersa por toda la escena; la reflexión difusa es la luz que se refleja uniformemente en todas las direcciones al interactuar con una superficie rugosa; y la reflexión especular es la luz que se refleja ordenadamente en una dirección privilegiada al interactuar con una superficie lisa. Para calcular el color final de un píxel en la pantalla, el modelo de reflexión de Phong utiliza una fórmula matemática que combina estos tres tipos de reflexiones.
Talking face es un cortometraje de animación de un minuto de duración, que fue creado en 1974 por Frederic Parke, un artista y animador. Es una de las primeras animaciones en 3D que presenta una cabeza humana hablando y sincronizando los movimientos de la boca con el habla. El cortometraje utiliza un modelo paramétrico de una cabeza humana que muestra varias expresiones faciales y sincronización de labios, lo que se conoce como lipsync.

Parke además de crear esta animación, continuó haciendo contribuciones importantes en el campo de la graficación y animación por computadora, y se convirtió en profesor de la Universidad de Texas en Austin.
El búfer de profundidad o Z-buffer es una técnica utilizada en graficación por computadora que permite determinar qué elementos de una escena 3D son visibles por la cámara o espectador. Fue creado en 1974 por Ed Catmull mientras trabajaba en la Universidad de Utah.
El búfer de profundidad utiliza una área en memoria en el que se asigna un valor de profundidad (también llamado valor Z) a cada píxel que se va a dibujar en la pantalla. Este valor indica la distancia que hay entre el espectador y el píxel que se quiere dibujar, y se utiliza para determinar qué objetos están en primer plano y cuáles están detrás, permitiendo descartar píxeles que no son visibles (). Al utilizar el búfer de profundidad es posible dibujar escenas 3D complejas de forma rápida y eficiente, sin tener que realizar cálculos como la intersección o el ordenamiento de los objetos que componen una escena.
Esta técnica tuvo una influencia significativa en el desarrollo posterior de las tarjetas de video, así como en las técnicas para dibujar mallas poligonales de forma eficiente mediante la aceleración gráfica, que de hecho, determinó en gran medida la forma en que evolucionó la tecnología de las tarjetas de video, ya que su uso permite paralelizar el procesamiento de cada polígono que se dibuja, sin importar el orden en que aparezcan en la imagen final, lo que se utiliza ampliamente en las unidades de procesamiento gráfico de las tarjetas de video actuales.


El mapeo de texturas es una técnica utilizada en gráficos por computadora para dar mayor detalle y realismo a superficies tridimensionales. Fue desarrollada por Ed Catmull mientras trabajaba en la Universidad de Utah.
La técnica consiste en aplicar una imagen bidimensional (una textura) a una superficie tridimensional en una escena 3D, lo que permite crear superficies con una apariencia más detallada y realista sin aumentar la cantidad de información geometría. Esto se logra al asignar coordenadas de textura a cada vértice del objeto 3D, lo que permite mapear cada punto en una superficie a un punto correspondiente en una imagen 2D ().
Actualmente, el mapeo de texturas se combina con materiales realistas y texturas de gran calidad, lo que permite crear objetos tridimensionales con un realismo sin precedentes. Esto ha sido especialmente importante en el campo de los videojuegos y el cine, donde se busca crear mundos y personajes que parezcan reales para el espectador.
En el sitio web del Museo Smithsoniano de Arte Americano se pueden encontrar diversos objetos tridimensionales, que fueron creados a partir del escaneo de objetos reales, y presentan texturas realistas y con los que se puede interactuar directamente en un navegador de internet, por ejemplo, en la se muestra el traje espacial de Neil Armstrong.

El antialiasing también conocido como antiescalonamiento, es una técnica utilizada para suavizar los bordes dentados o escalonados que aparecen en las imágenes generadas por computadora. Fue creado por Ed Catmull en 1974, mientras trabajaba en la Universidad de Utah.
La técnica funciona generando píxeles de colores intermedios cerca de los bordes de los objetos mediante el muestreo de múltiples puntos en un área pequeña alrededor de cada píxel. De esta manera, se obtiene una apariencia suavizada en los bordes, reduciendo los escalones o dientes que se forman en las líneas diagonales o curvas.

La tetera de Utah es un modelo tridimensional creado para probar técnicas de iluminación, sombras, color y texturas. Este modelo fue generado por Martin Newell a partir del mapeo de las coordenadas de una tetera real, lo que permitió crear un modelo de alambre tridimensional con gran fidelidad.
El año 1975 marcó la fundación de la empresa Microsoft, cuyo objetivo principal era desarrollar y comercializar software para computadoras personales.
En sus inicios, la compañía se centró en el desarrollo del lenguaje de programación Basic.

La película Futureworld es una obra de ciencia ficción estrenada en 1976 y dirigida por Richard T. Heffron, esta cinta es una secuela de la película Westworld estrenada en 1973, y sigue a dos periodistas que investigan un parque temático futurista y los percances que ocurren en él.
Lo importante de esta película para la animación por computadora es que en unas breves escenas se muestran los modelos 3D de la mano y la cabeza, que fueron creados por Ed Catmull y Fred Parke, lo que le dió visibilidad a su trabajo.

En 1976, Steve Wozniak diseñó y construyó la primera computadora personal de Apple, conocida como Apple I. La máquina fue construida en su garaje, con la ayuda de Steve Jobs, quien fue responsable de la comercialización y venta de la computadora.
La Apple I es considerada una de las primeras computadoras personales asequibles para el consumidor promedio. Contaba con una memoria RAM estándar de 4 KB, que podía ser actualizada a 8 KB o 48 KB, un procesador MOS Technology 6502 de 1 MHz, y una ROM de 256 bytes que alojaba el programa de control para la interfaz de video. Gracias a esta última, los usuarios podían conectar la computadora a una televisión. Aunque en comparación con las computadoras modernas no era muy potente, la Apple I fue un gran éxito y se vendieron alrededor de 200 unidades.

Los procesadores 8086 y 8088 fueron de los primeros microprocesadores de 16 bits creados por Intel. El procesador 8088 fue utilizado por IBM en su primera computadora, ya que era una versión del 8086 con un bus de datos reducido a 8 bits.
Estos procesadores son los fundadores de la arquitectura x86, y el conjunto de instrucciones definido en ellos todavía se utiliza hoy en día en diversos sistemas, aunque cada vez se encuentra más en desuso. La importancia de estos procesadores radica en que ofrecían una buena potencia a un precio asequible, lo que impulsó el auge de las computadoras personales de IBM, llegando a hogares y escuelas.

El mapeado topológico o bump mapping es una técnica de renderizado que permite crear la ilusión de texturas rugosas o con relieve en una superficie, esto sin tener que especificar cada detalle individualmente.
La idea detrás del bump mapping consiste en utilizar una textura, usualmente en escala de grises, para simular los relieves y detalles de la superficie, lo que a su vez crea sombras y reflejos que dan la ilusión de profundidad. Los tonos grises de la textura corresponden a desplazamientos en la altura de la superficie, lo que se utiliza para simular las perturbaciones de los vértices y las normales de un objeto 3D.
El trazado de rayos o raytracing es una técnica que simula en una computadora el comportamiento de la luz en el mundo real. Funciona enviando un rayo de luz virtual desde la cámara a través de cada píxel de la imagen, y rastreando su camino a medida que interactúa con los objetos de la escena, de esta forma, el rayo se refleja y refracta al encontrarse con diferentes materiales y superficies. Cada rayo de luz virtual calcula el color y la intensidad de la luz en el punto donde impacta con los objetos de la escena, lo que permite crear sombras, reflejos y refracciones precisos y realistas.

Aunque con el trazado de rayos se pueden generar imágenes realistas, hay que mencionar que el proceso puede ser muy costoso en términos de tiempo y recursos computacionales, ya que se requiere el cálculo de un gran número de rayos de luz para generar una imagen de alta resolución.
MS-DOS (MicroSoft Disk Operating System) es un sistema operativo desarrollado por Microsoft Corporation y lanzado en 1981. Fue uno de los primeros sistemas operativos populares para computadoras personales IBM y compatibles, y se convirtió en el sistema operativo dominante para PC durante gran parte de la década de 1980 y principios de la década de 1990. Aunque MS-DOS carecía de muchas de las características modernas de los sistemas operativos, como una interfaz gráfica de usuario (GUI), soporte de red y multitarea, fue un sistema operativo muy eficiente y confiable que proporcionaba un control total sobre el hardware de la computadora.
MS-DOS utilizaba una interfaz de usuario basada en texto o línea de comandos y fue diseñado para ser utilizado en computadoras con procesadores Intel x86. Cabe destacar que posteriormente fue la base del sistema operativo Windows, ya que las primeras versiones de Windows se ejecutaban como un programa sobre MS-DOS. Windows 95 y posteriores versiones incluyeron una interfaz gráfica de usuario completa y características de red y multitarea, lo que hizo que MS-DOS se volviera obsoleto. Sin embargo, aún es posible encontrar vestigios de este sistema en la línea de comandos de Windows (CMD, ).
Silicon Graphics Inc. (SGI) fue una compañía de tecnología estadounidense fundada en 1982 que se especializó en la fabricación de computadoras y software para gráficos y visualización en 3D; y fue una de las empresas líderes durante las décadas de 1980 y 1990.
La compañía fue fundada por Jim Clark y otros miembros de la Universidad de Stanford. En 1984, SGI lanzó su primera estación de trabajo gráfica, conocida como IRIS, diseñada para el mercado de la animación y el diseño asistido por computadora; este equipo utilizó una arquitectura de procesamiento de gráficos altamente avanzada para su época, lo que permitió a los usuarios generar visualizaciones en 3D en tiempo real. SGI también desarrolló la biblioteca IrisGL (Integrated Raster Imaging System Graphics Library), que proporcionaba un API para la creación de gráficos 3D de alto rendimiento en su plataforma de estaciones de trabajo IRIS. IrisGL se convirtió en un estándar para el desarrollo de aplicaciones gráficas en 3D y fue muy influyente en el desarrollo de la industria de la animación y los efectos visuales, además es la precursora de OpenGL, siendo esta última todavía utilizada en la actualidad.
Sin embargo, a medida que la competencia en el mercado de la computación gráfica se intensificó en la década de 1990, SGI comenzó a tener dificultades financieras y perdió su posición dominante en la industria. La compañía finalmente se declaró en bancarrota en 2009 y vendió sus activos a diferentes compradores. A pesar de su eventual caída, SGI dejó una huella importante en la historia de la computación gráfica y la visualización en 3D. Sus innovaciones y tecnologías de vanguardia sentaron las bases para la evolución continua de la industria, y su legado sigue influyendo en los campos de la animación, los efectos visuales, la visualización y los videojuegos.
.jpg)
Autodesk es una empresa de software estadounidense fundada en 1982 por John Walker y otros programadores, con el objetivo de desarrollar software de diseño y gráficos asistido por computadora (CAD).
Uno de sus primeros productos fue AutoCAD, un programa de diseño que se convirtió en el estándar de facto en la industria de la arquitectura, ingeniería y construcción. Lanzado en 1982, revolucionó la forma en que se realizaba el diseño asistido por computadora en la industria de la construcción y la arquitectura. Antes de AutoCAD, el diseño de planos y dibujos técnicos se realizaba con papel y tinta, pero con AutoCAD, los usuarios podían crear y editar diseños en una computadora utilizando herramientas de dibujo y comandos de texto. Su facilidad de uso, potencia y versatilidad hicieron que el programa fuera muy popular y permitió a los usuarios crear dibujos precisos y detallados en 2D y 3D, así como generar documentos de alta calidad para la construcción y la fabricación.
.jpg)
Actualmente, Autodesk es una de las empresas más influyentes y fuertes en el ámbito de las herramientas para la creación de gráficos y animación por computadora en todo el mundo.
Con el desarrollo de la tecnología y la mejora en las técnicas de renderizado, la animación por computadora se fue convirtiendo en una herramienta ampliamente utilizada en las producciones cinematográficas.
Uno de los primeros largometrajes que se destacó por su uso de gráficos generados por computadora fue Tron. Esta película, estrenada en 1982, utilizó tecnología de punta para crear un universo virtual completamente nuevo, lleno de efectos visuales y un estilo de animación singular. Tron combina gráficos generados por computadora con escenas de acción en vivo, lo que la convierte en una experiencia cinematográfica única. Además, es conocida por presentar al primer personaje generado por computadora que habla: el icónico villano de la historia, el Master Control Program.

Wavefront Technologies fue una empresa estadounidense de software de animación y efectos visuales fundada en 1984 en Santa Bárbara, California. Fue una de las primeras empresas en desarrollar software especializado para la creación de gráficas y animaciones en 3D, convirtiéndose en líder en la industria de efectos visuales para cine y televisión. Su primer producto Advanced Visualizer lanzado en 1985, permitió a los animadores crear y renderizar animaciones en 3D con una calidad visual impresionante para su época, lo que la convirtió en una herramienta popular para la producción de efectos visuales en películas y series de televisión.
Wavefront Technologies también fue pionera en el desarrollo de técnicas de animación basadas en física y simulación, como la simulación de partículas y dinámica de fluidos, lo que ofreció a los animadores la posibilidad de crear efectos como explosiones, fuego y agua, de forma realista. Además, fue la responsable de la creación del software de animación Maya, ampliamente utilizado en la industria cinematográfica.

The Adventures of André and Wally B. es un cortometraje desarrollado por el grupo gráfico de Lucasfilm en 1984. La animación muestra a un personaje llamado André, quien al despertar en el bosque se encuentra con un abejorro llamado Wally B. que lo persigue.
Es importante destacar que los responsables del desarrollo de esta animación fundaron la compañía Pixar en 1986, después de separarse de Lucasfilm. Por esta razón algunos consideran que este cortometraje es el primer corto animado creado por Pixar.

La primera versión de Microsoft Windows, conocida como Windows 1.0, fue lanzada en noviembre de 1985. Este sistema operativo de 16 bits utilizaba interfaces gráficas similares a las del sistema operativo Macintosh de Apple y estaba diseñado para funcionar con los procesadores Intel 8086 y 8088.
Hay que mencionar que esta primera versión tenía algunas limitaciones, como la capacidad de tener solo una ventana abierta a la vez, lo que limitaba su capacidad multitarea, aún así el sistema operativo incluía una serie de aplicaciones básicas preinstaladas, como un editor de texto, una calculadora, un calendario, entre otras, que lo volvían un sistema útil.
La película The Great Mouse Detective de Disney presenta una escena de persecución en el Big Ben de Londres, en la cual se utilizaron modelos tridimensionales y una técnica conocida como cel shading o toon shading para mezclar las imágenes generadas por computadora con los dibujos hechos a mano. Los animadores Phil Nibbelink y Tad Gielow invirtieron meses en diseñar el interior del Big Ben, creando cada engranaje mediante gráficos en alambre (wireframe) en una computadora. Luego, imprimieron y dibujaron estos diseños en células de animación, a las que se les agregaron los colores y los personajes principales.
Esta escena de alrededor de dos minutos presenta imágenes generadas por computadora mezcladas con dibujos, lo que la convierte en la primera película de Disney en utilizar esta tecnología; logro que fue utilizado para promocionar la película durante su lanzamiento.

El cortometraje Luxo Jr. es uno de los primeros trabajos de Pixar Animation Studios, y es conocido por ser el cortometraje que presentó a la mascota de Pixar, la lámpara llamada Luxo Jr. Este cortometraje, dirigido por John Lasseter, fue lanzado en 1986 y fue el primer trabajo de animación por computadora en ser nominado al premio Óscar en la categoría de mejor cortometraje animado. Aunque no logró ganar, sí recibió el premio a la animación asistida por computadora de la World Animation Celebration.
La trama del cortometraje es sencilla: se presentan dos lámparas, una grande y otra pequeña, y la lámpara pequeña juega con una pelota como si fuera un niño, mientras se muestran las reacciones de la lámpara grande.
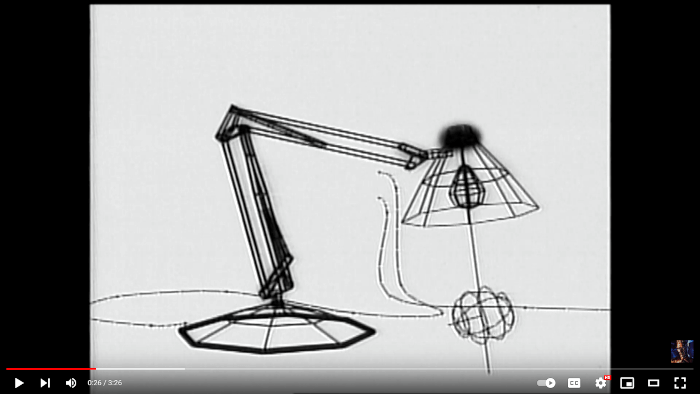
Tin Toy es un corto de animación por computadora producido por Pixar en 1988 y dirigido por John Lasseter, quien también dirigió Luxo Jr. el año anterior, donde se puso a prueba el software de renderizado Renderman para la generación de las imágenes del corto.
La trama de Tin Toy se centra en un pequeño juguete musical hecho de hojalata que trata de escapar de las manos de un bebé humano que lo persigue para jugar con él. Cabe mencionar que fue el primer trabajo de animación por computadora en ganar un premio Óscar en la categoría de mejor cortometraje animado; además, sirvió como inspiración para la película Toy Story y estableció la animación por computadora como un medio artístico legítimo.

Knick Knack es otra producción de Pixar que ganó el premio al mejor corto en el festival internacional de Seattle. La trama se centra en un muñeco de nieve que está atrapado dentro de una esfera de cristal y quiere escapar para ir a un ambiente con objetos y alegorías del verano.
La versión original de la animación fue presentada en 3D en SIGGRAPH (Special Interest Group on Computer Graphics and Interactive Techniques), que es el grupo de estudio y desarrollo de gráficas por computadora más importante a nivel mundial, y así mismo apareció en los cines durante el inicio de la película Buscando a Nemo en el 2003.

La primera versión de 3D Studio se creó para la plataforma DOS por el equipo Yost, y posteriormente fue publicada por Autodesk. Este software fue diseñado con el objetivo de facilitar la producción de películas y efectos especiales mediante la generación de animaciones y gráficos tridimensionales. Ofrecía herramientas fundamentales para la creación de modelos 3D, como la posibilidad de crear y editar polígonos, aplicar texturas y materiales a los mismos, además de permitir la creación e edición de animaciones, cámaras y luces.
Con el paso del tiempo, 3D Studio fue renombrado como 3D Studio Max y en la actualidad se le conoce simplemente como 3ds Max, siendo una herramienta ampliamente utilizada en el desarrollo de videojuegos, la creación de anuncios televisivos, arquitectura y películas.


Terminator 2 es una película de acción y ciencia ficción dirigida por James Cameron y estrenada en 1991. Destacó por sus efectos fotorrealistas avanzados, en especial por el personaje del T-1000, un androide interpretado por Robert Patrick hecho de metal líquido capaz de transformarse en cualquier forma u objeto. Para crear los efectos de transformación, la compañía de efectos especiales Industrial Light and Magic (ILM) de George Lucas, utilizó una combinación de técnicas de modelado en 3D, animación por computadora y captura de movimiento. Los animadores emplearon modelos físicos como referencia para crear animaciones precisas del personaje, incluyendo los efectos de deformación y transformación.
Durante este período de tiempo, la graficación por computadora es capaz de representar de manera realista elementos como el metal o el plástico, pero aún no es completamente confiable en la creación de materiales más orgánicos o naturales. Aún así, con el paso del tiempo, las técnicas de generación de imágenes por computadora comienzan a desplazar el uso de los efectos especiales físicos (o prácticos), como maquetas o marionetas, que se empleaban en el pasado.


Jurassic Park es una película de ciencia ficción y aventuras dirigida por Steven Spielberg que se estreno en 1993.
La película utilizó una combinación de técnicas de animación por computadora y efectos prácticos, como marionetas y robots animatrónicos, para crear los dinosaurios de la película. Los animadores de la compañía Industrial Light & Magic (ILM) de George Lucas crearon modelos en 3D de los dinosaurios utilizando software de animación por computadora como Softimage y RenderMan. Estos modelos se integraron con las tomas de acción en vivo utilizando técnicas de composición digital, lo que resultó en una serie de escenas realistas que mostraban dinosaurios con una calidad y un detalle nunca antes vistos en una película.
Hay que mencionar que aunque muchos de los dinosaurios fueron creados por medio de animación por computadora, para primeros planos donde los dinosaurios se mostraban a detalle en la pantalla, se utilizaban dinosaurios animatrónicos para que se vieran más reales.


ReBoot es una serie animada por computadora que se emitió desde 1994 hasta 2001. Fue producida por Mainframe Entertainment y creada por Gavin Blair, Ian Pearson, Phil Mitchell y John Grace; los gráficos fueron diseñados por Brendan McCarthy.
La trama tiene lugar en Mainframe, un mundo de computadora en el que los personajes principales son guardianes que protegen el mundo de los virus y otros peligros. La serie se caracterizó por tener una narrativa compleja y un diseño de producción innovador para la época, con personajes detallados y escenarios vívidos generados por computadora; así mismo se destacó por ser una de las primeras en ser generadas completamente por computadora.
Cabe mencionar que la idea y el concepto de la serie surgieron diez años antes de su lanzamiento en 1984, pero la producción no comenzó hasta 1990 debido a que la tecnología detrás de la animación por computadora no era lo suficientemente avanzada en ese momento.


El Sony PlayStation fue una consola de videojuegos lanzada en 1994 y la primera de Sony. Antes de esto, la compañía se había asociado con Nintendo para crear una unidad de CD-ROM para la consola Super Nintendo Entertainment System (SNES), pero la colaboración entre ambas empresas fracasó.
La PlayStation fue una de las primeras consolas de videojuegos en utilizar discos ópticos en lugar de cartuchos, lo que permitió una mayor capacidad de almacenamiento y la inclusión de secuencias de video y audio de alta calidad en los juegos. Además, presentó un procesador de 32 bits, lo que permitió una mayor capacidad de procesamiento y gráficos más avanzados que las consolas de la generación anterior. También popularizó el uso de gráficos 3D en los videojuegos caseros, a pesar de que en ese momento todavía eran rudimentarios, utilizando diversas técnicas logró presentar mundos tridimensionales complejos, en una sociedad donde los videojuegos consumidos consistían principalmente en juegos 2D en consolas y algunos juegos en 3D en arcades.


Toy Story es la primera película generada por computadora desarrollada por Pixar Animation Studios. La producción de la película tomó alrededor de 4 años, durante los cuales se utilizaron cerca de 300 procesadores para generar las 112,000 imágenes que la conforman. Para crear las imágenes de la película, se utilizó la herramienta RenderMan (https://renderman.pixar.com/), un motor de renderizado desarrollado por Pixar que se utiliza para crear gráficos en 3D en películas, animación y efectos especiales. Este software utiliza principalmente la técnica de renderizado por raytracing y algoritmos avanzados para simular la interacción de la luz con los objetos en una escena en 3D, lo que permitió a los artistas crear imágenes de alta calidad con sombras, reflejos, texturas y efectos de luz complejos. Actualmente, RenderMan sigue siendo utilizado en las diversas producciones animadas de Pixar.
De forma general, la historia gira en torno a Woody, un juguete que es el favorito de un humano llamado Andy, pero tiene que enfrentarse al desafío de perder su posición y ser reemplazado por un nuevo juguete, Buzz Lightyear.

OpenGL es una biblioteca de gráficos 3D multiplataforma y de código abierto, desarrollada por Silicon Graphics en 1992. Debido a su compatibilidad con múltiples sistemas operativos y tarjetas gráficas, OpenGL se ha convertido en una de las bibliotecas de gráficos más populares en la industria de los videojuegos, la animación y los efectos visuales.
Esta biblioteca proporciona una API de bajo nivel para el desarrollo de aplicaciones gráficas en 3D, lo que permite un control preciso sobre el hardware de la computadora y ofrece una gran flexibilidad en el desarrollo de aplicaciones. En 1992, se creó el OpenGL Architecture Review Board (OpenGL ARB), un conjunto de compañías encargadas de definir y mantener la especificación de OpenGL. Sin embargo, en julio de 2006, la OpenGL ARB transfirió el control de la especificación de OpenGL al grupo Khronos (https://www.khronos.org/opengl/), que es el encargado de mantener la API.
Doom es un videojuego de disparos en primera persona lanzado en 1993 por la compañía Id Software. Es considerado uno de los videojuegos más influyentes de la historia gracias a sus gráficos detallados, efectos de iluminación dinámicos y mundos virtuales en 3D que, aunque simples, ayudaron a popularizar la idea de que el 3D sería el futuro de los videojuegos.
En Doom, el jugador asume el papel de un marine espacial que debe luchar contra hordas de demonios y criaturas alienígenas en una base de investigación en Marte. El juego se desarrolla en una serie de niveles que incluyen pasillos, habitaciones y áreas exteriores, todos creados con gráficos por computadora y efectos de iluminación.
En 1997 su código fuente fue liberado, lo que permitió a muchos estudios de desarrollo de videojuegos revisarlo y generar juegos similares, lo que abrió el camino al desarrollo de videojuegos en primera persona. Se dice en internet que Doom puede ser ejecutado en prácticamente cualquier dispositivo, gracias a que fue desarrollado en el lenguaje de programación C lo que facilita la portabilidad del código a diferentes plataformas.

Windows 95 fue un sistema operativo desarrollado por Microsoft y lanzado en 1995. Se trató del primer sistema operativo de Microsoft en utilizar una interfaz gráfica de usuario integrada y fácil de usar, que permitía a los usuarios acceder a los programas y archivos mediante el uso del mouse y de ventanas gráficas.

Este sistema operativo incluyó la primera versión de DirectX, una colección de APIs de programación que ofrecían funciones para la creación de gráficos en 2D y 3D, sonido y entrada de dispositivos, lo que permitía a los desarrolladores crear juegos que podían aprovechar al máximo los recursos del hardware de la computadora.
Es importante mencionar que el API de DirectX fue la base de la consola de videojuegos de Microsoft, que originalmente se llamaba DirectXbox y luego se comercializó con el nombre de Xbox. Gracias a esto, los desarrolladores pudieron crear juegos para la Xbox utilizando las mismas herramientas y APIs que ya conocían de la plataforma Windows, lo que les permitió desarrollar juegos de alta calidad de manera más eficiente.
Blender es un software de código abierto para la creación de gráficos en 3D, animación y efectos visuales. Fue creado originalmente en 1995 como parte de un proyecto interno en la compañía de animación holandesa NeoGeo, donde Ton Roosendaal trabajaba en ese momento. Después de que NeoGeo cerrara sus puertas en 1997, Roosendaal decidió continuar el desarrollo de Blender de manera independiente y en 1998, fundó la organización sin fines de lucro Fundación Blender, dedicada a la promoción y el desarrollo de Blender como una herramienta de software de código abierto.
Desde entonces, Blender ha evolucionado para convertirse en una herramienta de software de renombre mundial para la generación de gráficos en 3D y animación, utilizada por profesionales y entusiastas de todo el mundo en una amplia variedad de proyectos, como películas, videojuegos, animación de personajes, efectos especiales, visualización arquitectónica, entre otros.

En 1996, la empresa 3DFX lanzó la tarjeta de video Voodoo, que se considera una de las primeras tarjetas de video dedicadas al procesamiento de gráficos en 3D para computadoras personales. La Voodoo fue innovadora en su tiempo gracias a su capacidad de procesamiento de gráficos en 3D en tiempo real, lo que la hizo muy popular entre jugadores de videojuegos y entusiastas de la tecnología.
La Voodoo marcó un hito en la historia de las tarjetas de video, ya que fue la primera tarjeta de consumo general a un precio razonable que ofrecía aceleración por hardware para gráficos 3D. Gracias a esta tarjeta, el consumo y la creación de gráficos 3D se popularizó en ambientes de escritorio caseros, revolucionando la industria de los videojuegos y abriendo el camino para el desarrollo de tecnologías de gráficos en 3D más avanzadas en las décadas siguientes.


En 1998 se lanzó al mercado Maya, un paquete de software comercial diseñado para la creación de gráficos 3D, animación y efectos especiales en cine y televisión. Fue desarrollado por Alias|Wavefront, una empresa canadiense que posteriormente fue adquirida por Autodesk en 2005.
Maya fue concebido principalmente para estudios de cine y televisión, así como para profesionales de la industria de efectos visuales. En el año 2000, se utilizó en colaboración con Disney para la realización de la película Dinosaurio y rápidamente se convirtió en una herramienta popular entre los profesionales debido a su capacidad para manejar grandes cantidades de datos y a su habilidad para crear animaciones y efectos visuales complejos, tales como la simulación de ropa y cabello, lo que permitió a los artistas crear animaciones más realistas y detalladas.
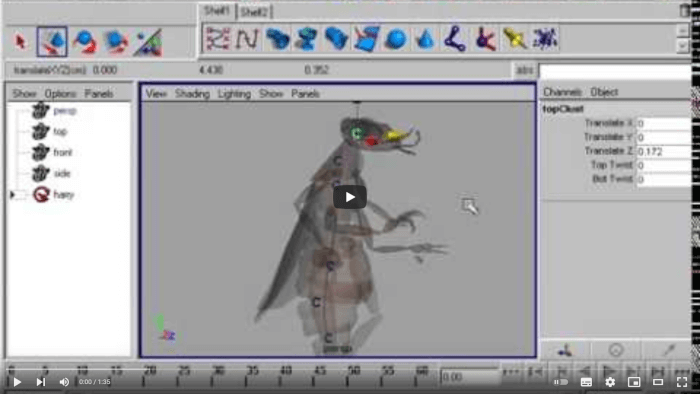
La tarjeta gráfica Nvidia GeForce 256, lanzada en 1999, fue pionera en el uso de la arquitectura GeForce para procesamiento de gráficos en 3D. Supuso un gran avance tecnológico al ofrecer un rendimiento superior a las tarjetas existentes en su momento y se convirtió en la primera GPU comercializada por Nvidia. Destacó por su nivel gráfico sin igual en la época, ayudando a diversificar el uso y consumo de gráficas 3D.


Desde los años 2000 hasta la actualidad, los gráficos por computadora en películas y videojuegos han experimentado un avance progresivo hacia el realismo, generando una carrera entre las necesidades de la industria y el desarrollo tecnológico que las satisface.
En esta época, la mayoría de las computadoras personales son capaces de soportar paquetes comerciales para la creación de 3D. Los videojuegos desarrollados con gráficas 3D han ido forjando la industria de los videojuegos que existe actualmente, mientras que las consolas presentan cada vez un mejor hardware gráfico.
Nvidia a raíz del éxito de su tarjeta GeForce 256, continuó creciendo hasta convertirse en líder en el desarrollo y comercialización de tarjetas gráficas.
También se hizo cada vez más común la presencia de animaciones 3D de alta calidad y efectos visuales realistas en el mundo del entretenimiento. Surgiendo estudios de animación como BlueSky, DreamWorks y Pixar, que comenzaron a dominar la taquilla; así como consolas de videojuegos cada vez más poderosas. La asimilación de la tecnología 3D ha sido tan gradual que actualmente se considera su uso como algo natural en diversos medios de entretenimiento, investigación y educación.
Para conocer más momentos importantes de la historia de la animación por computadora, la siguiente página ofrece una amplia cantidad de información complementaria:
https://computeranimationhistory-cgi.jimdo.com/
Durante el proceso de desarrollo de una animación, el producto final se divide en una jerarquía de cuatro niveles ().
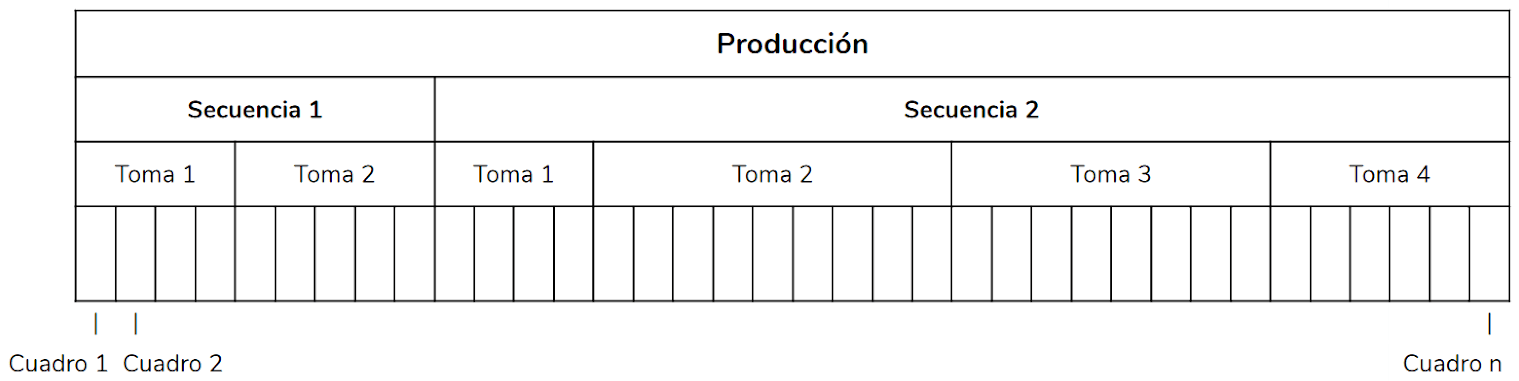
El producto final, es decir, la animación completa, se denomina como la producción.
Una secuencia (o escena) es un episodio completo, que abarca todos los acontecimientos que ocurren dentro de un mismo escenario o ambiente.
Una toma corresponde a una acción observada desde un punto de vista único, es decir, durante una toma se utiliza la misma cámara para capturar una acción ininterrumpida.
Por último, en el nivel más bajo, se encuentran los cuadros o fotogramas, que corresponden a una de las múltiples imágenes que componen una toma.
El desarrollo de una animación sigue una serie de pasos flexibles pero bien definidos para su desarrollo, los cuales se conocen como el pipeline de desarrollo de una animación. Seguir estos pasos permite un desarrollo más efectivo de una animación, permitiendo dividir el proceso en etapas que cimientan cada paso de la producción.
A grandes rasgos las etapas del proceso de desarrollo de una animación 3D son las siguientes:
La preproducción es una fase crucial que garantiza que una idea pueda materializarse a través de la definición de las bases que componen un proyecto de animación. Esta etapa se divide en diversas subetapas que se desarrollan de forma secuencial para asegurar unos cimientos sólidos para la producción.

El primer paso de un proyecto de animación es el planteamiento de una idea, la cual determina el concepto o tema que va a tratar la animación. La idea ofrece una síntesis breve sobre lo que ocurrirá durante la animación, pero no presenta detalles, solo el concepto general.

Una vez definida la idea, se comienza a desarrollar la historia, en la que se define la forma más efectiva de expresar y transmitir la idea, dándole una forma más concreta y definida.
Durante esta etapa, se plantean preguntas como: ¿quiénes son los personajes y qué tipo de conflicto tienen? ¿dónde y cuándo se desarrolla la historia? ¿a qué tipo de público va dirigida? ¿cuál es la apariencia final esperada? ¿cuánto tiempo, presupuesto y esfuerzo se van a invertir en el desarrollo?
Para formalizar y definir los detalles finos de la historia se utiliza un documento escrito llamado guión, script o screenplay (), donde se describe de manera textual las secuencias y tomas que ocurren durante la historia.
El guión se crea para asentar y precisar las decisiones tomadas, y concretar dicha información en un documento escrito, donde se especifican puntualmente las características de los personajes y sus acciones, el entorno y escenarios donde ocurre la animación, los diálogos, y todo lo que sea relevante para la producción.

Un guión se suele dividir en escenas, donde cada escena cuenta con un encabezado que indica de qué trata la escena, dónde y cuándo transcurre la acción.
Después del encabezado viene la descripción de la acción, que consiste de párrafos que especifican de forma concisa lo que ve y escucha la cámara (o el espectador). Se suele escribir en tercera persona con verbos en presente y se utilizan mayúsculas cuando: los nombres de los personajes aparecen por primera vez; se describen sonidos; con transiciones de la cámara.
Se tienen bloques de diálogo donde primero se muestra el nombre del personaje y a continuación sus líneas en el diálogo, entre paréntesis se suelen indicar acotaciones que son información sobre la actuación como sentimientos o énfasis en diversas partes del diálogo.
Los guiones describen las escenas de la producción y también especifican el tipo de transición que ocurre cuando se cambia de secuencia o toma. En caso de existir una transición, se suele indicar antes del encabezado de la escena para dar la pauta de cómo se entra a la escena.
Para conocer más información sobre la realización de un guión se recomienda revisar los siguientes vínculos:

El guión gráfico o storyboard es la herramienta visual que se utiliza para plasmar las ideas del guión en imágenes. Este proceso es fundamental para la creación de una animación, ya que permite planificar y previsualizar cada secuencia antes de ser producida.
El guión gráfico está compuesto por una serie de viñetas que muestran momentos específicos de las escenas del guión, y que incluyen detalles como el encuadre y la posición de la cámara, la disposición y las poses de los personajes, los diálogos y las interacciones que se desarrollan, así como los posibles efectos especiales y visuales.
Este documento suele presentarse a todo el equipo involucrado en el proyecto de animación para refinar y discutir las ideas, y así crear una base sólida para los siguientes pasos de la preproducción. Cabe mencionar que en algunas producciones, se pasa directamente del planteamiento de la idea al guión gráfico, sin pasar por la fase de escritura de un guión detallado, esto dependiendo del estudio o tipo de obra que se pretende animar.



La fase de previsualización o animatic se refiere a una versión en movimiento del guión gráfico. Para crear la previsualización se utilizan las imágenes del guión gráfico y se les añade diálogo, sincronización e información de tiempo, con el fin de determinar de manera precisa las características de la animación.


El animatic es una herramienta importante ya que permite estimar la duración de cada secuencia y toma, facilitando el ajuste de los tiempos en caso de ser necesario, lo que determina la duración final de la animación.



Tomando como referencia el guión y las propuestas visuales desarrolladas en el guión gráfico y la previsualización, se comienza a trabajar en el diseño y características visuales de la animación. Esto incluye el diseño de personajes, incorporando expresiones faciales, vestimenta, accesorios, escenarios, paletas de colores y el estado de ánimo que se desea transmitir en la animación.
Es importante tener en cuenta que los diseños desarrollados no son definitivos y durante la producción se pueden realizar cambios, iterando y definiendo de mejor forma las características visuales de los personajes y los escenarios. Además, en animaciones 3D, la fase de diseño generalmente se realiza con imágenes, por lo que durante la producción la traducción de estas imágenes a modelos tridimensionales puede modificar o ajustar el diseño final.
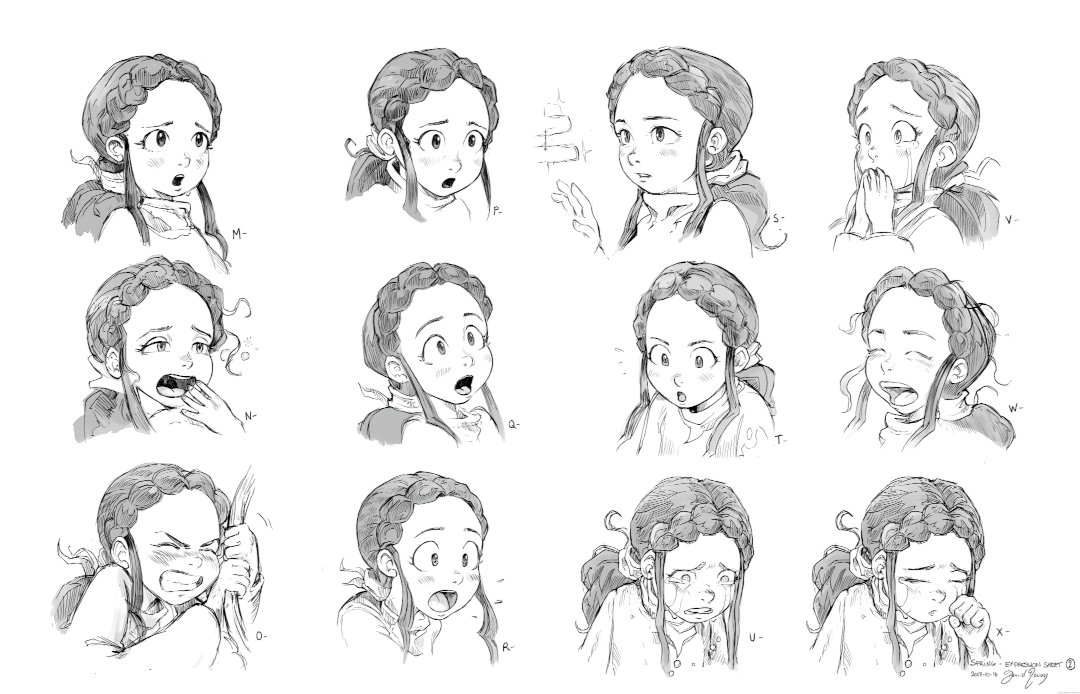
La producción es donde se concentra la mayor cantidad de trabajo y toma todo lo creado en la etapa de preproducción como base para el desarrollo del proyecto de animación.

A partir de la previsualización (animatic), los artistas 3D se encargan de reproducir la posición de la cámara, los personajes y el ambiente, realizando la etapa de disposición de elementos o layout de tal forma que se comienza con la traducción del animatic a elementos tridimensionales, definiendo claramente las dimensiones espaciales y temporales de la producción.


Durante la etapa de disposición de elementos es posible incluir animaciones, aunque por lo general suelen ser simples y rudimentarias, basadas principalmente en transformaciones básicas como rotaciones, traslaciones y escalamientos. Esto depende de que tan avanzado se encuentre el desarrollo de los modelos.
Es importante considerar que lo principal de la etapa de disposición de elementos es replicar en un espacio tridimensional las diversas tomas representadas durante el guión gráfico y, al mismo tiempo, representar el tiempo de duración de las escenas que fueron definidos durante el animatic.

Investigación y desarrollo son componentes clave en la animación, ya que se utilizan para resolver los retos técnicos necesarios durante el desarrollo del proyecto. En muchas ocasiones, la historia que se quiere contar requiere la presentación de elementos visuales específicos para los cuales no existen técnicas de animación o graficación por computadora previamente desarrolladas, por lo que es necesario inventar nuevos métodos o innovar en el uso de lo que ya existe.
Grandes estudios de animación como Disney () y Pixar (), cuentan con divisiones encargadas de realizar investigaciones sobre diversas técnicas y algoritmos en graficación y animación por computadora.








Además de algunos estudios de animación que publican sus desarrollos, el lugar académico más prestigioso en cuanto a investigación en el mundo de la graficación y animación por computadora es el grupo de interés especial en gráficas por computadora y técnicas interactivas, SIGGRAPH, (Special Interest Group on Computer Graphics and Interactive Techniques, https://www.siggraph.org/), sitio donde se pueden encontrar miles de artículos académicos en el área del computo gráfico.

Para realizar una animación 3D es necesario crear objetos que representen los elementos visuales de la animación, es decir, los personajes y escenarios que conforman la producción. En el contexto de la animación por computadora en 3D, un modelo es una representación geométrica de la superficie de un objeto.
A lo largo del tiempo, se han desarrollado diversas formas de crear y representar modelos tridimensionales, desde curvas y superficies paramétricas hasta mallas poligonales, que es la representación más usadas en la actualidad.



La escultura digital se han convertido en la forma preferida de los artistas para crear modelos tridimensionales, debido a la versatilidad y cantidad de detalles que se pueden lograr. Detrás de la escultura digital, se encuentra un trabajo por reproducir de forma computacional las técnicas utilizadas en la escultura tradicional en arcilla, donde el artista agrega, remueve, alisa y texturiza, por medio de diversas herramientas, hasta conseguir la representación deseada.
Es importante mencionar que por lo general, para realizar escultura digital de forma efectiva, es necesario el uso de tabletas digitalizadoras (o gráficas), que son dispositivos especiales que cuentan con una pluma que permite capturar diferentes niveles de presión sobre su superficie.





Durante la fase de texturizado y materiales, se agregan los colores, propiedades de los materiales y texturas que conforman la apariencia de las superficies de los modelos geométricos. Esto se realiza para representar adecuadamente las características visuales propuestas durante la fase de diseño de la preproducción.
Aquí se definen los materiales que tendrán cada objeto mediante shaders, que son pequeños programas que se ejecutan en la GPU. Además, se crean múltiples imágenes, también conocidas como texturas, para mejorar la apariencia de los modelos, estas texturas pueden ser creadas de manera artística en medios físicos o en programas de edición de imágenes, de forma procedural con ayuda de algún software o pueden ser fotografías de objetos reales.


El rigging es un proceso fundamental en la animación en 3D, y consiste en la creación de una estructura de controles que se utiliza para manipular los modelos tridimensionales de manera más sencilla y eficiente.
Estos controles conocidos usualmente como huesos, se conectan a la información geométrica del modelo y actúan como una especie de esqueleto virtual que proporciona una estructura articulada sobre la cual se realiza la animación.
El objetivo principal del rigging es proporcionar a los artistas de animación la capacidad de crear movimientos naturales y realistas en los personajes 3D. Al crear un rig, se asignan pesos y restricciones a cada uno de los huesos para que puedan moverse de forma coherente, intentando imitar los movimientos de las articulaciones humanas o animales. Esto permite simular acciones como caminar, correr, saltar, flexionar los músculos y realizar todo tipo de movimientos corporales.



La fase de animación es donde se crean los movimientos y acciones de los personajes y objetos. Aquí se utiliza la información desarrollada durante el layout y los controles creados durante el rigging para construir las acciones y secuencias de movimientos necesarias para representar cada toma de la producción.



Los efectos visuales 3D se encargan de animar elementos secundarios como el pelaje, el cabello, la ropa, el fuego, el agua, la nieve, el polvo, etcétera. El objetivo de estos efectos es mejorar la apariencia final de las escenas agregando realismo a la animación y haciendo que los elementos secundarios interactúen con los objetos tridimensionales de la animación. Para realizar estos efectos visuales usualmente se utilizan soluciones basadas en motores de física, para aportar de realismo a su comportamiento.





Durante el proceso de iluminación se agregan todas las fuentes de luz necesarias para dar el aspecto y el estado de ánimo a cada toma de la animación.
La iluminación junto con los materiales, es una de las etapas que más impactan en la representación visual y calidad final de las imágenes que componen la animación, por lo que debe prestarse mucha atención en su realización.





El renderizado o rendering es donde se crean todos los cuadros (o fotogramas) que componen la producción, es decir, se generan imágenes a partir de la información digital desarrollada durante todo el proceso de producción. Este es el último paso del proceso de producción y dependiendo del objetivo final de la animación, puede ser la última etapa que se desarrolla, antes de dar por concluida la producción, por ejemplo, en animaciones cortas como las publicitarias no se suele llegar a la postproducción.

En esta fase se lleva a cabo la combinación de las imágenes generadas durante la producción, junto con la adición de efectos especiales y correcciones de color. Este proceso tiene como resultado la obtención del producto final de la animación, es decir el video final correspondiente a la animación.

Durante la etapa de postproducción se trabaja con las imágenes obtenidas en el renderizado (la última etapa de la producción). Estas imágenes, de forma similar a la cámara multiplano, pueden representar diferentes profundidades de una escena. El proceso de composición involucra combinar las imágenes renderizadas para generar la secuencia final.

Durante los efectos especiales en 2D se agregan diversos tipos de sistemas de partículas (como polvo o gotas de lluvia sobre la cámara), se realiza el reemplazo de la pantalla verde (si es que se usó), se agregan los textos de los créditos, y en caso de ser necesario se incluyen movimientos a la imagen para simular sacudidas en las tomas. Todos estos efectos se agregan para mejorar el producto final y añadir detalles que embellezcan la animación.


En la corrección de color se ajustan todas las imágenes de la producción para que tengan un color consistente.
Esto es importante, ya que en general las grandes producciones de animación se dividen en equipos de trabajo que realizan de manera independiente las secuencias o tomas, por lo que pueden presentarse ligeras variaciones en los tonos de los colores de las imágenes renderizadas. Además de que ofrece la posibilidad de ajustar el color de las imágenes y lograr transmitir y enfatizar un sentimiento particular.



En esta última fase se toman todas las imágenes postprocesadas y se juntan para generar el formato final en el que se distribuye la animación, por ejemplo, un gif animado, un video 4k listo para ser proyectado en el cine, o un video en Full HD para YouTube. Aquí se da por finalizada la producción.
Los efectos de sonido como las voces en los diálogos y en off o de narración, así como la música, añaden un gran impacto y emoción a la animación. La incorporación del sonido en la producción de una animación puede ubicarse en diferentes momentos: puede ser que la animación sea originada por alguna pista musical como un video musical, o que la animación esté fuertemente ligada con los diálogos, o una vez realizada la producción se complemente con composiciones musicales para mejorar la ambientación.
El sonido es un elemento muy importante en las animaciones, pero no siempre es fácil de realizar. La mayoría de los efectos de sonido que se escuchan en películas o series son creados y su creación es todo un arte. Utilizar diferentes sonidos en una misma producción puede cambiar dramáticamente la forma en que se perciben las diversas escenas que la componen.




Una historia es un relato de los acontecimientos que les suceden a uno o varios personajes, los cuales se encuentran en un tiempo y lugar bien definidos. Los cuentos y relatos han sido una parte intrínseca de la humanidad, ya que contar y escuchar historias ha sido una parte fundamental de la transmisión de conocimiento.
Para mantener a la audiencia entretenida, las historias suelen incluir personajes interesantes, conflictos que superar y conclusiones satisfactorias. La creación de buenas historias se basa en estructuras y conceptos desarrollados en la literatura, el teatro y el cine, como por ejemplo, la estructura en tres actos, los arcos narrativos, el monomito, entre otras más.
Al analizar algún cuento, relato o historia es posible notar que se presenta una estructura general muy similar. Esto se debe a que desde tiempos antiguos, se ha utilizado una estructura básica de tres tiempos o actos () para contar los sucesos de una historia, estos momentos o actos son:

El primer acto (inicio o planteamiento) es la parte de la historia donde se presentan a los personajes, así como sus necesidades, fortalezas y debilidades. Además se presenta el lugar y el tiempo en que suceden las acciones para determinar el contexto de la historia. Todos los elementos presentados deben respaldar de forma consistente el planteamiento de la historia, mientras se genera interés en el espectador.
Al término del primer acto se localiza el primer punto de giro (o punto de inflexión), aquí se plantea el conflicto principal que desencadena la mayoría de las acciones subsecuentes de la narración. En principio, algo fuera de lo ordinario ocurre y este evento detona todos los acontecimientos importantes para el desarrollo de la historia.
En el segundo acto (mitad o nudo) se desenvuelven todos los acontecimientos en torno a la nueva situación en la que se encuentra el personaje principal. Se le denomina nudo debido a que durante esta parte se van entrelazando los diversos acontecimientos que complican el progreso de la historia, es decir, se desarrolla la trama de la narración.
Durante la primera parte del segundo acto, se observa al personaje principal intentando adaptarse a la nueva situación en la que se encuentra, presentando una actitud pasiva al intentar comprender lo que ocurre a su alrededor.
En el punto medio del segundo acto ocurre un cambio que hace que el personaje se adapte a la nueva situación, haciendo que pase de ser un espectador a un protagonista activo, es decir, el personaje por fin entiende (o cree entender) la situación en la que se encuentra y actúa acorde a ella.
Al término del segundo acto ocurre el segundo punto de giro, que es el último momento en donde se presenta nueva información relevante para la historia, e indica que se encuentra cerca de la resolución final del conflicto. Esto quiere decir que el personaje principal ya logró alcanzar el estado en donde puede afrontar el desafío final y que ya no va a adquirir más conocimientos o habilidades para enfrentarlo.
El tercer acto (final o desenlace) es donde se resuelven las situaciones planteadas a lo largo del relato, llevando la narrativa a su culminación, dando conclusión a los eventos desarrollados durante la historia. Aquí deben atarse todos los cabos sueltos y llevar al espectador a un punto de resolución donde la historia concluye con la narración.
De forma general, una estructura narrativa en tres actos presenta un comienzo donde el personaje principal se encuentra en su cotidianidad. Después, un evento inesperado crea un cambio en la vida del personaje, y a partir de ese momento ocurren situaciones de tensión y relajación, mientras la historia va avanzando. Por último, se presenta la confrontación final y se llega al desenlace de la historia dando resolución al conflicto planteado.
Una historia suele presentar tres elementos básicos para su narración: personajes, metas (u objetivos), y conflictos.
Por lo general los personajes son seres humanos, animales o imaginarios, que forman parte de una narrativa. Los personajes suelen ser el recurso que se utiliza para mostrar y guiar los eventos de una historia, ya que son las entidades que experimentan los diferentes acontecimientos que se suscitan a lo largo de la narración.
La meta u objetivo puede ser cualquier cosa que un personaje desee (o cree que desea) y se encuentre dispuesto a conseguir sin importar lo que cueste. Puede ser un objeto, un evento, una persona o un logro que anhela alcanzar.
Mientras el personaje intenta cumplir la meta, por lo general existen fuerzas opuestas que dificultan su realización, esto con la finalidad de volver más interesante la historia, ya que los conflictos agregan una capa de drama a la historia y así puede volverse más atractiva para el espectador.
Los conflictos pueden ocurrir:
El concepto central es la premisa que sustenta la narración de la historia, por ejemplo: el cambio nunca es fácil; aprender a dejar ir; nunca darse por vencido; siempre aspirar a ser el mejor; el día se repite una y otra vez; los muñecos tienen vida pero se quedan inmóviles cuando hay gente cerca.
Este simple concepto debe estar soportado por todas las ideas y acciones de la historia; y por consistencia, siempre hay que procurar no generar ideas que entren en conflicto con el concepto central, esto es lo que hace a la narrativa creíble. Para una animación el concepto central se define durante la preproducción en las fases de la idea y la historia, y es lo que da la pauta que sustenta la gran mayoría de las decisiones para el desarrollo de la animación.
Un arco argumental o narrativo se refiere a la estructura o forma de una historia; es decir, cuál es la consecución o progresión de acontecimientos que ocurren dentro de la narrativa. Esta estructura es importante para determinar el tipo de acontecimientos que se cuentan dentro de una historia y se construye por encima de la estructura de tres actos para organizar la forma en la que ocurren los eventos narrativos.
En el 2016, The Computational Story Lab de Vermont, publicó el artículo: “The emotional arcs of stories are dominated by six basic shapes”, donde se presentan los resultados obtenidos de analizar un conjunto de 1327 historias de ficción. Lo que se encontró en el estudio fue que todas las historias analizadas pueden ser catalogadas en 6 arcos narrativos básicos. Si se grafica el tipo de eventos que suceden en estos arcos narrativos, es más sencillo observar la estructura subyacente en la forma en la que se cuentan los acontecimientos de una historia.
De harapos a riqueza (ascenso), la historia avanza constantemente siempre hacia un final feliz; la progresión de eventos que ocurren siempre logran que el personaje se encuentre en una mejor situación.
Tragedia o de riqueza a harapos (descenso), en contraposición al arco anterior, las cosas que le suceden al personaje solo empeoran llevándolo a un desenlace trágico.
Persona en el agujero (descenso y ascenso), aquí al inicio ocurren eventos desafortunados o trágicos, pero mientras avanza la trama la situación poco a poco comienza a mejorar, dando como resultado que el personaje alcance un final feliz.
Ícaro (ascenso y descenso), este arco narrativo hace referencia a los acontecimiento que ocurren en el mito de Ícaro, donde se comienza con una situación prometedora, pero poco a poco ocurren acontecimientos que empeoran todo hasta culminar en un final trágico.
Cenicienta (ascenso, descenso y ascenso), aquí se hace referencia a la historia de la Cenicienta, donde el personaje inicia con situaciones agradable y felices, pero rápidamente ocurren acontecimientos negativos que dan indicios de tragedia, para que finalmente se logre terminar con un buen final.
Edipo (descenso, ascenso y descenso), este arco narrativo se asemeja al mito de Edipo, donde se presentan inicialmente situaciones muy desfavorables para el personaje, seguidas de momentos que indican un final feliz, para culminar con eventos trágicos para el desenlace.
Joseph Campbell fue un mitólogo, escritor y conferencista estadounidense, que después de años de estudio en mitología comparativa, descubrió que a lo largo de diferentes culturas y períodos de tiempo, las narraciones de historias mitológicas (o heroicas) utilizaban en esencia la misma estructura narrativa.

Campbell nombro a esta estructura el viaje del héroe o el monomito, la cual divide a una historia en tres partes fundamentales:
Las tres partes fundamentales a su vez se dividen en 17 subpartes o etapas con una estructura bien definida. Hay que aclarar que no todas las historias usan todos los elementos del monomito; y algunas incluso se centran en solo unas cuantas partes, pero de una forma u otra la gran mayoría de las 17 subpartes se encuentran en las historias mitológicas o heroicas. También es importante indicar que varias historias no mitológicas utilizan las diversas partes que componen al monomito como parte de su estructura narrativa. Las 17 subpartes del monomito son:
Se presenta al héroe dentro de su cotidianidad realizando sus actividades, cuando algo lleva al héroe fuera de lo habitual hacia lo desconocido. Aquí se presenta al protagonista, mostrando sus orígenes y sentando las expectativas y características iniciales que lo definen.
Dentro de la cotidianidad del héroe surge algún acontecimiento que lo lleva o llama hacia la acción, pero la reacción inicial del héroe es rechazar el llamado a la acción prefiriendo seguir en su zona de confort, pero al final las circunstancias lo obligan a iniciar la aventura.
Una vez que el héroe ha aceptado la llamada a la acción, el guía o mentor del héroe (generalmente aquel que lo llama a la aventura) le presenta u obsequia algún tipo de objeto o conocimiento que lo ayudará durante su aventura.
Aquí el héroe está comenzando oficialmente su viaje y ha pasado el umbral de su zona de confort, teniendo que enfrentarse a diversas situaciones que por lo general en condiciones normales no enfrentaría.
Este es el punto del viaje en el que el héroe está totalmente dispuesto a cambiar para convertirse en quien necesita ser.
Por lo general, el deseo de cambio se ve detonado por un acontecimiento que marca fuertemente al protagonista.
Durante su viaje el héroe se enfrenta a diversas pruebas y comúnmente falla una o más de ellas en su primer intento.
No todas las pruebas se presentan al mismo tiempo, por lo general se dosifica la realización de las pruebas, para permitirle al héroe crecer a un ritmo adecuado.
En esta subetapa el héroe se encuentra con algo o alguien que se vuelve de suma importancia para él.
En el contexto de las historias heroicas, generalmente esta etapa se presenta cuando el héroe encuentra a alguien a quien amará o que debe defender y proteger.
Durante los acontecimientos que se desarrollan, el héroe se ve tentado para desviarse del objetivo principal de la aventura. Esta tentación puede ser cualquier situación, idea o persona que ocasione que el héroe tenga dudas sobre cómo debe proceder o qué camino tomar en su aventura.
En la consagración, el héroe realiza un gran esfuerzo y sacrificios para conseguir el final de la aventura, por lo general se ve forzado a confrontar sus mayores temores para salir triunfante. Al igual que la tentación, esta confrontación puede ser una situación, idea o persona.
En la apoteosis o el encuentro con los dioses, se presenta un acontecimiento en el que algún personaje (usualmente el mentor del héroe) trasciende más allá de su estado físico, presentado directamente a seres supremos.
Por lo general esta parte se representa con la muerte de algún personaje para salvar al héroe o para que pueda descansar en paz después de lograr su propio objetivo.
El llamado a la aventura por lo general lleva consigo el cumplimiento de una meta u objetivo, en este sentido, el don final representa la culminación del viaje del héroe, ya que es el momento de la historia en que se consigue el objetivo por el cual comenzó todo.
Habiendo obtenido el don final, después de las diversas experiencias que el héroe experimentó, por lo general hay un rechazo a regresar a su mundo, que ahora se ve como ordinario. Pero al igual que en el comienzo de la aventura, se desarrollan diversos acontecimientos que lo convences u obligan a regresar.
Una vez que el héroe se resigna y acepta su regreso, en esta etapa se produce un escape épico, ya que regresar no suele ser sencillo. Y por lo general, es uno de los momentos en el que el héroe utiliza todo lo que aprendió durante su viaje así como el don final para poder regresar. Este escape puede ser tan peligroso como el viaje principal del héroe.
El héroe al regresar suele requerir ayuda para volver a incorporarse al ambiente que dejó atrás, particularmente necesita de alguien externo que le proporcione ayuda u orientación para volver a su vida cotidiana.
En esta etapa, valiéndose de todo lo que aprendió durante su viaje el héroe intenta adaptarlo a su vida cotidiana, tratando de mejorar su nueva experiencia de vida.
Poco a poco el héroe aprende a equilibrar el viejo mundo y el nuevo mundo, experimentando situaciones que anteriormente no hubiera vivido y siendo por lo general un mejor individuo.
Al ser un maestro de sus viejas y nuevas habilidades, el héroe crece y aprende a no temer a la muerte ni a arrepentirse por el pasado.
En este punto, la historia del héroe concluye y se da por terminado su viaje.
A continuación se presenta una breve descripción de como se utiliza el viaje del héroe, en la película: “Star Wars Episode IV - A New Hope”. En caso de no conocer la película en los siguientes vídeos se puede ver un resumen al respecto.


Luke Skywalker vive su vida normal como un granjero junto con sus tíos en el planeta Tatooine. De repente Luke es llamado a la aventura por la aparición de R2-D2, C-3PO y el mensaje de ayuda enviado por la princesa Leia dirigido a Obi Wan Kenobi. Obi Wan invita a Luke a ir al planeta Alderaan para iniciar el rescate.
Luke rechaza la invitación de Obi Wan, argumentando principalmente que no podría dejar a sus tíos para irse en una aventura espacial.
Durante su charla con Obi Wan, este le habla sobre su herencia Jedi, y le da a Luke el sable de luz de su padre.
Luke descubre que el Imperio está buscando a los androides enviados por la princesa Leia, y regresa a la granja de sus tíos para advertirles del peligro, pero llega tarde y sus tíos habían sido asesinados por el Imperio. Entonces Luke le pide a Obi Wan ir con él y que le enseñe cómo ser un caballero Jedi.
La primera prueba con la que se encuentra Luke es escapar de Tattoine, y para lograrlo contratan los servicios de Han Solo y Chewbacca para salir del planeta y llegar hasta Alderaan. Dentro de la nave Luke comienza con su (breve y cuestionable) entrenamiento Jedi.
Luke y compañía logran llegar a Alderaan, o lo que quedó del planeta, ya que fue destruido por la estrella de la muerte, que para su desgracia se encontraba cerca y son capturados. Dentro de la estrella de la muerte descubren que ahí se encuentra capturada la princesa Leia y van a su rescate e intentan huir del lugar. La princesa Leia les presta ayuda a sus salvadores, por eso se considera como el encuentro con la diosa, pero al mismo tiempo se vuelve una distracción (tentación) para algunos miembros de la tripulación.
Dentro de la estrella de la muerte se encuentra Darth Vader (el villano de la película), y para lograr escapar es necesario hacerse cargo de él. Así que Obi Wan es el encargado de realizar esta tarea. En esta etapa, es Obi Wan el que se consagra enfrentando a Darth Vader, cerrando de cierta forma asuntos pendientes, al mismo tiempo es Obi Wan el que trasciende al dejar su forma física y morir.
El objetivo inicial de la aventura de Luke consiste en rescatar a la Princesa Leia junto con los planos de la estrella de la muerte que ella posee. Esto lo consiguen gracias al sacrificio realizado por Obi Wan, siendo este acto lo que les permite escapar de la estrella de la muerte.
Obtenido el don final, el rescate de Leia y los planos de la estrella de la muerte, Luke decide unirse a los rebeldes para destruir la estrella de muerte y evitar que otros planetas sean destruidos.
Aquí el vuelo mágico es literal, ya que Luke vuela en una nave espacial (X-Wing) para atacar y destruir la estrella de la muerte.
Durante la misión, Luke y los rebeldes deben enfrentarse a las naves del Imperio y en particular a la nave piloteada por Darth Vader. Dentro del contraataque realizado por el Imperio, Luke está apunto de ser destruido por Darth Vader, pero en el momento justo, Han Solo y Chewbacca lo salvan.
Valiéndose de la información de los planos (don final) y las habilidades aprendidas durante su aventura, Luke dispara un misil que con la ayuda de la fuerza, logra impactar el punto débil de la estrella de la muerte y con esto logra destruirla, de una vez y para siempre.
Después de la destrucción de la estrella de la muerte, Luke y compañía regresan a la base rebelde, donde reciben medallas por sus logros heroicos. Y ahora la galaxia se encuentra en paz - al menos por ahora...
Existen algunas simplificaciones del viaje del héroe, donde se eliminan o combinan algunas de las subpartes para simplificar la estructura narrativa. Pero sin importar las simplificaciones, el viaje del héroe tiene una estructura subyacente muy bien definida.
Esta estructura puede observarse en la siguiente imagen:

Dan Harmon, escribió que:
El círculo de la historia propone una simplificación al viaje del héroe, utilizando un círculo dividido en 8 partes donde se distribuyen las diversas etapas de la narración.

Como se puede notar, el círculo de la historia remueve muchas de las partes heroicas y sobrenaturales del viaje del héroe, permitiendo utilizar la estructura del círculo de la historia para una variedad de historias, no solo las basadas en héroes.


Kishōtenketsu (起承転結) es un término en japonés que describe la estructura y desarrollo de narrativas en la literatura china coreana y japonesa. Originalmente utilizado en la poesía china como una composición de cuatro líneas, pasando por Corea y llegando a Japón donde adquiere su significado actual, como una estructura narrativa desprovista de conflicto, en contraposición a las estructuras narrativas occidentales. Cada uno de los cuatro caracteres que componen el término tiene un significado específico y describen la estructura narrativa:
Similar a la estructura de tres actos, el Kishōtenketsu divide una historia en partes bien determinadas que simplifican la construcción de una historia, aunque en contraposición a una estructura de tres actos aquí la historia se divide en 4 partes principales.
Esta estructura de “cuatro” actos se enfoca en la exposición y el contraste, ya que en el inicio se presentan a los personajes y el contexto de la historia, durante el desarrollo se ofrece la información necesaria para conocer a los personajes y la situación en la que se encuentran; siendo estos dos primeros actos la exposición o al establecimiento de la situación que se quiere contar. Durante el giro se presenta algo que modifica drásticamente lo que se ha establecido en los dos actos anteriores, generando un contraste en la información presentada y planteando una nueva situación que el personaje debe enfrentar. Y por último en la conclusión se da a conocer el resultado de exponer al personaje al giro.

Algo importante que hay que mencionar es que el Kishōtenketsu se enfoca en cómo un personaje vive, experimenta y reacciona ante alguna situación, sin importar si la conclusión es positiva o negativa. Por lo que en el giro no necesariamente se tiene un problema o conflicto que el personaje deba resolver, sino que simplemente es una situación diferente que experimenta. Esto contrasta con la forma en la que desarrollan las historias con la estructura de tres actos donde, por lo general, el personaje entra al segundo acto al iniciar un conflicto y sale del segundo acto al resolver o enfrentar dicho conflicto. Mientras que bajo la estructura narrativa Kishōtenketsu el giro no necesita ser un conflicto, solo necesita ser algo contrapuesto con lo presentado en el Ki y Shō, siendo por lo general algo que ni el personaje ni el público esperaban.


Además de la historia y narración de la misma, es bueno conocer algunos conceptos adicionales que se utilizan sobre las estructuras básicas que permiten ayudar a contar una historia de manera más efectiva.
En la comedia, por lo general, se presenta una situación y se genera un estado de tensión, para luego mostrar de forma súbita algo completamente inesperado. Básicamente, se juega con las expectativas que el público tiene sobre una situación dada, y se revela un desenlace que va en contra de su intuición.
De forma simplificada, la comedia suele ser un contraste entre dos marcos de referencia incompatibles, vinculados de manera inesperada y repentina.




La empatía es la capacidad de comprender los sentimientos de otra persona y ponerse en su lugar. La simpatía, por otro lado, es solo contemplar los acontecimientos que le ocurren a la persona, sin comprender profundamente su situación.
Es recomendable crear historias y personajes con los que el público pueda generar empatía, ya que esta conexión emocional permite que la audiencia se relacione directamente con la historia, en lugar de simplemente entender lo que sucede.


Como se mencionó previamente, durante la fase de preproducción se crea una previsualización (animatic o story reel) con el objetivo de mostrar la historia haciendo hincapié en los tiempos, acciones, tomas y cambios de cámara que componen las secuencias de una animación.
La previsualización es un proceso de bajo costo que permite tomar decisiones sobre qué tipo de tomas usar durante la producción y ajustar diversas ideas y formas de presentación antes de comenzar la producción.
Existen tres áreas principales de las técnicas de previsualización:
La audiencia solo puede ver lo que se le presenta, por lo que es importante decidir qué información se muestra en cada toma y así evitar que el público se pierda de información relevante para la comprensión de la historia. Algunos aspectos a considerar al presentar información son: la relación de aspecto de las imágenes, los planos cinematográficos utilizados para mostrar la información, las reglas de composición y cómo dirigir la atención del público hacia la información importante.
La relación de aspecto se define como la razón o proporción que existe entre el ancho y el alto de una imagen o pantalla. En la producción de películas y animaciones, es importante establecer las dimensiones de las imágenes que se van a crear, de manera similar a cómo un pintor elige el tamaño de su lienzo para comenzar a crear su obra.
William Kennedy Dickson empleado del laboratorio de Thomas Edison, ideó el concepto de relación de aspecto mientras buscaba el tamaño más adecuado para la película utilizada en el quinetoscopio. Finalmente, se decidió un prototipo de película de 35 mm en el que cada imagen tenía una altura de cuatro perforaciones, lo que resultó en unas dimensiones aproximadas de 2.4cm de ancho por 1.8cm de alto, es decir, en una relación de aspecto de 4:3. Esta proporción se convirtió en el estándar de la industria cinematográfica de su época.

La estandarización del cine sonoro a finales de la década de 1920 provocó el primer cambio en la relación de aspecto, haciendo que la distribución del espacio en la película de 35 mm se modificará por la inclusión de información de sonido directamente en la cinta, lo que redujo el ancho de la imagen. Este cambio ocurrió por la necesidad de sincronizar de manera efectiva el audio con las imágenes, colocando la información sonora en un costado de la película (). Y para evitar el cambio de los proyectores existentes en los cines, se decidió reducir el área final de las imágenes.
Con esta modificación se redujo el ancho de las imágenes, modificando la relación de aspecto a 1.37 : 1, denominada relación académica (Academy ratio), y reemplazando en 1937 el estándar previo de 4 : 3.
En sus comienzos, la televisión adoptó el formato de las películas mudas (con una relación de aspecto de 4 : 3) y, al volverse popular, la industria cinematográfica comenzó a preocuparse ya que la gente prefería ver películas en su hogar.
Así, durante la década de 1950, el cine intentó ofrecer algo novedoso para la audiencia: el formato panorámico. Es así como surge Cinerama (la fusión entre cine y panorama, ), un tipo de proyección que utilizaba tres cámaras de 35mm para proyectar sus imágenes hacia un lente de 27mm sobre una pantalla curva, dando una relación de aspecto de 2.59 : 1.

La producción de películas en Cinerama era costosa y complicada, por lo que Paramount Pictures decidió apostar por su propio formato panorámico, realizando pruebas con la película “Shane” de 1953, la cual fue filmada en el formato académico (1.37 : 1), pero se proyectó utilizando una relación de aspecto de 1.66 : 1, lo que requería que la imagen fuera recortada en los extremos superior e inferior y ajustando ligeramente el ancho. En general este método no era ideal ya que al mutilar la imagen se perdía información visual de la película.
La Twentieth Century Fox también creó su propio formato panorámico, el CinemaScope, utilizando inicialmente la proporción 2.60 : 1, pero ajustando y probando con el tiempo las relaciones 2.35 : 1 y 2.39 : 1 (o 12 : 5), siendo esta última utilizada en el cine en la actualidad.
Después de que su formato Cinerama no tuvo éxito, Paramount Pictures decidió cambiar su enfoque de filmación de horizontal a vertical, lo que resultó en imágenes más largas con una relación de aspecto de 1.85 : 1. Este sistema se conoció como VistaVision (), y su relación de aspecto se convirtió en un estándar en la industria cinematográfica.

En la actualidad, las relaciones de aspecto más comunes son:
Una sugerencia para elegir la relación de aspecto adecuada es considerar el tipo de contenido que se quiere presentar.
Si el contenido presenta paisajes o acciones que involucran a grandes grupos de personas con la misma importancia, entonces se debe optar por una relación de aspecto más ancha que alta.
Si el contenido presenta elementos más personales o lugares pequeños y cerrados, como una habitación, entonces se debe optar por una relación de aspecto más alta que ancha.
Por supuesto, siempre hay excepciones y es válido cambiar la relación de aspecto durante diferentes escenas de una producción, como se muestra en el siguiente video.

Los planos cinematográficos son el lenguaje que se utiliza para describir una toma antes de encuadrarla. Esencialmente, son conceptos que permiten definir qué elementos se muestran dentro de una toma o cuánto de esos elementos se presentan, sin tener en cuenta la composición final.
Existen varios planos cinematográficos relacionados con la distancia relativa que existe entre la cámara y el sujeto, ya que al variar está distancia el tamaño final del sujeto en la imagen cambia. Algunos de estos planos son:
A continuación, se presentan algunos ejemplos de estos planos cinematográficos mediante el análisis del cortometraje Spring de Blender Animation Studio (https://blender.studio).

Un gran plano general, también conocido como plano de establecimiento, es un tipo de toma que busca presentar una idea general sobre la ubicación de todos los elementos narrativos, diluyendo los detalles específicos de la acción. Este tipo de plano cinematográfico muestra una vista muy amplia de la escena, incluyendo una gran cantidad de espacio en el encuadre. El sujeto de la escena a menudo aparece como un pequeño elemento en relación con el entorno que lo rodea. Se utiliza al principio de una escena o película para establecer el lugar y el ambiente, o para dar una visión general del paisaje o del entorno en el que se desarrolla la historia. También puede utilizarse para mostrar la relación entre los personajes y el entorno, o para enfatizar la distancia emocional o física entre los personajes.


El plano general es un tipo de toma que muestra al sujeto de la escena en su totalidad, desde la cabeza hasta los pies, y una cantidad significativa del espacio alrededor del sujeto. Se utiliza para establecer la relación espacial entre los personajes y su entorno, así como para mostrar la acción y el movimiento en una escena. Por ejemplo, en una película de acción, un plano general podría ser utilizado para mostrar la lucha entre dos personajes y para dar una idea del entorno en el que se lleva a cabo la lucha. Además, el plano general establece la localización de la escena, dando una idea general del lugar donde se encuentra el sujeto y el ambiente a su alrededor. También se utiliza para dar un toque de dramatismo a la escena, por ejemplo, mostrando a un personaje solo y empequeñecido en un entorno grande y vacío.


El plano entero, también conocido como plano figura, es un tipo de toma que muestra al sujeto completo desde la cabeza hasta los pies, ocupando la mayor parte del encuadre, sin dejar demasiado espacio a su alrededor. Este tipo de plano se utiliza para mostrar al personaje en su totalidad, ofreciendo una idea clara de su apariencia y vestimenta. También es útil para mostrar el movimiento y la acción en una escena, y para establecer la relación espacial entre los personajes y el entorno de la escena. El plano entero puede enfatizar la expresión y el lenguaje corporal de los personajes, y dar una sensación de presencia física en la pantalla.


El plano medio es un tipo de toma que muestra al personaje desde la cintura o la cadera hacia arriba, permitiendo observar más detalles de su figura. Es especialmente adecuado para conversaciones entre dos individuos, ya que permite mostrar a los dos interlocutores simultáneamente. En este tipo de plano, se enfatiza la interacción entre los personajes, mostrando sus expresiones faciales y lenguaje corporal. También se utiliza para resaltar el movimiento y la acción en una escena, y para establecer la relación espacial entre los personajes y el entorno. Además, el plano medio puede enfatizar los detalles y gestos sutiles del personaje, y contribuir a establecer la atmósfera emocional de la escena.


Un plano medio corto muestra al sujeto desde los hombros o el pecho hacia arriba, enfatizando principalmente la cabeza y el rostro al dejar poco espacio alrededor del sujeto. Este tipo de plano cinematográfico se utiliza a menudo para mostrar las emociones y expresiones faciales del personaje con más detalle, y para resaltar la importancia de un diálogo o una expresión facial específica. Además, puede utilizarse para destacar ciertos detalles del personaje, como su maquillaje, cicatrices o tatuajes. El plano medio corto también puede crear una mayor conexión emocional entre el personaje y el espectador, así como un mayor sentido de intimidad en la escena, al aislar la figura del sujeto y descontextualizarla de su entorno con el fin de llamar la atención hacia algún aspecto particular del sujeto.


El primer plano es un recurso cinematográfico que consiste en enfocar al sujeto en gran detalle, enfatizando su rostro y, en el caso de cuerpos humanos o animales, también parte de los hombros. Este tipo de toma se utiliza frecuentemente para resaltar la importancia de un detalle específico, como una expresión facial, un objeto o una acción. Además, es una técnica efectiva para generar empatía y conexión emocional con el espectador, ya que permite mostrar los ojos del personaje, y así transmitir con mayor detalle la emoción que experimenta y establecer una conexión más directa y emocional con él.


Un primerísimo primer plano es un plano cinematográfico que muestra un detalle extremadamente cercano del sujeto, como una parte específica del rostro, ocupando casi todo el encuadre y dejando muy poco espacio alrededor del objeto. En el caso del rostro, este plano suele capturar desde la altura de la frente hasta debajo de la barbilla. Este tipo de plano se utiliza para enfatizar detalles específicos, como los ojos del personaje, una mano sosteniendo un objeto, una gota de sudor en la frente, entre otros. También puede generar una sensación de incomodidad o tensión en el espectador debido al encuadre estrecho y la falta de espacio alrededor del objeto. El primerísimo primer plano se utiliza en gran medida para agregar dramatismo o intensidad a una escena y destacar un objeto o detalle relevante.


Un plano detalle muestra un objeto extremadamente cerca, ocupando todo el encuadre de la toma. Se utiliza para enfatizar un detalle particular que es importante para el espectador y que no debe perderse; puede mostrar detalles muy específicos de un objeto o parte del cuerpo, como los ojos, una herida, un reloj, un arma, texto, etc. Es especialmente útil para enfatizar elementos que tienen una importancia significativa para la trama o que proporcionan información importante al espectador. Por ejemplo, en una película de suspenso se puede utilizar un plano detalle para mostrar una mano que sostiene un arma, enfatizando el peligro y la tensión en la escena. También se puede utilizar como una herramienta de transición, mostrando un objeto en primer plano que luego se convierte en el objeto principal de la siguiente escena.


Existen varios planos cinematográficos que se basan en el ángulo que se forma entre la cámara y el sujeto, por ejemplo:
Y también hay algunos planos cinematográficos que muestran el supuesto punto de vista del sujeto.
Un plano cenital es un recurso cinematográfico en el que la cámara se sitúa exactamente encima y de forma perpendicular al suelo, capturando una escena desde un ángulo elevado. Este tipo de plano es comúnmente utilizado para mostrar una vista panorámica de un paisaje, una multitud o un evento, con el objetivo de presentar una visión clara y global del conjunto, también puede ser utilizado para transmitir una sensación de poder o autoridad sobre los personajes, como en una escena de interrogatorio donde el uso de un plano cenital muestra la posición elevada de la policía sobre el sospechoso, sugiriendo que tienen el control de la situación.


Un plano picado es un recurso cinematográfico en el que la cámara se ubica en una posición elevada, apuntando hacia abajo para capturar una escena desde un ángulo inclinado. Este plano se utiliza para mostrar la posición de la cámara en relación a los personajes u objetos en la escena, y a menudo se emplea para transmitir una sensación de inferioridad o vulnerabilidad en los personajes. Por ejemplo, si la cámara está ubicada en un punto elevado para filmar a un personaje que está en el suelo, el plano picado puede hacer que el personaje parezca pequeño y vulnerable, lo que sugiere situaciones de peligro o incertidumbre.
También se utiliza para mostrar la perspectiva de un personaje en particular, con la finalidad de crear una sensación de separación o distancia emocional. Si la cámara se encuentra en una posición elevada durante una escena en la que un personaje está siendo rechazado o marginado, el plano picado puede enfatizar la distancia emocional entre ese personaje y los demás.


Un plano a la altura de los ojos se realiza con la cámara a una altura aproximada a la de los personajes o sujetos en la escena, lo que busca generar una imagen natural para la audiencia.
Este tipo de plano se utiliza con frecuencia en cine y televisión para crear una sensación de realidad y conexión con los personajes. Al estar a la altura de los ojos, el espectador se siente como si estuviera en la misma posición que el personaje, lo que permite una mayor empatía y conexión emocional. Además, el plano a la altura de los ojos se utiliza para mostrar a los personajes de manera equilibrada, evitando una sensación de superioridad o inferioridad, lo cual es especialmente importante en diálogos o interacciones entre personajes. Usar un plano demasiado elevado o demasiado bajo puede influir en la percepción de los personajes y su relación entre ellos. Es importante mencionar que en general, en este tipo de toma, las líneas verticales no convergen en el horizonte.


En contraposición al plano picado, un plano contrapicado se realiza desde una posición baja de la cámara apuntando hacia arriba para capturar al sujeto desde una dirección inclinada también hacia arriba. Se utiliza comúnmente para conferir poder o superioridad al personaje u objeto que se está filmando, ya que el ángulo bajo puede hacer que estos parezcan más grandes y dominantes, creando así una sensación de autoridad, fuerza o intimidación. El plano contrapicado también puede generar admiración o incluso temor, como cuando se utiliza para mostrar a un personaje siendo admirado por otro, donde la posición baja de la cámara puede hacer que el primer personaje parezca más grande y poderoso, intensificando así la admiración del segundo personaje.


Un plano nadir es una toma cinematográfica en la que la cámara se sitúa justo debajo del sujeto o escena, apuntando hacia arriba de forma perpendicular al suelo. Usualmente, este tipo de plano se realiza desde una posición en el suelo mirando hacia el cielo, lo que resulta en una perspectiva única y dramática. El objetivo es capturar una vista desde el punto más bajo posible, lo que da la sensación de grandeza y elevación en el objeto o sujeto capturado. El plano nadir se utiliza comúnmente en la cinematografía para dar un efecto dramático a la escena, y también puede utilizarse para mostrar la majestuosidad de un edificio alto o la altura de un árbol gigante. De igual manera, se utiliza en películas de acción y aventura para enfatizar la posición y el poder de un personaje, presentándolos a menudo como grandes y poderosos.


El punto de vista es un recurso cinematográfico que presenta una escena desde la perspectiva del personaje, mostrando lo que esté puede observar. Es ampliamente utilizado en los videojuegos de primera persona y en escenas de acción o suspenso para que el espectador sienta la misma tensión y anticipación que el personaje.

El plano sobre el hombro es una técnica comúnmente utilizada en cine y televisión para mostrar la interacción entre dos personajes. Se trata de una toma en la que la cámara se coloca detrás de uno de los personajes y mira por encima de su hombro hacia la escena o hacia otro personaje. Este encuadre se utiliza comúnmente en diálogos para enfocar la atención del espectador en la persona que habla, mientras que proporciona una perspectiva visual de la reacción del otro personaje.
Además, el plano sobre el hombro puede crear una sensación de profundidad en la escena cuando se combina con otros planos de diferentes distancias focales.

Una vista aérea es una técnica en la que la cámara se sitúa en una posición elevada y lejana al sujeto, mostrando todos los elementos del escenario y simulan la perspectiva que tendría un ave sobrevolando el lugar. En otras palabras, es una toma realizada desde una altura elevada, como un avión, un dron, una grúa o incluso un ave, que ofrece una perspectiva panorámica y completa del sujeto o escena. Este tipo de plano se utiliza para mostrar la extensión o amplitud de una escena o paisaje, así como para resaltar patrones y simetrías en la escena, crear una sensación de distancia y perspectiva, y mostrar el movimiento de personajes u objetos en un espacio determinado. Además, se utiliza en la planificación urbana y la cartografía para estudiar el paisaje y la topografía. La vista aérea también es comúnmente utilizada en documentales y películas de acción.

La composición es una herramienta utilizada para estructurar los elementos visuales y transmitir un mensaje de forma efectiva. Una composición visual es la forma de encuadrar (rodear algo con un marco) un objeto o grupo de objetos, de tal manera que todos ellos se encuentren colocados en una posición visualmente significativa para el espectador.
La composición visual es una herramienta esencial para la creación de imágenes impactantes y efectivas en la transmisión de mensajes visuales. A través de la composición, se pueden organizar los elementos expositivos y estructurarlos de manera que se logre una armonía visual que capte la atención del espectador, ya que implica la selección cuidadosa de los elementos visuales a incluir en la imagen, así como la disposición de estos elementos dentro del encuadre. Al encuadrar un objeto o grupo de objetos, es importante considerar la posición y la relación entre ellos para crear una imagen visualmente coherente y atractiva.
La razón áurea, también conocida como proporción áurea o proporción divina, es una relación matemática que ha sido utilizada desde la antigüedad en el arte y la arquitectura debido a su estética agradable y armoniosa. Esta relación se expresa mediante un número irracional phi ($φ$), siendo aproximadamente 1.6180339887..., valor que se obtiene dividiendo un segmento en dos partes, de tal manera que la razón entre el segmento más grande ($A$) y el más pequeño ($B$) sea igual a la razón entre la suma de ambos ($A + B$) y el segmento más grande ($A$), es decir, $\frac{A}{B} = \frac{(A + B)}{A} = φ$, .
La razón áurea se encuentra presente en muchos aspectos de la naturaleza, como por ejemplo en la disposición de las hojas en una planta, en algunas proporciones del cuerpo humano y en la estructura de muchas formas geométricas. En la arquitectura y el arte, la razón áurea se ha utilizado para diseñar composiciones visualmente atractivas y armoniosas. Una forma común de utilizar la razón áurea en el diseño es a través del llamado rectángulo áureo.
El rectángulo dorado o rectángulo áureo es una construcción que inicia con un cuadrado, del cual se marca la mitad para obtener el radio de un círculo que al ser trazado e intersectado con la extensión del lado del cuadrado, se encuentra una prolongación del lado, de tal manera que el lado junto con la prolongación y el lado original del cuadrado, presentan la razón áurea ().
En el diseño visual, el rectángulo dorado se utiliza como una guía para definir la posición de los elementos de una composición.
Al colocar los elementos de una imagen en relación con el rectángulo dorado, se puede crear una composición equilibrada y armónica que atraiga la atención del espectador hacia un punto focal determinado. De esta manera, se consigue una imagen agradable y placentera de observar ().
La regla de los tercios es una técnica muy popular en la composición visual que consiste en dividir mediante rectas el área de una imagen en tercios, tanto vertical como horizontalmente. Los puntos donde se intersectan las líneas corresponden a lugares visualmente atractivos y naturales para colocar los elementos importantes de la imagen, ya que dirigen la atención del espectador hacia ellos ().

Esta regla se considera una simplificación de la composición utilizando el rectángulo dorado, ya que los puntos de intersección se encuentran muy cerca a los puntos de interés indicados en el rectángulo áureo. Y en la actualidad, muchas aplicaciones fotográficas permiten mostrar estas líneas para tomar fotografías utilizando esta regla.
El Head Room es un método de encuadre que se refiere al espacio libre que hay por encima de la cabeza de un sujeto en una imagen. Es importante considerar el head room al componer una imagen para asegurarse de que la cabeza no quede demasiado cerca del borde superior del encuadre, ya que esto puede afectar la percepción y el equilibrio de la imagen.
Si hay demasiado espacio sobre la cabeza del personaje, puede hacer que la imagen parezca desequilibrada o que la cabeza parezca pequeña. Por otro lado, si no hay suficiente espacio sobre la cabeza, puede parecer que la persona está demasiado cerca del borde superior del encuadre y que la imagen está incompleta. La cantidad adecuada de espacio dependerá del sujeto y del propósito de la imagen, por ejemplo, en un retrato formal de una persona, puede ser apropiado incluir un poco más de espacio para crear una imagen más equilibrada, mientras que en una escena con mucho movimiento o acción, puede ser apropiado tener menos espacio para enfatizar el dinamismo de las acciones.
El nose room (también conocido como leading room o espacio de dirección) es el espacio libre que hay delante de la cara de un sujeto en un encuadre. En otras palabras, se refiere al espacio libre que hay frente a la dirección hacia la cual el sujeto está mirando en la imagen. Es importante considerar el nose room al componer una imagen, ya que puede afectar la percepción y el equilibrio de la misma. Si no hay suficiente espacio libre, puede hacer que la imagen parezca desequilibrada y que la dirección del movimiento no sea clara. Por otro lado, si hay demasiado espacio libre frente a la dirección hacia la cual el sujeto está mirando, puede hacer que la imagen parezca vacía causando que se desvié la atención de la acción principal.
Al igual que con el head room la cantidad de espacio necesario depende del sujeto, la acción y el propósito de la imagen, por ejemplo, en un encuadre donde un personaje mira hacia un objeto o persona en la imagen, es apropiado incluir más espacio para que la dirección del movimiento sea clara y la atención del espectador se dirija hacia el objeto o persona en cuestión.
En cambio, en una imagen en la que el sujeto está inmóvil o no mira hacia ningún objeto en particular, puede ser apropiado incluir menos espacio para crear una imagen más equilibrada. En general, es importante que los personajes tengan suficiente espacio para realizar sus acciones y mostrar adecuadamente sus interacciones en la imagen.
La composición visual es un proceso creativo cuyo objetivo principal es guiar la atención del espectador hacia los elementos más importantes de una imagen. Además de las técnicas ya mencionadas, se pueden emplear otros recursos para lograr este fin, como el uso de luz y sombras, colores, el encuadre de un objeto dentro de otro, las líneas de la escena y también la profundidad de campo (depth of field).
Para dirigir la mirada a través de luz y sombra, es importante crear contraste en la imagen. Esto significa ajustar la diferencia entre las áreas más claras y las más oscuras de la imagen. Por lo general, las áreas más claras tienden a atraer más la atención del espectador que las áreas más oscuras. Iluminar un objeto de manera deliberada es una forma de dirigir la atención del espectador hacia él, ya que los objetos que se encuentran en las sombras tienden a perder protagonismo en la composición.
Esta técnica proviene del manejo de luces en producciones teatrales, donde se utilizan luces y reflectores para resaltar los elementos importantes de la obra y dirigir la atención del público hacia ellos.

El cerebro humano es capaz de encontrar patrones y formas incluso donde no los hay. En este sentido, naturalmente es posible encontrar y seguir líneas en una composición visual. Las líneas son elementos muy útiles ya que pueden crear un efecto de profundidad y perspectiva en la imagen, así como guiar la mirada del espectador hacia el punto focal o de interés, permitiendo dirigir la mirada del espectador hacia regiones donde se desarrollan las acciones importantes.
Este recurso se puede observar en pinturas donde las líneas de perspectiva sutilmente indican la dirección hacia donde el espectador debe dirigir su atención. Es importante recordar que las líneas deben ser utilizadas de manera sutil y no demasiado evidente, ya que si se utilizan líneas demasiado obvias o fuertes pueden distraer al espectador en lugar de guiarlo hacia el punto focal. Las líneas debe estar integradas con el resto de los elementos visuales de la composición para que mantengan la inmersión en la composición

El encuadre es la forma en que el fotógrafo o el cineasta decide qué elementos incluir y excluir en la imagen, y cómo organizarlos dentro del área de la imagen que se compone. Dentro de una toma es posible utilizar rectángulos sutiles, a veces ocultos, para enmarcar partes importantes y resaltarlas dentro de la misma composición.
Por ejemplo, se pueden utilizar marcos de ventanas, espejos o puertas para cubrir (encuadrar) y resaltar localmente los elementos de interés, con esto es posible insinuarle al público cuales son los elementos de interés dentro de la composición, logrando así dirigir la mirada del espectador hacia las regiones de la composición que presentan información importante.

La profundidad de campo (depth of field, DOF), se refiere a la zona de la imagen que aparece nítida y en foco. En otras palabras, es la distancia a la que se encuentra el sujeto enfocado, el cual aparece con nitidez en una toma. Este efecto surge gracias al uso de lentes en cámaras fotográficas, que permiten enfocar elementos a distancias determinadas mediante la modificación de la distancia focal de los propios lentes.
La técnica es efectiva para dirigir la atención, ya que permite una clara separación entre el fondo y el sujeto (o región de interés). En este sentido, por lo general el fondo aparece desenfocado y borroso, indicando claramente que las áreas nítidas son donde ocurre la acción relevante en una toma. Además, gracias a este efecto es posible cambiar la atención entre el fondo y sujeto de forma dinámica, cambiando sutilmente los elementos importantes dentro de la composición.


En la vida real, una cámara tiene ciertas limitaciones físicas en su manejo y operación, como su posición, distancia y movimientos durante una toma. En cambio, una cámara en el mundo de la graficación o animación por computadora no tiene restricciones físicas innatas, lo que la convierte en una ventaja para la realización de tomas complicadas o costosas, como aquellas que involucran acción riesgosa. Sin embargo, esta libertad también puede ser un problema, ya que si los movimientos de cámara no se realizan correctamente, pueden parecer antinaturales y generar aversión en el público. Por lo tanto, es necesario restringir ligeramente la libertad de una cámara virtual para que se comporte de manera similar a una cámara real.
En el cine, se utilizan diferentes movimientos de cámara para filmar una escena con el fin de crear efectos visuales, emocionales y narrativos. Es útil conocer los movimientos para utilizarlos en cámaras para animación por computadora, siendo los más comunes:
El movimiento de cámara Roll se refiere a la rotación de la cámara alrededor de su eje longitudinal, es decir, consiste en girar la cámara sobre el eje que se forma entre la lente y el sujeto, lo que provoca que la cámara gire sobre sí misma en sentido horario o antihorario.
Este movimiento se utiliza comúnmente para crear una sensación de desorientación o confusión en el espectador, o para establecer una transición entre dos escenas.

El movimiento de cámara Paneo o Panning se refiere al movimiento horizontal de la cámara sobre su eje vertical, y consiste en rotar la cámara de un lado a otro por medio de un movimiento horizontal, manteniendo su posición en el eje horizontal.
Este movimiento se utiliza comúnmente para seguir a un personaje u objeto en movimiento, o para mostrar un paisaje amplio o panorámico.
El movimiento de cámara Tilt se refiere al movimiento vertical de la cámara sobre su eje horizontal, y consiste en que la cámara se mueve hacia arriba o hacia abajo, manteniendo su posición en el eje vertical.
Este movimiento se utiliza comúnmente para mostrar la altura o profundidad de una escena, o para seguir a un objeto que realiza un movimiento vertical, como un personaje que salta o un objeto que cae.
El movimiento de cámara dolly se refiere al movimiento físico de la cámara hacia adelante o hacia atrás, acercándose o alejándose respecto al sujeto, a menudo este movimiento se realiza sobre un carril para controlar y restringir el movimiento.
Por lo general, este tipo de movimiento de cámara se utiliza para seguir a un personaje que se desplaza por el escenario, con la finalidad de crear una sensación de avance o retroceso en la acción o para destacar un objeto en particular.

El movimiento de cámara pedestal se refiere al movimiento físico de la cámara hacia arriba o hacia abajo, a menudo con la ayuda de un pedestal o grúa. Se utiliza para mostrar la altura de una escena, o para enfatizar un objeto en particular en la toma mediante un recorrido vertical que sigue su altura.

El movimiento de cámara pista o track se refiere al movimiento físico de la cámara a lo largo de un carril o pista fija, con la cámara observando la escena de manera lateral respecto a la pista.
Este movimiento se utiliza a menudo para seguir a un personaje o para capturar una escena en movimiento, y puede realizarse en el suelo o en el aire.

El Zoom se refiere al ajuste del enfoque de la cámara para acercar o alejar la imagen sin cambiar la posición física de la cámara. Esto se logra mediante la variación de la longitud focal del lente, lo que permite que el objeto parezca más grande o más pequeño en la toma.
El movimiento se utiliza a menudo para destacar un objeto o detalle específico en la toma, o para cambiar el enfoque de atención del espectador. Sin embargo, el uso excesivo del zoom puede generar distorsión o pérdida de calidad en la imagen, y en algunas ocasiones puede desorientar al público.
El movimiento manual implica mover la cámara de manera libre en cualquier dirección, sin la ayuda de equipo especializado. Se utiliza en películas de acción y terror para sumergir al público en los eventos, presentándolos de forma más natural y similar a lo que se vería en la realidad. Este tipo de movimiento puede incluir paneos, tilts y dollies, pero realizados con la cámara sostenida a mano en lugar de montada en un trípode u otro soporte. Sin embargo, es importante no abusar de este tipo de movimientos ya que pueden desorientar y cansar al público.
El rack focus, también conocido como roll focus, se refiere al cambio intencional del enfoque de la cámara durante una toma para desplazar la atención del espectador de un objeto (o personaje) a otro. Esta técnica se basa en la manipulación de la profundidad de campo y se utiliza a menudo en películas y series de televisión para crear un efecto dramático y destacar elementos importantes de la escena.


La regla de los 180 grados es una técnica fundamental en el cine para mantener la coherencia espacial durante la filmación de escenas. Indica que la cámara debe situarse siempre en un lado de un eje imaginario que atraviesa a los personajes, conocido como línea de acción.
Esta regla asegura que los personajes no cambien de posición relativa de forma arbitraria, manteniendo un ángulo de filmación de 180 grados, ya que sí la cámara cambia de lado de la línea de acción, los personajes parecerán invertidos, lo que puede confundir al espectador y dificultar el seguimiento de la narrativa.
Durante la etapa de edición, se produce la unión de todos los elementos que se han creado durante la producción, dando como resultado el producto final. En esta fase, se lleva a cabo la integración de todas las secuencias y tomas por medio de cortes y transiciones que permiten enlazar lógicamente los diferentes acontecimientos de la producción.
Un corte se define como un cambio, usualmente abrupto, en las imágenes que sirve para crear una progresión entre las distintas tomas y secuencias de una producción. Existen varios tipos de cortes que se pueden utilizar, entre los cuales se incluyen:
Un corte sobre la acción se produce cuando se cambia de plano durante una misma acción. Esta técnica de edición implica cortar en un punto en el que la acción está en movimiento, pero sin interrumpirla. De esta manera, se pueden capturar diferentes perspectivas de la misma acción utilizando diversas cámaras, lo que resulta útil para enfatizar diferentes elementos de la misma.
Por ejemplo, si un personaje está corriendo y se corta la acción en un momento específico, el siguiente plano mostrará al mismo personaje corriendo desde un ángulo diferente, lo que crea una sensación de continuidad y fluidez en la acción. El punto clave es que la acción se presenta de forma continua y sólo cambia el punto de vista desde donde se muestra.

En el cine, la televisión y otras formas de medios audiovisuales, se utiliza la técnica de corte con inserto para enfatizar la acción principal de una escena. Este corte consiste en interrumpir temporalmente la acción principal insertando otras tomas o escenas relacionadas con ella, sin detener por completo la escena principal. Por lo general, las tomas complementarias no ocurren en el mismo escenario que la acción principal y se utilizan para proporcionar contexto adicional o destacar elementos importantes de la historia.
El corte con inserto implica cambiar a un plano que no está directamente relacionado con la acción principal de la escena. Por ejemplo, en una escena de una conversación, se puede cortar a un plano del reloj para mostrar el paso del tiempo o a un plano de un objeto para enfatizar su importancia en la historia.

El montaje cruzado o en paralelo es una técnica de edición en la que se muestran dos o más acciones que ocurren simultáneamente, por lo general en lugares diferentes, con el objetivo de presentar de manera consecutiva estas acciones que suceden al mismo tiempo. El montaje cruzado tiene como finalidad unir estas diferentes acciones para que el espectador pueda percibir una secuencia coherente de eventos simultáneos.
Esta técnica se utiliza para aumentar la tensión y la emoción en la narrativa, especialmente en escenas de acción o suspenso. Por ejemplo, si un personaje está en peligro y otro personaje está intentando salvarlo, se pueden mostrar ambas acciones en paralelo para aumentar la tensión y crear una sensación de urgencia. Al utilizar el montaje cruzado, se logra que las diferentes tomas parezcan ocurrir simultáneamente, aunque en realidad se hayan filmado por separado y en diferentes lugares.

Un Jump cut es un tipo de corte que implica saltar abruptamente de un plano a otro sin una transición suave. Durante un jump cut, se utilizan dos o más secuencias de tomas sobre el mismo sujeto, mostrando una acción desde diferentes puntos de vista. Generalmente, las tomas son realizadas con posiciones de cámara ligeramente diferentes, y la acción principal suele cortarse brevemente.
Este tipo de corte, en comparación al corte sobre la acción, permite interrumpir la acción que se está presentando de tal manera que no se muestra de forma continua, aunque se mantiene la coherencia de la acción que se quiere presentar. Esto es útil para economizar el tiempo requerido para mostrar una acción sin perder la coherencia en la presentación. Además, este efecto puede ser utilizado para crear un efecto disonante o para mostrar la falta de coherencia o continuidad en una escena.

La técnica de continuidad cinematográfica, también conocida como match cut, consiste en cortar de una escena a otra que tiene una relación visual o temática. Esta técnica utiliza tomas diferentes para empatar o relacionar la acción de una escena con la siguiente a través de elementos gráficos, de continuación en el movimiento o con sonido.
Los cortes de este tipo permiten unir secuencias y tomas con acciones o eventos desconectados, evitando cortes abruptos entre las escenas. Por ejemplo, al pasar de una escena en la que una persona cierra una puerta a otra en la que una persona diferente abre una puerta distinta, se puede utilizar esta técnica para unir las escenas o resaltar un tema o simbolismo.

La transición smash cut presenta de manera abrupta una toma que reemplaza sin una transición suave la toma anterior. Este tipo de transición se utiliza para enfatizar alguna acción particular y ligar las escenas de tal manera que el corte, aunque súbito, no genere desconcierto en el espectador.
A diferencia de la continuidad cinematográfica (o match cut), la transición de una toma a la siguiente suele ser más cruda y menos elaborada, y a menudo se utiliza para crear un efecto sorpresa o para enfatizar un momento dramático. Por ejemplo, si una escena establece una atmósfera pacífica y tranquila, se puede utilizar un smash cut para mostrar repentinamente una escena de acción intensa.

El fundido o disolución consiste en reducir gradualmente dos tomas diferentes, mezclando las imágenes en una sola, lo que permite encadenar diferentes secuencias simplemente pasando suavemente de una a otra. En otras palabras, esta técnica implica superponer gradualmente dos planos para crear una transición suave entre ellos.
Esta técnica suele utilizarse para mostrar cómo cambia algún escenario o personaje con el paso del tiempo. Al igual que el match cut, la transición de fundido permite unir secuencias y tomas desconectadas de forma suave y gradual.
El fundido a negro es una técnica cinematográfica que consiste en desvanecer gradualmente un plano desde la oscuridad al inicio de una escena (fade in) o hacia la oscuridad al final de una escena (fade out), pasando de las imágenes nítidas a un color negro o viceversa. Esta técnica es similar al fundido (dissolve), pero en lugar de pasar directamente a la siguiente secuencia, primero se muestra un color sólido antes de presentar la siguiente toma. El fundido a negro puede ser utilizado para establecer la atmósfera o indicar el paso del tiempo en la narrativa.
Esta transición sencilla permite suavizar los cambios abruptos entre escenas con diferentes locaciones o acciones. Al igual que con el fundido o disolución, el fundido a negro puede ayudar a encadenar diferentes secuencias simplemente pasando suavemente de una a otra. Esta técnica de transición también es una manera efectiva de cerrar una escena y preparar al espectador para la siguiente.

Una transición iris es una técnica en la que se muestra una figura (usualmente un círculo) que se va abriendo para mostrar la siguiente escena o se va cerrando para ocultar la escena actual. Esta técnica implica desvanecer gradualmente un plano hacia un círculo negro, creando una transición suave entre los planos.
Esta transición simula el efecto del obturador de una cámara al cerrarse o abrirse. Se utiliza para concluir o iniciar una escena dirigiendo la atención del espectador hacia algún elemento importante para la narración.
Hay que considerar que la figura puede tener cualquier forma, no solamente un círculo. Incluso puede ser un elemento que ya se encuentra en la escena y desde el cual se genera la transición.
La transición de cortina consiste en reemplazar una toma o secuencia haciendo un barrido a través del cuadro de la composición. Con el barrido se intenta dirigir la atención del espectador hacia una dirección específica con el objetivo de ayudar a identificar los elementos importantes de la siguiente escena. Es posible realizar el barrido en varias direcciones o formas, no solamente en una única dirección. Lo importante de esta transición es que se produce una superposición de la escena actual con la siguiente, donde ambas escenas se complementan. Por ejemplo, una transición de cortina vertical podría mostrar una escena que se desvanece gradualmente hacia arriba, mientras que la siguiente escena aparece gradualmente a medida que se desliza hacia abajo. Esta transición puede tener un efecto dramático, ya que puede simbolizar un cambio de tiempo, lugar o tema en la narrativa.
El corte invisible es una técnica en la que dos escenas se combinan para crear una apariencia de continuidad visual sin utilizar una transición aparente. Su objetivo es pasar desapercibido por el público y encadenar diferentes tomas para dar la sensación de continuidad en las acciones presentadas. Este tipo de corte no detiene ni interrumpe la narrativa, y aunque se cambie de ambientes o escenarios, se presenta un conjunto de acciones de forma ininterrumpida, dando la sensación de que ocurren en un mismo ambiente. Normalmente, este corte se logra utilizando una misma cámara para tomar todas las acciones de forma ininterrumpida.
Aunque se utiliza para hacer que un movimiento fluya sin interrupciones, el corte invisible difiere del corte en acción porque se pueden utilizar escenas que tienen una posición diferente en el espacio, el tiempo o incluso una diferencia de cámara. El objetivo es hacer que la edición parezca natural y fluida, como si no tuviera cortes en absoluto.

Estos cortes se relacionan principalmente con el audio y toman su nombre de los marcadores utilizados en los programas de edición de video para determinar si el audio sigue de la escena actual a la siguiente, o si se usa el audio de la siguiente escena durante la escena actual.
Un corte J implica superponer el audio de la siguiente escena al final de la escena anterior, es decir, es una transición de audio en la que los sonidos de la siguiente toma comienzan antes y se sobrepone a la toma actual. En contraste, un corte L implica superponer el audio de una escena al inicio o al final de la siguiente escena, creando una transición suave entre ambas, es decir, es una transición de audio en la que el sonido de la toma anterior continúa en la siguiente toma. Este tipo de cortes se utilizan comúnmente en conversaciones alternando los personajes involucrados durante el diálogo para mostrar a los interlocutores.

Recordando la jerarquía de cuatro niveles del desarrollo de una animación que se presentó con anterioridad ().
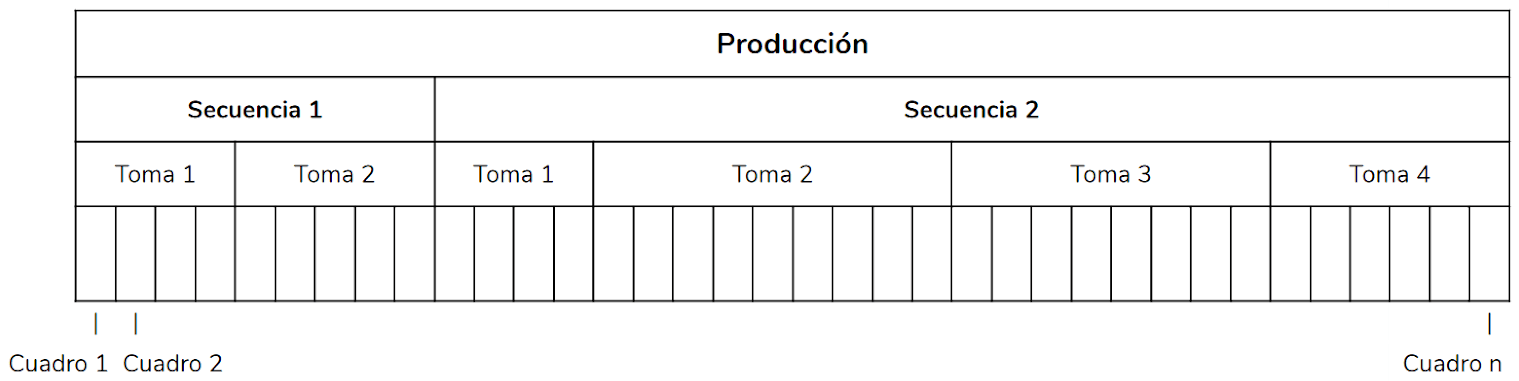
En el nivel más bajo se encuentra un cuadro o fotograma de la animación, que corresponde simplemente a una imagen. Comúnmente en una computadora, una imagen se almacena y representa mediante un conjunto de píxeles, aunque existen otros tipos de mecanismos para almacenar imágenes. La representación más común y la que se utiliza para dibujar en una pantalla es a través de un arreglo de píxeles.
La palabra píxel proviene del acrónimo en inglés picture element, que significa elemento de imagen. Un píxel es el componente más pequeño que se puede representar en una imagen digital o en una pantalla. Los píxeles físicos en una pantalla pueden tener diferentes formas, como pequeños rectángulos o círculos que cubren toda la superficie ().
Debido a que los píxeles se han estandarizado y hay una gran cantidad de dispositivos con pantalla, es posible hablar de la resolución o número de píxeles en una pantalla.
La resolución corresponde al número máximo de píxeles que una pantalla puede mostrar, es decir, el número de píxeles físicos que la componen. Es normal escuchar hablar de resoluciones como 720 o 1080, o actualmente 4K u 8K, ¿pero qué significan estos números?
Los números de una resolución indican la cantidad de píxeles que se encuentran verticalmente, por ejemplo una resolución de 480, significa que la pantalla cuenta con 480 píxeles en la vertical o 480 píxeles de alto.
Las resoluciones de pantalla más comunes en la actualidad son:
Además de la resolución, es importante considerar la densidad de píxeles en la pantalla, que se refiere al número de píxeles por unidad de área, generalmente medida en pulgadas. La densidad de píxeles afecta la apariencia de la imagen y es especialmente relevante en pantallas de diferentes tamaños.
Por ejemplo, una pantalla FullHD (1920×1080) con un tamaño de 32 pulgadas tendrá píxeles más pequeños y densamente distribuidos que una pantalla FullHD de 65 pulgadas, aunque ambas tengan la misma resolución de 1080 píxeles en vertical.
La resolución es un factor clave en la producción de animaciones, ya que el medio final es una secuencia de imágenes que se compilan en un archivo de video. La resolución determina el tamaño de las imágenes generadas y afecta el detalle de la animación. Una resolución mayor permite un mayor nivel de detalle, pero también aumenta el tiempo necesario para calcular cada uno de los píxeles en la imagen, lo que puede repercutir en el tiempo total de producción. Por lo tanto, la elección de la resolución debe equilibrar la calidad deseada con la eficiencia en la producción.
Hay dos formas comunes de almacenar imágenes en una computadora: mapas de bits (o imágenes raster) e imágenes vectoriales.
Un mapa de bits (o imagen raster) es una estructura de datos en forma de matriz que almacena los píxeles que representan la imagen (). Estas imágenes almacenan información como valores numéricos discretos en posiciones fijas dentro de la matriz. De cierta forma, estas imágenes reflejan la manera en que los píxeles físicos están ubicados en una pantalla, y se puede hablar también de la resolución de una imagen.
Los mapas de bits se utilizan ampliamente para almacenar fotografías y gráficos que contienen gran cantidad de detalle. Y son eficientes para visualizarse en una pantalla, debido a la especialización del hardware gráfico. La principal desventaja de los mapas de bits es que se necesitan resoluciones altas para mostrar elementos con mayor calidad visual, de lo contrario, pueden aparecer artefactos o defectos visuales.
Una imagen vectorial es una imagen cuya representación interna está dada por descripciones basadas en constructores geométricos, como puntos, líneas y curvas. Estos constructores definen los elementos que componen la imagen y, al ser descripciones matemáticas, son independientes de la resolución de la pantalla donde se muestran.

Las imágenes vectoriales permiten mostrar una gran calidad visual y adaptarse a diversas resoluciones de pantalla, lo que las hace versátiles al momento de crear representaciones visuales que puedan utilizarse en dispositivos de diferentes tamaños.
La desventaja de las imágenes vectoriales es que son más costosas de dibujar, ya que la descripción matemática que las define debe ser interpretada para determinar qué píxeles deben dibujarse en la pantalla, y entre más objetos tenga la imagen vectorial, más tiempo tardará en dibujarse.
En general, el tipo de imagen que se debe utilizar dependerá del uso y del medio de presentación.
Si se desea utilizar imágenes en diversos dispositivos, como en páginas web, aplicaciones o videojuegos 2D, hay una tendencia creciente en el uso de imágenes vectoriales (con un estilo de diseño plano o flat design), ya que permiten crear gráficos de alta calidad que se adaptan a diversas resoluciones y densidades de pantalla, lo que hace que su creación sea más económica y eficiente.
Por otro lado, para videos, fotografías y texturas de modelos 3D, se utilizan de mapa de bits, ya que permiten almacenar una gran cantidad de información y se aproximan más a la forma en que funciona el hardware gráfico, lo que las hace más eficientes en su uso y visualización.
Haciendo un pequeño paréntesis, dentro de la categoría de imágenes de mapas de bits, se encuentra el pixel art, una forma de arte digital que se centra en representar información gráfica utilizando la mínima cantidad de píxeles y colores. En otras palabras, es una técnica de creación de imágenes digitales que utiliza píxeles individuales y una paleta específica para recrear una estética retro que evoca los videojuegos y la tecnología de los años 80 y 90.
Este estilo tiene sus orígenes en los videojuegos clásicos, donde la baja resolución de los sistemas obligaba a los creadores a utilizar la cantidad justa de memoria necesaria para representar los elementos gráficos del juego, intentando construir personajes y mundos visualmente atractivos.
En la actualidad, el pixel art va más allá de la simple creación de gráficos de juegos y se ha convertido en un medio de expresión creativa por derecho propio. Esta técnica se utiliza en videojuegos, animaciones, diseño de personajes, arte digital y otros medios.
Aunque la tecnología ha avanzado considerablemente y es posible crear imágenes de alta resolución, el pixel art sigue siendo popular debido a que ofrece una estética distintiva y retro, lo que permite crear imágenes con un estilo artístico único. Además, el pixel art es importante porque permite a los artistas trabajar con restricciones creativas, como una paleta de colores limitada y un número reducido de píxeles para representar la información visual, por lo que fomenta la creatividad en los artistas, principalmente para encontrar formas de transmitir información visual utilizando una cantidad limitada de elementos.
Este estilo puede resultar en un arte más simple pero si se hace bien también suele ser más efectivo, ya que puede ser fácilmente reconocido y apreciado por los espectadores.
Recordando un poco lo presentado en la sección “
Por lo general, la representación de un color en un píxel se divide en sus componentes principales, es decir, la cantidad de rojo, verde o azul que lo conforman. A cada una de estas cantidades se les conoce como canales de color, lo que significa que hay un canal rojo, uno verde y uno azul para cada píxel de una imagen. Además de la información de color, también se suele tener la transparencia u opacidad de un píxel en un canal conocido como el canal alfa.
La cantidad de bits que se utilizan para representar los canales de color de una imagen se conoce como la profundidad de color de la imagen. Esto es importante ya que determina el número total de colores diferentes que una imagen puede representar y almacenar.
Es común escuchar hablar de gráficos de 8 bits, 16 bits o 24 bits, esto significa que para almacenar la información de color de un píxel se utiliza el número de bits indicado, distribuidos entre sus diferentes canales de color. Por ejemplo, para una imagen de 32 bits con transparencia, se tienen tres componentes de color junto con el canal alfa, cada uno de ellos con 8 bits para almacenar su información, lo que da un total de 4 canales × 8 bits = 32 bits.
La teoría del color es un conjunto de principios y directrices que explican cómo los colores interactúan entre sí y cómo son percibidos por el ojo humano, es esencial en campos como el arte, el diseño gráfico, la moda, la publicidad y la decoración de interiores, ya que ayuda a los profesionales a crear combinaciones de colores efectivas y atractivas. Para hablar de estas reglas, se considera la forma en la que se representan o almacenan los colores, existiendo diversos modelos para hacerlo.
El modelo tradicional de color también conocido como modelo RYB (Red, Yellow, Blue, ), se utiliza en el arte y la pintura. Este modelo se basa en tres colores primarios: rojo, amarillo y azul; y es un modelo sustractivo basado en pigmentos. Se ha utilizado ampliamente en la educación artística elemental y en las artes plásticas, como la pintura. Según este modelo, todos los colores se pueden crear mezclando los tres colores primarios de pigmentos. Por ejemplo, la mezcla de rojo y amarillo crea naranja, la mezcla de rojo y azul crea morado y la mezcla de amarillo y azul crea verde, los colores secundarios (naranja, morado y verde) se encuentran entre los colores primarios en el círculo cromático.

El modelo RYB se basa en la absorción de la luz en lugar de su emisión, es decir, es un modelo sustractivo, donde los pigmentos de color se mezclan físicamente en la superficie de un soporte, como el papel o la tela, y los colores resultantes que se perciben son los que se reflejan del material hacia los ojos. Este modelo presenta algunas limitaciones en los colores que puede representar, ya que por ejemplo, no puede reproducir con precisión algunos colores, como el magenta y el cian, que se utilizan por lo general en la impresión en cuatro colores.
A pesar de sus limitaciones, el modelo RYB sigue siendo importante en la educación artística y en la práctica de la pintura, ya que permite a los artistas crear una amplia gama de colores utilizando una paleta limitada de pigmentos.
El modelo CMYK (Cyan, Magent, Yellow, Key, ) también es un modelo de colores sustractivo que se utiliza principalmente en la impresión de medios como revistas, periódicos, folletos y carteles. Una hoja blanca se percibe de este color ya que todas las longitudes de onda de la luz son reflejadas al tocar su superficie, sin embargo, cuando se le aplica algún pigmento este absorbe longitudes de ondas especificas a su color.
Idealmente utilizando los colores cian, magenta y amarillo, sería suficiente para representar cualquier color en un medio impreso, pero en la práctica, al combinar estos tres colores lo que se obtiene es un color gris muy oscuro en lugar del color negro esperado. Por esta razón, las impresoras incorpora un color adicional (key), usualmente el negro, para lograr presentar correctamente todos los colores.

El modelo de color RGB (Red, Green, Blue, ) se utiliza en la tecnología digital para mostrar colores en pantallas electrónicas como monitores, proyectores, teléfonos móviles y otros dispositivos electrónicos. Este modelo representa la composición de colores en términos de la intensidad de los colores primarios de la luz, es decir, el rojo, verde y azul. Se le llama modelo aditivo de colores ya que las diversas longitudes de onda de los colores se suman o mezclan para obtener el color final que se percibe.
El modelo RGB se utiliza en una amplia variedad de aplicaciones, desde la edición de fotos y videos hasta la creación de gráficos y animaciones. Es importante mencionar que los colores que se ven en una pantalla de computadora o dispositivo móvil pueden verse diferentes cuando se imprimen en papel, debido a las limitaciones de la gama de colores del modelo RGB y a las diferencias en la calibración de los monitores y las impresoras.

Existen otros modelos que buscan simplificar la forma en que una persona especifica los colores. El modelo HSV, que significa tonalidad (Hue), saturación (Saturation) y valor (Value), así como el HSB, que se refiere a tonalidad (Hue), saturación (Saturation) y brillo (Brightness), o el HSL, que se basa en tonalidad (Hue), saturación (Saturation) y luminosidad (Lightness), son modelos de color que se enfocan en la percepción subjetiva que tienen los seres humanos sobre los colores, en lugar de solo descomponerlos en colores básicos o primarios.
El término tonalidad (hue) se refiere a la percepción subjetiva del color, es decir, a la forma en que los humanos perciben diferentes longitudes de onda de la luz. Usualmente este valor se especifica por medio del círculo cromático, donde se mide en grados que van de 0 a 360, y cada valor representa el color en sí mismo.

La saturación (saturation), por su parte, se refiere a la pureza o intensidad del color. Una saturación alta indica que el color es más vibrante e intenso, mientras que una saturación baja indica que el color es más apagado o desaturado. La saturación se mide por lo general con porcentajes, que van desde 0% (grisáceo) hasta 100% (color puro). Entonces la saturación especifica la intensidad del color y su pureza.

Por último, la tercera componente correspondiente al valor (value), el brillo (brightness) o la luminosidad (lightness), se refiere a la cantidad de luz presente en un color La diferencia principal entre los diferentes modelos (HSV, HSB y HSL) se encuentra en la forma de calcular esta tercera componente, pero en el fondo intentan representar la información que proporciona la intensidad de luz del propio color.
Un brillo alto indica que el color es más claro o luminoso, mientras que un brillo bajo indica que el color es más oscuro o apagado. El brillo se mide en porcentaje, desde 0% (negro) hasta 100% (blanco) indicando si el color es claro u oscuro, es decir, la intensidad luminosa del color.

La armonía del color se refiere a la combinación de colores que resulta agradable a la vista y que funcionan bien al usarlos en conjunto dentro de una composición. En diseño gráfico, esta técnica se utiliza para crear diseños visualmente atractivos y coherentes, debido a que el color es un aspecto fundamental del diseño, y puede influir en la emoción, el estado de ánimo y la percepción de una obra.
La armonía del color se basa en el uso adecuado de tonalidad, saturación y brillo para crear una sensación visual equilibrada y agradable en una composición. Existen diversas reglas para crear paletas de colores armónicas, las cuales se fundamentan en el uso del círculo cromático para construir sus combinaciones.
El círculo cromático es una distribución circular de los colores según su matiz o tonalidad, en donde se representan los colores primarios y sus derivados (secundarios y terciarios). Existen dos tipos de círculos cromáticos que se utilizan ampliamente en la actualidad, uno utiliza los colores primarios de pigmentos, es decir, el rojo, el amarillo y el azul (), y es utilizado por artistas que utilizan medios físicos, como la pintura, ya que facilita la combinación de colores en estas disciplinas.

Por otro lado también existe el círculo cromático que utiliza los colores primarios de la luz, es decir, el rojo, el verde y el azul (), siendo ampliamente utilizado en el diseño electrónico, como el que se muestra directamente en una pantalla.

Hay que mencionar que los colores utilizados para construir el círculo cromático pueden variar dependiendo del medio para el que se utilice, particularmente se pueden construir utilizando colores que no colores puros, es decir, tiene valores en la saturación o el brillo, que alteran el color.
El círculo cromático es una herramienta importante para entender y aplicar la armonía del color, permitiendo elegir la combinación de colores adecuada para un diseño, formando paletas de colores las cuales son llamadas armonías cromáticas.
Una paleta monocromática se compone de un solo color en diferentes saturaciones para generar otros colores variando el brillo del color base. Por ejemplo, si se elige el color azul como base, se pueden incluir tonos más claros como el celeste y tonos más oscuros como el azul marino. Esta paleta es fácil de crear y suele ser muy armoniosa, pero puede resultar monótona si se utiliza en exceso, ya que todos los colores son de la misma familia cromática (o misma tonalidad).

Una paleta de colores análogos se compone de colores adyacentes en el círculo cromático, lo que genera una sensación de armonía y cohesión. Por ejemplo, se puede utilizar una paleta que incluya el amarillo, el amarillo-verde y el verde, esta de combinación de colores puede ser muy efectiva para crear diseños naturales y relajantes. Por lo general este tipo de paleta funciona bien, ya que los colores son bastante parecidos entre sí, debido a su cercanía en el círculo cromático, por lo que a veces carecen de contraste para resaltar elementos.

Una paleta de colores complementarios se compone de colores opuestos en el círculo cromático, lo que genera un alto contraste y una sensación de dinamismo. Por ejemplo, se podría utilizar una paleta que incluya el rojo y el verde, o el azul y el naranja. Esta paleta puede ser muy efectiva para llamar la atención y crear diseños impactantes, ya que utiliza colores opuestos para generar un contraste visual. Hay que considerar que es posible incluir el color complementario en una paleta de colores análogos, justamente para proporcionar contraste.

La paleta de colores complementarios divididos utiliza dos colores adyacentes al color opuesto en el círculo cromático. Por ejemplo, se puede utilizar una paleta que incluya el azul, el naranja y el amarillo-verde, con lo que se obtiene una paleta que crea una sensación de equilibrio y armonía, con un poco más de variedad que la paleta complementaria básica, aunque el contraste aquí es más sutil.

Una paleta tríada se construye a partir de un triángulo equilátero en el círculo cromático, tomando los colores en los vértices para obtener una tripleta de colores que se complementan entre sí. Es decir, se utilizan tres colores equidistantes en el círculo cromático. Por ejemplo, se puede utilizar una paleta que incluya el rojo, el amarillo y el azul, esta combinación de colores crea una sensación de equilibrio y puede resultar muy dinámica si se utilizan tonos brillantes y saturados.

Una paleta tetraédrica utiliza cuatro colores equidistantes en el círculo cromático, lo que crea una sensación de equilibrio y variedad. Se construye a partir de un rectángulo sobre el círculo cromático y tomando los colores en los vértices. Por ejemplo, al usar el rojo, el amarillo, el verde y el morado, se tiene una paleta de colores que permite crear diseños vibrantes y coloridos.

La teoría del color incluye el concepto de temperatura del color (), que se refiere a la sensación que evoca un color en el espectador. Los colores cálidos, como el rojo y el amarillo, se asocian con la energía, la emoción y el movimiento, mientras que los colores fríos, como el azul y el verde, se asocian con la calma, la serenidad y la estabilidad. La temperatura del color describe la apariencia cálida o fría de un color en particular y se relaciona con la luz visible, esta apariencia se determina por la longitud de onda de la luz que se emite y se mide en grados Kelvin ($K$). Los colores se pueden clasificar en dos grupos principales en términos de temperatura: cálidos y fríos. Los colores cálidos tienen una apariencia de fuego o sol, como el rojo, el naranja y el amarillo, mientras que los colores fríos tienen una apariencia de hielo o agua, como el azul, el verde y el violeta.

La temperatura del color puede afectar la percepción emocional de un diseño, ya que los colores cálidos tienden a evocar emociones pasionales (o fuertes) mientras que los colores fríos generan una sensación de serenidad. Por ejemplo, en fotografía, la temperatura del color puede afectar la apariencia de una imagen, si se utiliza una luz fría, la imagen puede tener un tono azul o verde, mientras que si se utiliza una luz cálida, la imagen puede tener un tono amarillo o naranja. Además, la temperatura del color puede influir en la percepción de la piel de una persona, una iluminación cálida puede hacer que la piel parezca más cálida y suave, mientras que una iluminación fría puede hacer que la piel parezca más dura y fría.
En diseño gráfico, la temperatura del color se puede utilizar para crear una sensación de profundidad y espacio. Por ejemplo, si se utiliza un esquema de colores cálidos en un diseño, se puede generar la sensación de que el diseño se acerca al espectador, mientras que si se utiliza un esquema de colores fríos, se puede crear la sensación de que el diseño se aleja. En resumen, la temperatura del color es un concepto importante que se relaciona con la apariencia de un color, la percepción emocional y la creación de profundidad y espacio en el diseño gráfico.
En el diseño se trabaja con la percepción, las emociones y las necesidades de los usuarios, por lo que es útil conocer los principios que disciplinas como la psicología puede ofrecer para desarrollar diseños más efectivos. La teoría de la Gestalt a veces llamada la psicología de la forma, es una teoría que se enfoca en la percepción humana y su capacidad para crear imágenes mentales coherentes de sí mismos y del mundo que les rodea. Esta corriente psicológica coloca al individuo y su percepción de la realidad como el epicentro en la toma de decisiones y surgió en Alemania a principios del siglo XX de la mano de Max Wertheimer, Wolfgang Köhler, Kurt Koffka y Kurt Lewin.
Gestalt es una palabra en alemán que significa patrón, figura o forma. La teoría de la Gestalt se resume en la frase:
“el todo es más que la suma de sus partes”
Esto significa que la percepción humana involucra un proceso mucho más amplio y complejo que simplemente la recepción individual de información por parte de los sentidos.
La teoría de la Gestalt ha dado lugar a principios conocidos como las leyes de la Gestalt, que se utilizan como guía para crear un diseño efectivo, donde para que un diseño sea funcional, no basta con considerar los elementos visuales de forma individual, sino que es necesario construir el diseño teniendo en cuenta la totalidad de sus partes de forma integral. Estas leyes intentan explicar por qué el cerebro percibe los patrones de una manera determinada, ya que el cerebro organiza los datos captados por los sentidos para crear internamente un orden en la percepción de las cosas, de esta manera se intenta dar sentido a lo que se percibe mediante atajos y heurísticas mentales, obteniendo información relevante de la manera más rápida posible. A continuación se enlistan las leyes de la Gestalt asociadas al diseño:
La ley de semejanza establece que los elementos que comparten similitudes son agrupados y se consideran como una unidad o conjunto. Específicamente, se refiere a la tendencia que se tiene de agrupar elementos visuales que comparten características similares, como colores, formas o tamaños, dando como consecuencia, que los elementos que presentan rasgos semejantes sean percibidos como un grupo o conjunto homogéneo.

La ley de continuidad establece que la vista es guiada por la sucesión de elementos que siguen una línea (recta o curva), incluso cuando la línea presenta interrupciones en su continuidad. Esto significa que se tiende a percibir como una unidad aquellos elementos visuales que están alineados, aunque presenten interrupciones, lo que se interpreta como una sola entidad.

La ley de cierre establece que cuando se observa una figura incompleta, el cerebro tiende a completarla para obtener una forma completa. Es decir, se tiende a completar visualmente las formas o patrones que no están completamente cerrados, lo que provoca la tendencia a incluir información para cerrar las figuras abiertas y completar su forma.

La ley de proximidad establece que los objetos cercanos se perciben como un solo objeto, mientras que objetos alejados o separados se perciben de forma individual. En este sentido, se indica que se tiende a agrupar elementos visuales que están cerca entre sí, lo que permite percibir entidades más complejas formadas por elementos cercanos.

La ley de figura y fondo establece que la percepción de un objeto puede variar dependiendo del interés y la atención del observador, lo que permite una mayor participación del espectador en la interpretación y recepción del mensaje transmitido por la composición visual. En gran medida, esta ley establece la tendencia a percibir un objeto como una figura que se destaca del fondo, siendo la figura el objeto principal y el fondo el espacio en blanco que lo rodea.

La ley de simetría y orden establece que se tiende a percibir como más atractivos y organizados aquellos elementos visuales que son simétricos o están bien ordenados. Esto significa que estos elementos se perciben como parte de un mismo bloque de información y son más fáciles de interpretar.

La ley de simplicidad, también conocida como ley de la buena forma o ley de la pregnancia, establece que el cerebro reduce o simplifica lo que percibe para quedarse con las formas esenciales que lo componen, optimizando así el reconocimiento de formas y patrones visuales. En este sentido, se observa que la mente humana tiende a percibir más fácilmente las formas simples y organizadas que las complejas y caóticas, con el objetivo de buscar una forma de organización eficiente y sencilla para procesar y comprender la información visual.

La ley de dirección común explica que los objetos que forman un patrón en una misma dirección son percibidos como un solo ente. En esencia, la dirección de los objetos proporciona cohesión entre ellos, agrupándolos como un único elemento.

La ley de la experiencia se basa en la idea de que la percepción del mundo varía y depende de las vivencias y experiencias previas de cada individuo. Esta ley establece que la percepción visual está influenciada por las experiencias previas y la memoria, ya que el cerebro utiliza estos conocimientos previos para interpretar la información visual y darle sentido.

En los siguientes videos se puede encontrar información adicional sobre la teoría de la Gestalt aplicado a la percepción visual.




Es importante mencionar que estas leyes se presentan ligadas al contexto psicológico que estudia la teoría de la Gestalt, y que en el área del diseño han sido sintetizadas y destiladas para crear un conjunto de principios que ayudan al desarrollo de diseños visuales efectivos, estos se conocen como los principios básicos del diseño.
El diseño se encarga de combinar adecuadamente los elementos visuales, como el texto, las imágenes y los símbolos, para presentar la información de manera efectiva. Para ello, se utilizan pautas específicas que se conocen como los seis principios del diseño: balance, proximidad, alineación, repetición, contraste y espacio en blanco. Estos principios son herramientas esenciales que todo diseñador debe conocer y utilizar para crear diseños efectivos y atractivos. Cada principio se puede utilizar con un propósito específico, y trabajan en conjunto para crear una composición visualmente equilibrada y cohesiva. Estos principios de diseño tienen en sus cimientos las leyes de la Gestalt, y surgen al destilar y concentrar los elementos importantes aplicados en el contexto del diseño gráfico.
El balance o equilibrio se refiere a la distribución visual de los elementos en una composición, y se logra mediante la compensación entre dos o más elementos. El objetivo de este principio es crear una sensación de equilibrio y armonía en el diseño. Existen dos tipos de balance: simétrico y asimétrico. En el balance simétrico, los elementos se distribuyen de manera equitativa a ambos lados de un eje central, lo que transmite una sensación de estabilidad. Por otro lado, en el balance asimétrico se distribuyen elementos de diferentes tamaños y formas de tal manera que logran equilibrar el diseño visualmente.
Por ejemplo, un diseñador puede utilizar un balance simétrico al distribuir las imágenes de los productos de manera uniforme a ambos lados del eje central de un folleto para una empresa, o bien utilizar un balance asimétrico al inclinar y superponer algunas de las imágenes para lograr un enfoque más creativo.




La proximidad en diseño se refiere a la agrupación de elementos relacionados para organizar su posición dentro de la composición. Este principio crea una relación entre un conjunto de elementos, proporcionando un sentido de unión o lejanía, dependiendo de qué tan cerca o lejos se encuentren los elementos. La proximidad ayuda a organizar la información y guía la mirada del espectador a través del diseño.
Por ejemplo, en un diseño de página web para una tienda, el diseñador puede agrupar productos de una misma categoría en secciones cercanas en la página, lo que permite al usuario navegar de manera más eficiente y encontrar información relevante rápidamente.


La alineación es un principio que permite construir orden o caos al crear conexiones visuales entre los distintos elementos gráficos. Ayuda a unificar los elementos en una composición, incluso cuando estos no se encuentran cerca entre sí, mediante la creación de líneas invisibles que generan conexiones. Este principio se refiere a la forma en que se colocan los elementos en relación con otros elementos del diseño. La alineación ayuda a que el diseño se vea limpio y organizado, evitando la sensación de caos y falta de estructura.
Por ejemplo, en el diseño de una revista, se pueden alinear todos los elementos de texto a la izquierda o a la derecha para crear una sensación de orden y estructura en la página, haciendo que los bloques de texto sean más fáciles de identificar.


La repetición consiste en utilizar elementos similares en todo el diseño para crear una sensación de cohesión y reforzar la relación y consistencia entre ellos. Este principio de diseño se utiliza ampliamente para dar congruencia a un conjunto diverso de elementos, como la imagen empresarial o corporativa de una empresa, todos los materiales educativos de un curso o las portadas de una misma colección de libros. La repetición ayuda a que el diseño sea más memorable y a unir sus elementos.
Por ejemplo, un diseñador puede emplear el mismo color de fondo y fuente en todas las páginas de un sitio web para crear una sensación de unidad y cohesión en todo el sitio. Los iconos de un paquete de software de oficina como LibreOffice, son un buen ejemplo donde se repiten algunas características (como las formas), para mantener la cohesión entre ellos.


El principio de contraste se refiere a la diferencia visual entre los elementos del diseño. Su finalidad es diferenciar, destacar o separar elementos visuales, ya sea entre ellos o del fondo, acentuando las diferencias que existen entre los objetos de la composición para crear interés visual. El objetivo principal es llamar la atención sobre los elementos importantes y para conseguirlo, se pueden utilizar diferentes recursos, como el uso de distintos tamaños, colores, formas, texturas y tipografías, así como la elección de colores opuestos en el círculo cromático. En definitiva, el principio de contraste se basa en la creación de diferencias visuales para llamar la atención y enfatizar elementos de interés.
Por ejemplo, en una página web o en la cabecera de un artículo, el diseñador puede utilizar un color llamativo y vibrante para el título con la finalidad de resaltar un mensaje importante.




El espacio negativo o espacio en blanco se refiere a la ausencia de elementos visuales entre los integrantes de una composición, aunque no necesariamente debe ser de color blanco. Su uso estratégico permite equilibrar y organizar los elementos visuales en un diseño, evitando la sobrecarga visual y destacando los elementos importantes. Además, el espacio negativo puede crear una sensación de respiración y claridad en la composición, proporcionando sólo la información necesaria para una presentación efectiva.
Por ejemplo, en una tarjeta de presentación se puede emplear espacio en blanco alrededor del logotipo y los datos de contacto para crear un diseño minimalista y elegante que destaque los elementos informativos esenciales.


Como se puede observar los principios de diseño tienen muchas similitudes con las leyes de la Gestalt, ya que los principios de diseño son simplificaciones ajustadas a los conceptos de diseño. Aún así, hay que recordar que ambos se enfocan en cómo las personas perciben y organizan visualmente la información, particularmente: en como se agrupan elementos cercanos; como se crea equilibrio visual mediante simetría; como se destacan diferencias y establecen un foco visual claro; así como la manera de usar elementos repetidos y similares para crear cohesión; y como se organizan los elementos en líneas para facilitar el flujo visual de la información.
Para complementar lo presentado en el capítulo se puede visitar el siguiente sitio: https://chrisbrejon.com/cg-cinematography/ donde se ofrece información sobre principios de cinematografía para animaciones generadas por computadora, desde un enfoque de color e iluminación.
La animación por computadora utiliza los principios del computo gráfico (o la graficación por computadora), para generar imágenes a partir de modelos geométricos que representan los diversos elementos de una escena. Tanto en la graficación como en la animación por computadora, se involucra la transformación de información geométrica, ya que se modifica la definición de los objetos de un espacio de representación a otro para construir y presentar un ambiente sintético. Asimismo, se transforma la información como función del tiempo para lograr movimientos y cambios en la animación, y finalmente, se convierte la información en una representación visual para obtener las imágenes que se muestra en pantalla.
Las matrices desempeñan un papel fundamental en las transformaciones, en particular, las matrices de $4×4$ son especialmente importantes, ya que forman la base para todas las transformaciones realizadas en la graficación y animación por computadora. Estas matrices permiten especificar una amplia gama de transformaciones, incluyendo rotaciones, traslaciones, escalamientos y proyecciones, de manera unificada y eficiente.
Así como el desarrollo de una animación sigue una serie de pasos para su desarrollo, conocido como el pipeline de producción de una animación, la graficación por computadora también divide las acciones necesarias para construir una imagen en una serie de etapas que se conocen como: el pipeline gráfico.
En computación un pipeline o línea de ensamblado, corresponde a una secuencia de operaciones que procesan información de forma secuencial, donde la salida de una operación es utilizada como la entrada de la siguiente operación. El pipeline gráfico o pipeline de render es la secuencia de pasos que a partir de una escena 3D construida por medio de modelos geométricos (usualmente polígonos), convierten dicha escena en una representación geométrica bidimensional, para posteriormente obtener los píxeles que componen las regiones cubiertas por los objetos geométricos y con esta información se crea una imagen que representa una vista de la escena.
Cuando se utiliza el hardware gráfico (GPU) como apoyo para generar imágenes por computadora, el pipeline gráfico cuenta con un conjunto general de etapas que son: el procesamiento geométrico, la rasterización, el procesamiento de fragmentos y el mezclado. Aunque la arquitectura del hardware ha evolucionado, estas cuatro etapas han permanecido como componentes fundamentales dentro del pipeline gráfico. Cada una de las etapas principales por lo general se descomponen en subetapas que realizan tareas más especializadas, algo así como pequeños pipelines dentro de cada etapa, esto con la finalidad de simplificar las operaciones complejas en tareas más manejables.
Es importante mencionar que en la actualidad las etapas del procesamiento geométrico (o de vértices) y de procesamiento de fragmentos son programables, es decir, se pueden crear programas que se ejecutan en la tarjeta de video (GPU) y que permiten controlar la forma en la que se procesa la información. A estos programas se les conoce como shaders. Por otra parte las etapas de rasterización y mezclado, no son programables pero si son configurables, es decir, su funcionalidad es parte de la GPU y no se puede cambiar, pero por medio de parámetros es posible alterar su comportamiento.
La etapa del procesamiento geométrico también llamada procesamiento de vértices, consiste en un conjunto de operaciones que operan sobre los vértices que definen los objetos geométricos de una escena; estas operaciones por lo general involucran un conjunto de transformaciones que permiten cambiar la información geométrica de los vértices a diferentes espacios de representación, obteniendo al final vértices ubicados dentro del volumen de visión determinado por la cámara que observa la escena. En esta etapa se tiene un conjunto de transformaciones entre diversos espacios de representación: Espacio del objeto → Espacio del mundo → Espacio de la vista.
Al hablar de un espacio de representación se hace referencia a un sistema de coordenadas en las que se especifica la información geométrica de un modelo. Un espacio de dos dimensiones (2D), generalmente se representa mediante dos ejes coordenados principales; el eje $X$ se ubica usualmente en la dirección de izquierda a derecha y el eje $Y$ en la dirección de abajo hacia arriba ().

En espacios de tres dimensiones, la forma en la que se especifican los ejes coordenados puede variar. Por ejemplo, en el contexto del computo gráfico se considera que la pantalla representa un espacio 2D y el eje $Z$ representa un eje que sale (o entra) de la pantalla, lo que da profundidad a los elementos bidimensionales ().

También se puede pensar en una situación del mundo real donde los ejes $X$ y $Y$ representan el suelo y el eje $Z$ es la altura o elevación de los diversos objetos respecto al suelo ().

La mayoría de los modelos que componen un escena tridimensional están formados por vértices y caras que relacionan dichos vértices para formar una aproximación a la superficie de un objeto.
El espacio del objeto (object space) es donde se define la información geométrica de cada modelo 3D, de tal manera que dicho objeto se encuentra determinado por el origen del espacio y sus puntos o vértices que se especifican respecto a dicho origen. Es importante recordar que cada modelo 3D cuenta con su propio espacio del mundo, usualmente asociado con el centro del modelo.

El espacio del mundo (world space) es un espacio de representación donde se ubican todos los objetos para construir ambientes y escenarios en una escena 3D. Aquí es donde se utilizan transformaciones como traslaciones, rotaciones y escalamientos, para ensamblar colocar y orientar los objetos que conforman la escena. Además, en este espacio es donde se ubican y configuran las diversas luces y las cámaras.
En una escena 3D la cámara u observador es un objeto que cuenta con una posición y una orientación, por medio de la cual se construye un nuevo espacio o sistema de referencia a partir del cual se observan los diversos objetos de una escena.
El espacio de referencia de la cámara se define al construir un conjunto de vectores ortonormales que determinan una nueva base del espacio 3D. Para su construcción se tiene en cuenta la dirección de la vista (view direction) que es un vector que apunta en la dirección en que observa la cámara, aunque a veces la dirección de la vista se construye con el vector formado entre la posición de la cámara y un punto o centro de interés (center of interest, COI) hacia donde observa.
También se considera un vector hacia arriba (up vector) que corresponde al vector perpendicular a la dirección de la vista y se encuentra en el plano definido por el vector de dirección de la vista y el eje hacia arriba global (usualmente el eje $Y$). Siendo los vectores $u$, $v$ y $w$ los elementos de la nueva base:
$$\begin{align*} w &= COI − EYE \\ u &= w × UP \\ v &= u × w \end{align*}$$El espacio de la vista o del ojo o de la cámara (eye space) es la representación que se obtiene al transformar las coordenadas de un modelo que ya se encuentra en el espacio del mundo a través de la información proporcionada por la cámara (o el observador). Al aplicar esta transformación, el observador termina ubicado en el origen mirando en la dirección negativa del eje $Z$, esto con la finalidad de que la profundidad de un vértice se determine simplemente por el valor de su coordenada en $Z$. Además de la información anterior, se considera el campo de visión (field of view, fov), para especificar el volumen visible del espacio del mundo. Para esto se utiliza un ángulo de visión (angle of view), la distancia de recorte cercana (near clipping distance) y la distancia de recorte lejana (far clipping distance), para construir una pirámide truncada que corresponde al campo de visión de la cámara, la pirámide truncada se conoce como view frustum ().
Hay que considerar que los objetos que se encuentra fuera del volumen visible, es decir, fuera del view frustum, no contribuyen para la imagen final, ya que la cámara no los ve. Debido a esto se suelen implementar algoritmos que descartan geometrías completas que se encuentran fuera del volumen visible, lo que se conoce como el view-frustum culling, para garantizar que solo los objetos visibles sean procesados por la tarjeta gráfica.

Aplicando una transformación de proyección, los vértices se convierten del espacio de la vista al espacio de la imagen (image space). Básicamente se realiza una transformación que convierte la pirámide truncada en un prisma rectangular y de ahí se obtiene la nueva información de los vértices. El objetivo de la transformación de proyección es calcular las posiciones bidimensionales de los vértices para ser representados en el plano de la imagen, lo que posteriormente se traduce en la imagen en la pantalla.
La rasterización es la etapa encargada de tomar los vértices transformados en la etapa anterior y con ellos ensambla primitivas geométricas (por lo general triángulos) y las convierte en fragmentos; siendo un fragmento un conjunto de información asociada a los posibles píxeles que cubre la primitiva geométrica. En aplicaciones gráficas sencillas, se pueden pensar a los fragmentos como píxeles, pero hay que considerar que un fragmento contiene más información que solamente un color, por ejemplo, puede tener información de la normal de la superficie, coordenadas de textura, así como cualquier otra información que sea relevante para determinar el verdadero color de la primitiva geométrica.
En la rasterización se tienen las subetapas: El ensamblado de primitivas → El recorte o clipping → La división de perspectiva → Eliminación de caras posteriores (Back-face culling) → Transformación de la ventana o viewport → Scan conversion.
A partir de la etapa anterior se tienen un conjunto de vértices que fueron proyectados sobre el plano de la imagen. Y estos vértices se ensamblan en primitivas, las cuales pueden ser puntos, segmentos o triángulos, que son por lo general las primitivas que soportan los APIs gráficos actuales.

En esta etapa las primitivas se recortan utilizando los 6 planos que definen el volumen cúbico de la vista, con esto se eliminan objetos o parte de ellos que se encuentran fuera del volumen de la vista y por lo tanto no son visibles.

Durante la construcción y procesamiento geométrico, los vértices que definen los objetos de una escena se especifican por medio de coordenadas homogéneas (lo que se explica en la sección

En graficación, culling se refiere a eliminar partes de una escena que no son visibles por la cámara, en este sentido la operación de backface culling se encarga de descartar los polígonos que se encuentran de espaldas al punto de vista de la cámara.
Para determinar si un triángulo se encuentra de frente o de espaldas a la cámara se utiliza el orden o winding de los vértices que definen el polígono, siendo por lo general que un orden en sentido de las manecillas del reloj determina un triángulo de espaldas y un orden en contra del sentido de las manecillas del reloj corresponde a un polígono de frente a la cámara.
Esta etapa es configurable y puede desactivarse lo que causa que no se descarte ningún polígono, lo cual es útil si se quieren dibujar objetos semitransparentes u objetos con orificios que muestren su interior; en caso de activar el back-face culling es posible configurar si se quieren descartar los polígonos de espalda o de frente a la cámara, así como determinar cual es el sentido de giro utilizado para determinar la dirección (horaria o antihoraria) respecto a la cámara del polígono.
Cada ventana que se dibuja en la pantalla de una computadora tiene asignado su propio espacio, conocido como espacio de pantalla, el cual no necesariamente cubre la totalidad de la pantalla. En este espacio los vértices proyectados en el plano de la imagen se transforman para calcular las coordenadas de píxel, las cuales son dependientes de la pantalla o el área de la visualización donde se muestran las imágenes.

Una vez que cada primitiva se encuentra definida en el espacio de pantalla la subetapa de scan conversion se encarga de construir los fragmentos correspondientes. De forma más específica, se determina la posición de los píxeles cubiertos por la primitiva y se interpola cualquier información asociada a los vértices de la primitiva para asociar los valores interpolados a cada fragmento.
La etapa de procesamiento de fragmentos se encarga de tomar la información almacenada en los fragmentos obtenidos en la etapa anterior y con dicha información se realizan cálculos que determinan el color final del píxel correspondiente.
Esta etapa inicia con un conjunto de fragmentos que poseen información interpolada, la cual puede incluir información sobre la profundidad, la normal de la superficie, colores, coordenadas de texturas, etc. Utilizando toda la información proporcionada el shader de fragmentos calcula el color correspondiente.
Existen varias formas para producir el color de los píxeles; una de ellas es por medio de los modelos de iluminación, los cuales por medio de ecuaciones intentan replicar el comportamiento de la luz sobre superficies hechas de diversos materiales; otra forma es por medio del mapeo de texturas, donde los colores de los píxeles se obtienen al leer la información de color de una o varias imágenes. En la actualidad para lograr representaciones realistas y detalladas de modelos tridimensionales, por lo general se utiliza una combinación de modelos de iluminación y texturas, donde las imágenes asociadas a las texturas proporcionan información sobre los materiales del objeto que se utilizan en un modelo de iluminación para producir el color del píxel de cada fragmento.
La salida de esta etapa a veces se llama fragmento RGBAZ, ya que no solo se devuelve un color (en RGB), si no que además se incorpora la opacidad (A) o alfa, así como la profundidad de dicho fragmento (coordenada Z).
En la etapa del mezclado se toman los “píxeles” obtenidos en la etapa anterior y se combinan en el búfer de color (que es una área de memoria en la tarjeta de video que permite mostrar una imagen) para construir píxel a píxel la imagen final. Aquí se usa la transparencia y la profundidad para determinar la forma en la que se mezclan o combinan los píxeles almacenados en el búfer de color y el fragmento que se está procesando.
El búfer de profundidad o Z-buffer es un área en memoria en la GPU, usualmente con la misma resolución que el búfer de color, en donde se almacena la profundidad o Z de los píxeles que se encuentran almacenados en el búfer de color.
Al procesar un fragmento RGBAZ se utiliza el búfer de profundidad para determinar si la profundidad (Z) del nuevo fragmento a dibujar es menor que la profundidad almacenada previamente. En caso de que sea menor, se actualiza el búfer de profundidad con la nueva Z y el búfer de color con los valores del fragmento. En caso contrario se considera que el fragmento se encuentra detrás o son cubiertos por el fragmento actual y por lo tanto su valor es descartado.
Lo descrito anteriormente correspondiente al búfer de profundidad es válido si se considera que los píxeles son completamente opacos, es decir, su valor A o alpha es igual a $1$, pero si se tienen objetos traslúcidos donde su valor de A es menor que $1$, entonces no se puede descartar el fragmento directamente. En este caso se realiza un proceso conocido como composición alfa o alpha blending, donde el color almacenado en el búfer de color se mezcla con el color del fragmento que se esta dibujando, esto por medio de una ecuación de mezcla, usualmente de la forma:
$$c = αc_f + (1 − α)c_p$$Donde $c$ corresponde al color mezclado, $α$ es la opacidad del fragmento, $c_f$ es el color del fragmento y $c_p$ es el color del píxel almacenado en el búfer de color.
Por lo general los APIs gráficos permiten configurar la forma de la ecuación de composición alfa para obtener diferentes resultados.
La prueba de plantilla o stencil test es una subetapa en el mezclado que sirve para descartar grandes regiones de píxeles y que así no se escriban en el búfer de profundidad ni en el de color. Esto se logra creando un búfer para la plantilla que simplemente corresponde a una máscara o valores entre $0$ y $1$, que determinan si en alguna región se debe o no actualizar la información del búfer de profundidad y de color.

En graficación por computadora se tienen tres transformaciones básicas, que son: el escalamiento, la rotación y la traslación; las cuales pueden ser expresadas como un sistema de ecuaciones y justo esta propiedad es la que permite expresar las transformaciones como los coeficientes de una matriz.
Un escalamiento en 2D esta dado por:
$$\begin{align*} x' &= x \cdot sx \\ y' &= y \cdot sy \end{align*}$$Una rotación en 2D es:
$$\begin{align*} x' &= x \cdot cos(θ) − y \cdot sen(θ) \\ y' &= x \cdot sen(θ) + y \cdot cos(θ) \end{align*}$$Para obtener la transformación de rotación hay que recordar lo que ocurre con las funciones trigonométricas seno y coseno de una suma de ángulos:
$$\begin{align*} sen(α+β) &= sen(α) \cdot cos(β) + cos(α) \cdot sen(β) \\ cos(α+β) &= cos(α) \cdot cos(β) − sen(α) \cdot sen(β) \end{align*}$$La transformación de traslación en 2D es:
$$\begin{align*} x' &= x + tx \\ y' &= y + ty \end{align*}$$Es posible cambiar las expresiones anteriores por una representación matricial que exprese de forma más compacta una transformación.
Una transformación de escalamiento en 2D usando matrices es:
Rotación en 2D usando matrices:
Traslación en 2D usando matrices
Como no se puede codificar de forma directa una traslación en 2D utilizando los coeficientes de una matriz de $2×2$ entonces se necesita utilizar una dimensión adicional, es decir una matriz de $3×3$ de la siguiente manera:
$$\begin{pmatrix} x' \\ y' \\ 1 \end{pmatrix} = \begin{bmatrix} 1 & 0 & tx \\ 0 & 1 & ty \\ 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ 1 \end{pmatrix}$$Si se utilizan matrices de $3×3$ para codificar las transformaciones en espacios tridimensionales se obtiene lo siguiente.
Escalamiento en 3D:
Las rotaciones en tres dimensiones se convierten en tres matrices diferentes, una para cada eje del espacio 3D.
Rotación en 3D respecto al eje $X$:
Rotación en 3D respecto al eje $Y$:
Rotación en 3D, respecto al eje $Z$
De forma similar a la traslación en 2D, no es posible expresar una traslación en 3D con matrices de la misma dimension que el espacio ($3×3$), por ende se vuelve necesario utilizar una dimensión adicional para expresar correctamente una traslación.
Las coordenadas homogéneas son un concepto importante en la geometría proyectiva y se utilizan en la graficación por computadora para realizar transformaciones en un espacio 3D. La notación matricial homogénea es un método eficiente y conveniente para realizar operaciones lineales en vectores de coordenadas homogéneas.
En esencia, las coordenadas homogéneas agregan una dimensión adicional a las coordenadas cartesianas de un espacio. Por lo tanto, un punto o un vector $(x, y, z)$ en coordenadas cartesianas tridimensionales, se representa mediante un vector de cuatro elementos $(x, y, z, w)$ expresado en coordenadas homogéneas. La componente adicional $w$ se utiliza para homogeneizar las transformaciones. Si la componente $w$ es igual a $1$, entonces el vector $(x, y, z, w)$ representa un punto en el espacio 3D. Si $w$ es diferente de $1$, entonces se utiliza la división homogénea (o división de perspectiva en el contexto del computo gráfico) para obtener las coordenadas cartesianas $(x/w, y/w, z/w)$ correspondientes al punto en el espacio 3D. Por otro lado, si la componente $w$ es igual a cero, entonces el vector $(x, y, z, w)$ representa un vector en el espacio 3D, y no se realiza ninguna división.
Utilizando coordenadas homogéneas se pueden expresar las transformaciones 3D básicas (rotación, escalamiento y traslación) utilizando matrices de $4×4$, ofreciendo un mismo marco de trabajo para realizar las operaciones y con esto permitiendo que componentes de hardware como el GPU se especialicen en una unica operación, la multiplicación de matrices, lo que permite transformar los vértices de un objeto geométrico de forma paralela haciendo más eficiente su procesamiento.
Escalamiento:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} sx & 0 & 0 & 0 \\ 0 & sy & 0 & 0 \\ 0 & 0 & sz & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$Traslación:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} 1 & 0 & 0 & tx \\ 0 & 1 & 0 & ty \\ 0 & 0 & 1 & tz \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$Rotación en $X$:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & cos(θ) & -sen(θ) & 0 \\ 0 & sen(θ) & cos(θ) & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$Rotación en $Y$:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} cos(θ) & 0 & sen(θ) & 0 \\ 0 & 1 & 0 & 0 \\ -sen(θ) & 0 & cos(θ) & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$Rotación en $Z$:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} cos(θ) & -sen(θ) & 0 & 0 \\ sen(θ) & cos(θ) & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$El espacio del mundo está construido con la base ortonormal $(1, 0, 0)$, $(0, 1, 0)$ y $(0, 0, 1)$, para realizar la transformación de la vista, se debe realizar un cambio de base utilizando los datos de la cámara. Suponiendo que la cámara se encuentra en la posición $(cx, cy, cz)$, con una base definida por los vectores $(ux, uy, uz)$, $(vx, vy, vz)$ y $(wx, wy, wz)$, como se definió previamente:
$$\begin{align*} w &= EYE - COI \\ u &= UP × w \\ v &= u × w \end{align*}$$Al garantizar que estos vectores estén normalizados, para forma una base ortonormal.
$$\begin{align*} w &= \frac{(EYE - COI)}{||EYE - COI||} \\ u &= \frac{(UP × w)}{||(UP × w)||} \\ v &= \frac{(w × u)}{||(w × u)||} \end{align*}$$Entonces se puede construir la matriz de transformación de la vista como la concatenación de una traslación para colocar la cámara en el origen y una matriz de cambio de base usando los vectores $u$, $v$ y $w$.
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} ux & uy & uz & 0 \\ vx & vy & vz & 0 \\ wx & wy & wz & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 & -cx \\ 0 & 1 & 0 & -cy \\ 0 & 0 & 1 & -cz \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$La transformación de proyección ortogonal construye un prisma rectangular determinado por $l$ (left) el plano izquierdo, $r$ (right) el plano derecho, $b$ (bottom) el plano del abajo, $t$ (top) el plano de arriba, $n$ (near) el plano cercano y $f$ (far) el plano lejano. Estos planos delimitan el volumen de visión y permiten controlar qué partes de la escena son visibles en la imagen 2D resultante.

Matriz de proyección ortogonal.
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} \dfrac{2}{r-l} & 0 & 0 & -\dfrac{r+l}{r-l} \\ 0 & \dfrac{2}{t-b} & 0 & -\dfrac{t+b}{t-b} \\ 0 & 0 & \dfrac{2}{n-f} & -\dfrac{f+n}{f-n} \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$La clave de una proyección en perspectiva radica en que el tamaño de un objeto en la pantalla es proporcional a $1/z$ cuando es observado desde el origen.

En la sección sobre coordenadas homogéneas se mencionó que la posición $(x, y, z, w)$ corresponde a las coordenadas cartesianas $(x/w, y/w, z/w)$. En todas las transformaciones previas, la componente $w$ ha sido igual a $1$, lo que ha hecho innecesario realizar la división por $w$. Sin embargo, para realizar la transformación de perspectiva, es necesario dividir las componentes por un valor específico.
Si se considera un plano cercano $n$ y un plano lejano $f$, la proyección debe seguir las pautas mencionadas anteriormente, es decir, $ys = -(n/z) \cdot y$ y $xs = -(n/z) \cdot x$, lo que se logra utilizando la siguiente matriz de transformación:
Desarrollando la multiplicación anterior se obtiene:
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{pmatrix} n \cdot x \\ n \cdot y \\ z \cdot (n+f) + f \cdot n \\ -z \end{pmatrix} = \begin{pmatrix} -\cfrac{n \cdot x}{z} \\ -\cfrac{n \cdot y}{z} \\ -(n + f) - \cfrac{f \cdot n}{z} \\ 1 \end{pmatrix}$$Las nuevas posiciones $x'$, $y'$ y $z'$ corresponden a la transformación en perspectiva, donde las posiciones son proporcionales a $1/z$. De forma intuitiva, esta transformación convierte el view frustum en el volumen canónico utilizado en la proyección ortogonal (). Una vez convertido el volumen de visión, basta con realizar una proyección ortogonal para completar la proyección en perspectiva.
Otra forma de ver la proyección de perspectiva, es utilizando el ángulo de visión en lugar de los planos: $l$ (el plano izquierdo), $r$ (el plano derecho), $b$ (el plano del abajo) y $t$ (el plano de arriba).
La tangente es el cateto opuesto entre el cateto adyacente, lo que da lo siguiente: $tan \left(\dfrac{fovY}{2}\right) = \dfrac{y}{z}$
Multiplicando ambos lados por $z$ se obtiene: $y = z \cdot tan \left(\dfrac{fovY}{2}\right)$
Definiendo: $ftan = \dfrac{1}{tan} \left(\dfrac{fovY}{2}\right)$
Se tiene: $y = \dfrac{z}{ftan}$
Entonces para obtener la nueva coordenada en $Y$, $y'$ se debe dividir entre $\dfrac{z}{ftan}$.
$$\begin{align*} y' &= y / (z / ftan) \\ y' &= y \cdot ftan / z \end{align*}$$Para la $x'$ el cálculo es análogo, sólo hay que dividir el tamaño respecto a la relación de aspecto de la ventana.
$$x' = (x \cdot ftan / z) / aspect$$Si tenemos: $ftan = 1 / tan(fovY / 2)$
entonces
$$\begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \begin{bmatrix} \cfrac{ftan}{aspect} & 0 & 0 & 0 \\ 0 & ftan & 0 & 0 \\ 0 & 0 & \cfrac{n+f}{n-f} & \cfrac{2n \cdot f}{n-f} \\ 0 & 0 & -1 & 0 \end{bmatrix} \begin{pmatrix} x \\ y \\ z \\ 1 \end{pmatrix}$$Un fotograma también conocido como cuadro o frame, es la unidad visual básica que se utiliza para medir el tiempo en una animación. Se trata de una imagen individual que forma parte de una secuencia animada.
Un fotograma clave o keyframe es una acción que se produce en un punto específico en el tiempo, y se representa mediante un fotograma especial, que contiene información esencial creada por el animador para dar vida a los movimientos de la animación.

En la animación tradicional, que se realiza principalmente con dibujos hechos a mano, el animador es responsable de crear los keyframes para definir las acciones que tendrán lugar durante la animación. Luego, un grupo de dibujantes se encarga de generar los cuadros faltantes para completar la secuencia de imágenes entre los keyframes.
Por otro lado, en la animación por computadora, los animadores crean keyframes para definir las acciones de los personajes, y luego el software calcula automáticamente los fotogramas intermedios (conocidos como in-between) para completar la animación.

La interpolación es un método matemático que permite obtener nueva información a partir de datos conocidos. Su principal uso consiste en obtener nuevos datos a partir de un conjunto de datos discretos dados, mediante la construcción de una función que aproxime la información conocida de una cierta manera.
En términos matemáticos, si se tiene una pareja de $n$ puntos de la forma $(x_k, y_k)$, una interpolación es una función $f$ que cumple la siguiente propiedad:
$f(x_k) = y_k$, para toda $k = 1, ..., n$
Las funciones de interpolación tienen la característica de pasar o tomar valores siempre en el conjunto de datos conocidos. Cuando la función no pasa directamente por estos datos entonces lo que se tiene es una función de aproximación.
La idea detrás de la interpolación es que los puntos iniciales se encuentran sobre una curva desconocida, y hay que definir una función que permita estimar la forma de la curva para cualquier punto que esté entre dos puntos conocidos.

En animación por computadora, la interpolación es un componente fundamental para la creación automática de los fotogramas intermedios. Por lo general, el tipo de interpolación utilizado en animación se basa en la parametrización de valores a través del tiempo. Es decir, los valores que se buscan son valores desconocidos entre dos puntos en el tiempo.
La interpolación lineal, también conocida como LERP, es uno de los métodos más sencillos y comúnmente utilizados para aproximar nuevos valores a partir de un conjunto de datos conocidos. Este método utiliza una función lineal para interpolar los valores entre un par de puntos y obtener nuevos valores entre ellos.
Aunque la interpolación lineal es una opción rápida y sencilla para la obtención de nuevos valores, su precisión puede ser limitada en algunos casos. Esto se debe a que se asume una relación lineal entre los valores conocidos, lo que puede resultar en valores demasiado burdos e imprecisos en escenarios en los que la relación entre los valores no es lineal o en los que la función lineal no es suficiente para representar la complejidad de los datos.

Una interpolación lineal entre una pareja de puntos consecutivos $P_0$ y $P_1$ se expresa de la siguiente forma:
$$lerp(P_0, P_1, t) = P_0 + t (P_1 − P_0) = (1 − t) P_0 + t P_1$$Siempre es posible construir un polinomio de primer grado (un segmento) que pase por dos cualesquiera dos puntos.
Esta idea puede generalizarse para $n$ puntos $(x_k, y_k)$ con $k = 1, ..., n$, buscando un único polinomio en $x$ de grado menor que $n$ que pase por todos ellos. A este polinomio se le llama polinomio de interpolación.
Existen varios métodos para construir un polinomio de interpolación, siendo el método de Lagrange o la forma Lagrangiana uno de los más utilizados:
$$\mathcal{L}(x) = \sum_{j=0}^{k} y_j \ell_j(x)$$ $$\ell(x) = \prod_{i=0,i≠j}^{k} \frac{x-x_i}{x_j-x_i} = \frac{x-x_0}{x_j-x_0} ... \frac{x-x_{j-1}}{x_j-x_{j-1}} \frac{x-x_{j+1}}{x_j-x_{j+1}} ... \frac{x-x_k}{x_j-x_k}$$Para todo $i ≠ j$, $\ell_j(x)$ incluye el término $(x - x_i)$ por lo que el producto es cero en $x = x_i$.
$$\forall(j≠i) : \ell_j(x_i) = \prod_{m≠j} \frac{x_i-x_m}{x_j-x_m} = $$ $$= \frac{(x_i-x_0)}{(x_j-x_0)} ... \frac{(x_i-x_i)}{(x_j-x_i)} ... \frac{(x_i-x_k)}{(x_j-x_k)} = 0$$Por otro lado, cuando $x = x_j$, el término vale $1$, lo que da como resultado $y_j$.
$$\ell_j(x_j) = \prod_{m≠j} \frac{x_j-x_m}{x_j-x_m} = 1$$La ventaja de la interpolación polinomial es que construye una curva diferenciable y continua que pasa por todos los puntos dados. No obstante, la interpolación polinomial tiene el problema de que a medida que aumenta el número de puntos, también lo hace el grado del polinomio, lo que ocasiona que los cálculos sean más costosos en su evaluación, además aumentar el grado del polinomio suelen ocurrir oscilaciones alrededor de los puntos conocidos.
Por un lado, se tiene que la interpolación lineal es un método que utiliza únicamente información local, es decir, depende solamente de parejas de puntos para obtener nueva información. Y la interpolación polinomial es un método que requiere información global, utilizando todos los puntos. Ambos métodos presentan ventajas y desventajas. En aplicaciones gráficas interactivas, es común utilizar una interpolación a trozos o interpolación polinómica segmentaria. En este método, el conjunto de puntos de control se divide en intervalos más pequeños y se calcula un polinomio de interpolación entre parejas contiguas de puntos.
La interpolación de Hermite genera un polinomio cúbico entre dos puntos conocidos, utilizando información local. Para calcularlo, es necesario especificar los puntos $P_i$ (punto incial) y $P_{i+1}$ (punto final) por los que pasa el polinomio, así como los vectores tangentes para el punto inicial $P'i$ y final $P'{i+1}$.

La interpolación se construye con:
$$P(u) = U^T \, M \, B$$
Para garantizar la continuidad entre los puntos conectados, se utiliza la misma información de la tangente en el punto final de una pareja, como la tangente en el punto inicial en una nueva secuencia. Este método tiene la desventaja de que las tangentes en los puntos deben ser calculadas manualmente, lo que no siempre es conveniente.

Las funciones polinómicas a trozos, también conocidas como splines, se utilizan ampliamente en la computación gráfica. El término spline proviene de la construcción de barcos, donde un spline corresponde a una pieza delgada de metal o madera que se ajusta a una ranura en el borde de una tabla.
Existen diferentes tipos de splines, como los lineales, cuadráticos, cúbicos, etc., así como la interpolación o aproximación con splines. El tipo de spline que se utiliza depende del tipo de aplicación, sin embargo, todos los splines aproximan una curva de la forma más suave y continua posible, utilizando los puntos conocidos para su definición.
Se dice que una función $s(x)$ es un spline en el intervalo $[a, b]$ si existe una partición del intervalo $[a, b]$,
$$P = \{ a = x_1 < x_2 ... < x_n = b \}$$de tal forma que $s(x)$ es un polinomio en $[x_i , x_{i+1}]$, con $i = 1, ..., n.$

.png)
Los puntos $x_i$ con $i = 1, ..., n$ son comúnmente llamados como nodos o nudos del spline.
Los splines de Catmull-Rom pertenecen a una familia de curvas de interpolación ampliamente utilizadas en la graficación y animación por computadora. Estos splines se calculan de tal manera que la tangente a la curva en cada punto $p_i$ se basa en información de los puntos adyacentes, es decir, el punto anterior $p_{i−1}$ y el siguiente $p_{i+1}$, siendo la tangente la mitad del vector entre $p_{i−1}$ y $p_{i+1}$.
$$P'_i = \frac{1}{2} (P_{i+1} − P_{i−1})$$
La interpolación se construye con:
$$P(u) = U^T \, M \, B$$ $$ P(u) = \begin{bmatrix} u^3 & u^2 & u & 1 \end{bmatrix} \frac{1}{2} \begin{bmatrix} -1 & 3 & -3 & 1 \\ 2 & -5 & 4 & -1 \\ -1 & 0 & 1 & 0 \\ 0 & 2 & 0 & 0 \end{bmatrix} \begin{bmatrix} P_{i-1} \\ P_i \\ P_{i+1} \\ P_{i+2} \end{bmatrix} $$
Una de las ventajas que tiene las splines de Catmull-Rom es que el cálculo de la tangente resulta automático y simple. Sin embargo, una desventaja es que las tangentes son independientes de la posición del punto por donde la curva atraviesa, ya que solo dependen del punto anterior y siguiente. Por este motivo, se han desarrollado algunas variaciones de los splines de Catmull-Rom en las que se modifica el cálculo de la tangente, para proporcionar más control sobre la curva generada.
Otras curvas spline ampliamente utilizadas son las curvas de Bézier, que se emplean en el diseño industrial. Estas curvas fueron desarrolladas por James Ferguson (Boeing), Pierre Bézier (Renault) y Paul de Faget de Casteljau (Citroën) para la industria de la aviación y la automotriz.
En particular, una curva de Bézier es un spline de interpolación y aproximación, esto significa que la curva siempre atraviesa dos puntos extremos dados, mientras intenta aproximarse a otros puntos llamados puntos de control o auxiliares, que definen la dirección de la tangente de la curva en los puntos extremos.
La forma más sencilla de una curva de Bézier es una curva de grado $1$, en este caso, solo se tiene la información de los puntos extremos ($P_0$ y $P_1$) y no se especifican puntos de control. Esta curva está determinada de la misma manera que la interpolación lineal (vista anteriormente):
$$B(t) = P_0 + t (P_1 − P_0) = (1 − t) P_0 + t P_1$$Una curva de Bézier cuadrática está determinada por tres puntos, dos puntos extremos ($P_0$ y $P_2$) y un punto de control ($P_1$).
$$B(t) = (1 − t)^2 P_0 + 2t (1 − t) P_1 + t^2 P_2$$Una curva de Bézier cúbica está determinada por cuatro puntos, dos puntos extremos ($P_0$ y $P_3$) y dos puntos de control ($P_1$ y $P_2$).
$$B(t) = (1 − t)^3 P_0 + 3t (1 − t)^2 P_1 + 3t^2 (1 − t) P_2 + t^3 P_3$$Todas estas expresiones paramétricas:
$$\begin{align*} B_1(t) &= (1 − t) P_0 + t P_1 \\ B_2(t) &= (1 − t)^2 P_0 + 2t (1 − t) P_1 + t^2 P_2 \\ B_3(t) &= (1 − t)^3 P_0 + 3t (1 − t)^2 P_1 + 3t^2 (1 − t) P_2 + t^3 P_3 \end{align*}$$Son casos particulares de la fórmula general:
$$\begin{align*} B_n(t) &= (1 − t)^n P_0 + n (1 − t)^{n−1} t P_1 + n(n − 1)/2 (1 − t)^{n−2} t^2 P_2 + \\ &... + C_{n,k} (1 − t)^{n−k} t^k P_k + ... + t^n P_n \end{align*}$$donde $C_{n,k}$ es el coeficiente binomial $\dfrac{n!}{k!(n − k)!}$.
La fórmula general es conocida como polinomios de Bernstein, nombrados en honor al matemático ucraniano Sergei Natanovich Bernstein que los utilizó para estudiar la conexión entre las propiedades de suavidad de una función y sus aproximaciones mediante polinomios. Los polinomios de Bernstein son herramientas útiles para aproximar funciones de manera numéricamente estable.
Es importante mencionar, que las curva de Bézier de grado $3$ suelen ser las más utilizadas en la graficación y animación por computadora.
Al observar la ecuación paramétrica:
$$B(t) = (1 − t)^3 P_0 + 3t (1 − t)^2 P_1 + 3t^2 (1 − t) P_2 + t^3 P_3$$se puede deducir que, al igual que en los ejemplos anteriores de splines, la curva está conformada por cuatro curvas base.
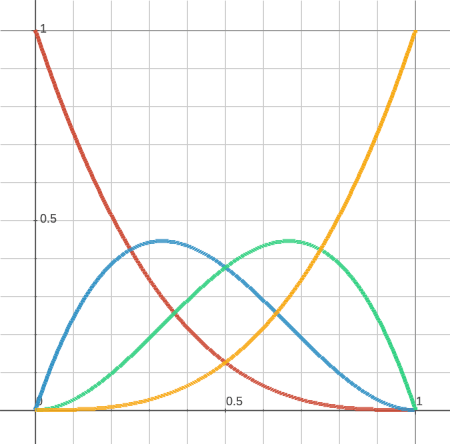
Adicionalmente a los polinomios de Bernstein, las curvas de Bézier se pueden construir de manera geométrica utilizando el algoritmo de Casteljau, el cual es un método recursivo que se utiliza en el campo del análisis numérico y particularmente en el diseño de curvas de Bézier. Lleva el nombre del ingeniero Paul de Faget de Casteljau, ya que lo desarrolló durante su trabajo en Citroën con la finalidad de abordar matemáticamente las formas de la carrocería de los automóviles. Y aunque es un método lento, en comparación por ejemplo con la evaluación de los polinomios de Bernstein, el algoritmo de Casteljau es numéricamente más estable.
En la naturaleza, los movimientos de la mayoría de los objetos no son lineales, sino que tienden a acelerar o desacelerar. Cuando un objeto comienza a moverse lentamente y su velocidad aumenta gradualmente, se utiliza el término aceleración para referirse al cambio en la velocidad. Por otro lado, si un objeto en movimiento disminuye gradualmente su velocidad, se utiliza el término desaceleración.
En animación, la aceleración se conoce como ease-in, mientras que la desaceleración se conoce como ease-out. En muchas ocasiones, se combinan ambos tipos de cambio de velocidad para crear un movimiento conocido como ease-in-out, donde un objeto acelera y desacelera. Considerar los cambios de aceleración en el movimiento de los objetos permiten la creación de animaciones más naturales y menos robóticas.
La sincronización en animación, se refiere al tiempo que tarda una acción en completarse, por ejemplo, si dos pelotas se mueven de arriba a abajo en un segundo, ambas tienen la misma sincronización ya que su movimiento ocurre en el mismo periodo de tiempo.
El espaciado en animación se refiere al tiempo que transcurre entre dos cuadros o momentos de una acción. La variación en el tiempo entre estos momentos es lo que determina la forma en que se expresa la aceleración (easing). Dos objetos pueden tener la misma sincronización, es decir, realizar una acción al mismo tiempo, pero al espaciar sus cambios de forma diferente el movimiento se percibe de forma diferente.
Una correcta sincronización y espaciado son necesarias para crear una animación realista y profesional.
El modelado es un aspecto fundamental de la animación por computadora, ya que es el proceso mediante el cual se crean, construyen y definen los objetos tridimensionales que serán utilizados en la animación. El proceso de modelado puede implicar la creación de formas simples o complejas, desde objetos cotidianos hasta personajes y escenarios detallados. Existen diversas técnicas para representar la geometría de los modelos, entre las que se incluyen: B-splines racionales no uniformes (non-uniform rational B-splines, NURBS); polígonos; superficies de subdivisión y voxeles.
Los B-splines, también conocidos como líneas polinómicas suaves básicas, splines básicos o basis spline, son una generalización de los splines cúbicos que determinan curvas suaves y diferenciables que se definen mediante polinomios en trozos. Estas curvas se construyen a partir de puntos por donde pasa la curva (raíces de los polinomios) y puntos en los que se aproxima la curva (puntos de control). Siendo las curvas de Bézier un caso especial de los B-splines.
Los B-splines racionales no uniformes o Non-Uniform Rational B-Splines (NURBS) son un modelo matemático que se utiliza para definir superficies suaves mediante el uso de curvas como guía. Las curvas y superficies NURBS son una extensión avanzada de los B-splines que ofrecen mayor flexibilidad y precisión en el modelado de curvas y superficies geométricas. Los NURBS combinan las ventajas de los B-splines no uniformes con la capacidad de utilizar pesos racionales, permitiendo la representación exacta de una variedad de formas geométricas.
En las etapas tempranas de la graficación por computadora las NURBS eran la representación preferida para mostrar superficies debido a su suavidad y curvatura. En comparación, el uso de polígonos no producía la misma suavidad, resultando en la visualización de caras planas que componían la malla poligonal. Sin embargo, con la mejora del hardware, hoy en día es posible utilizar una gran cantidad de polígonos para aproximar superficies, lo que ha convertido a los polígonos en la opción preferida para el modelado.
Hay que mencionar que en productos de visualización y arquitectura (CAD), las NURBS se siguen utilizando debido a que los sistemas CAD requieren la capacidad de modelar formas geométricas complejas y precisas que van más allá de las capacidades de las primitivas geométricas básicas (como puntos, líneas y triángulos). Aunque en muchos casos, para realizar el render final, las superficies NURBS se transforman en polígonos para que la GPU pueda generar la imagen correspondiente.
Un polígono () es una figura geométrica formada por tres o más puntos en el espacio, conocidos como vértices. Las aristas son segmentos que unen a los vértices, y las caras son el área delimitada por las aristas del polígono. Cada uno de estos componentes puede ser transformado, es decir, rotado, trasladado y escalado.
El polígono más básico que se puede representar es el triángulo, y se utiliza ampliamente en la creación de gráficos en 3D. Diversos programas de modelado 3D, como Blender, Maya, 3D Studio Max, utilizan polígonos de cuatro caras (quads) como el polígono básico de construcción. Esto se debe a que los quads facilitan el proceso de modelado de objetos 3D, sin embargo, internamente los quads se convierten en un par de triángulos para que la GPU pueda manejarlos y dibujarlos.
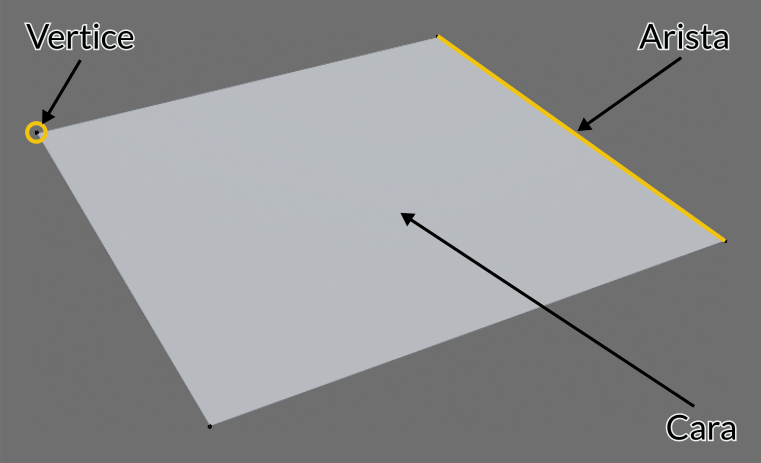
Es importante mencionar que por lo general, se evita construir polígonos con más de tres vértices, porque pueden comportarse de forma inestable. Esto se debe a que no siempre se puede garantizar que los $n$ vértices que conforman al polígono sean coplanares, lo que afecta el cálculo de las normales, lo que es fundamental para diversos modelos de iluminación.
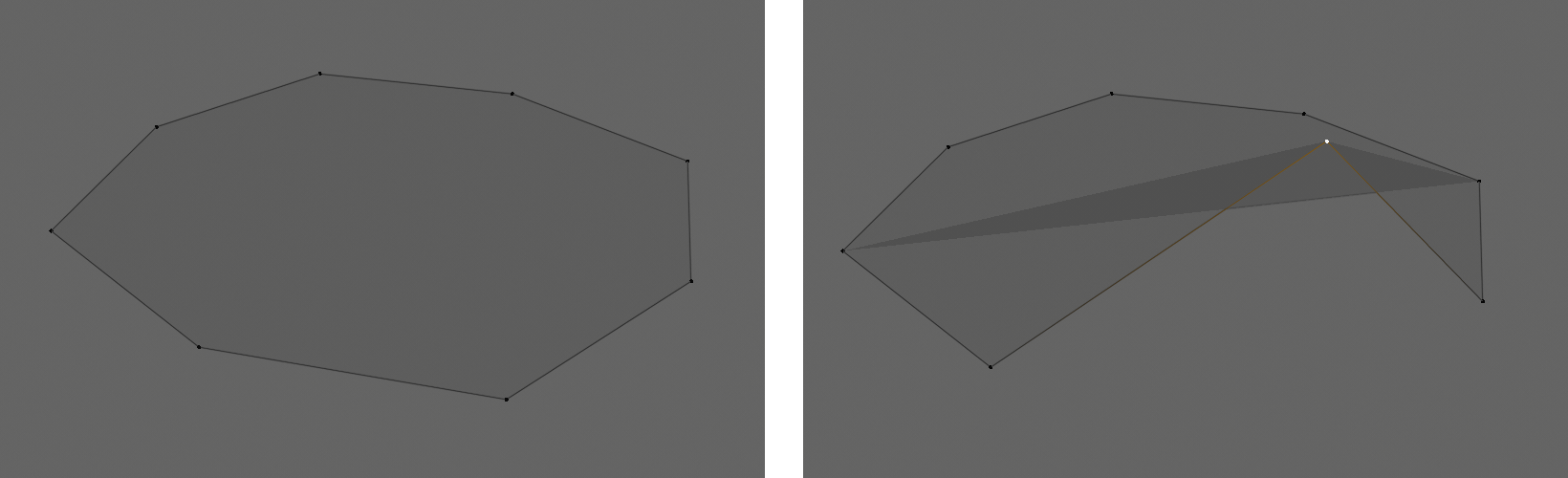
Una malla poligonal es una colección de polígonos que pueden ser transformados conjuntamente, lo que ofrece una mayor versatilidad en el proceso de modelado y creación de gráficos en 3D, ya que una malla poligonal puede representar la superficie de un objeto completo.
El flujo de las aristas indica la forma en que las aristas de un modelo tridimensional se mueven o fluyen, tal como su nombre lo sugiere. Un flujo adecuado de las aristas garantiza que éstas sigan la curvatura y características del modelo, lo que permite minimizar las deformaciones en las zonas externas a las caras que están siendo animadas.

Por lo general cuando se construye un modelo 3D con fines de animación, se suelen construir ciclos de quads al rededor de las zonas que se deforman, esto con la finalidad de aislar lo mejor posible los cambios en la topología de toda la malla. Hay que mencionar que un flujo de aristas correcto solo se vuelve visualmente importante en modelos animados, ya que son estos los que modifican la posición de sus vértices, por lo que es particularmente importante que en las articulaciones y rostros de los personajes animados se cuente con un flujo de aristas adecuado, y así evitar deformaciones.
El término normal se deriva de la palabra en latín norma, que hace referencia a una escuadra de carpintero que siempre se encuentra en ángulo recto con una línea o superficie ().

En matemáticas, la normal a una curva o superficie corresponde a un vector que es perpendicular a esa curva o superficie en un punto dado.

Cuando se modela un objeto tridimensional, es importante considerar las normales de las superficies poligonales, ya que la mayoría de los algoritmos de coloreado utilizan las normales para calcular el color de los píxeles de la superficie.
En la mayoría de los casos, si las normales se invierten, el color que se muestra en la superficie del objeto puede ser incorrecto o no visible, dependiendo del tipo de material o algoritmo de renderizado que se esté utilizando.
El coloreado plano (
Por otro lado, si se consideran las normales en los vértices como una normal asociada a todas las caras a las que pertenece cada vértice, entonces se produce un coloreado suave sobre la superficie lo que mejora la apariencia de objetos curvos. Este tipo de coloreado se conoce generalmente como coloreado de Gouraud (Gouraud shading).
La cantidad de polígonos utilizados para representar una malla se conoce como la resolución de la topología, y es importante ya que existen diferentes requisitos y restricciones según el sector al que se destine el modelo.
En el caso de los videojuegos, se espera que la resolución sea óptima (con solo los triángulos necesarios) para presentar e interactuar con los modelos tridimensionales en tiempo real. Por lo general, la resolución de los modelos en videojuegos se ajusta a las capacidades mínimas de un equipo de computo particular, lo que se conoce como los requisitos mínimos del sistema.
En el cine y la televisión se suelen permitir más polígonos, ya que no se requiere una interacción en tiempo real con los modelos, aquí por lo general la resolución se encuentra limitada por los recursos de cómputo, como la memoria, el procesador, etc.
Las superficies de subdivisión son una forma de representar superficies suaves y detalladas mediante una malla poligonal (con poca resolución topológica) y agregando detalles por medio de subdivisiones en múltiples niveles sobre la malla original. En esencia, una superficie de subdivisión es una malla poligonal a la que se le aplica recursivamente una operación de división y suavizado de sus caras.
Generalmente, las caras que se calculan en los diferentes niveles de subdivisión no son accesibles para su edición, ya que se busca simplificar la manipulación de objetos con muchos detalles. La principal ventaja que ofrecen las superficies de subdivisión es que con la manipulación de pocos vértices se pueden crear objetos complejos con una apariencia suave.

Además, las superficies de subdivisión permiten utilizar las mismas herramientas que se utilizan para modelar con polígonos. Anteriormente, cuando se requería modelar objetos orgánicos, es decir, objetos con una apariencia suave y redondeada, se utilizaban las NURBS, sin embargo, esto requería el uso y dominio de un conjunto de herramientas diferentes a las utilizadas para modelar con polígonos. En la actualidad, el uso de NURBS para modelar objetos orgánicos ha sido desplazado por el uso de superficies de subdivisión, ya que se pueden obtener resultados muy similares y suelen ser más eficientes.


OpenSubdiv es una biblioteca de código abierto que implementa los algoritmos para manejar superficies de subdivisión en CPU paralelos así como en la GPU. Para más información sobre superficies de subdivisión se puede consultar el siguiente vínculo: https://graphics.pixar.com/opensubdiv/docs/subdivision_surfaces.html.
El modificador de subdivisión utilizado en Blender emplea la biblioteca OpenSubdiv para su funcionamiento, según lo indica su documentación: https://docs.blender.org/manual/en/4.1/modeling/modifiers/generate/subdivision_surface.html
El vóxel, también conocido como volumetric pixel, es una unidad gráfica definida en tres dimensiones que se asemeja al píxel. Estos elementos, que se corresponden con un cubo unitario, se utilizan para representar información volumétrica en imágenes digitales. A diferencia de los píxeles, que representan información en dos dimensiones, los voxeles representan información en tres dimensiones.
Los voxeles son ampliamente utilizados en diversas aplicaciones, como en la medicina y la ciencia, para la representación de información volumétrica como las obtenidas por medio de tomografías, resonancias o en reconstrucciones de tejidos.
Así mismo, en el ámbito de los videojuegos y la animación, los voxeles se han vuelto populares para el modelado de objetos tridimensionales con un estilo pixelado en tres dimensiones, à la Minecraft.

Para estos modelos à la Minecraft se pueden utilizar paquetes de modelado generales, como: Blender, Maya, 3D Studio Max, etc., pero por lo general se recomienda el uso de editores especializados para este tipo de modelos, ya que ofrecen herramientas particulares que agilizan la creación de modelos. Algunos de estos editores son:
El flujo de modelado se refiere al proceso de creación de modelos tridimensionales mediante el uso de un software de modelado 3D. Este proceso depende del tipo de objeto tridimensional que se esté modelando y del tipo de proyecto en el que se esté trabajando. Algunos de los proceso de modelado más comunes son:
En el modelado desde cero, cada vértice y polígono se colocan individualmente para completar el objeto. Se utiliza herramientas de modelado, como la extrusión, creación de formas básicas y modelado poligonal, para crear un modelo 3D desde cero. Este método es popular para la creación de personajes y objetos personalizados, ya que proporciona un alto nivel de control y precisión en la creación del modelo.
Aunque es una técnica popular, a causa de los avances en las herramientas de modelado y edición de los programas de modelado tridimensional, esta técnica se utiliza menos en la actualidad, y en lugar de mover vértice por vértice, se editan grupos de vértices o caras para hacer el proceso de modelado más eficiente.
El modelado con primitivas implica crear un modelo 3D a partir de formas predefinidas, como cubos, esferas y cilindros, que son proporcionadas por el software, estas formas básicas se combinan y modifican para crear modelos más complejos. Este método es rápido y eficiente para crear modelos simples, y es útil para crear superficies rígidas como mesas, sillas, robots o armas; también sirve como base para otros procesos de modelado, como el modelado con arcilla digital, ya que permite determinar el volumen inicial que ocuparán los objetos.

El modelado basado en cajas construye un modelo 3D a partir de un cubo, que poco a poco se va moldeando y modificando para crear la forma deseada. Este método se utiliza para crear personajes y objetos orgánicos, ya que permite una gran cantidad de flexibilidad y control, para ello, se extruyen diferentes partes (como las extremidades de una persona o partes de un mueble) que conforman el modelo, y se realizan cortes y subdivisiones para agregar más detalles.
Este método de modelado es popular, ya que brinda una noción del volumen del objeto durante la construcción inicial y, al mismo tiempo, permite un control fino sobre las características finales. Así mismo, como el proceso utiliza una serie de pasos repetitivos para llegar al producto final, permite un modelado más eficiente y controlado.






En el modelado con operaciones booleanas se combinan formas básicas utilizando operaciones booleanas como unión, intersección y diferencia para crear modelos complejos a partir de objetos más sencillos. Este enfoque es popular en el diseño mecánico y arquitectónico, donde se requieren formas geométricas con bordes bien definidos, sin embargo, uno de los principales desafíos de este método es que los algoritmos utilizados para realizar las operaciones booleanas pueden generar muchos polígonos con múltiples vértices, lo que puede complicar la topología del modelo.


El modelado por escaneo láser consiste en digitalizar objetos reales utilizando un sensor, generalmente un láser. Una vez escaneado el objeto físico, se importa la información a un software de modelado 3D para su posterior edición y refinamiento. Este método es útil para la creación de modelos precisos de objetos existentes y puede ahorrar tiempo en el proceso de modelado, aunque se debe considerar que la información obtenida a través del escaneo láser suele ser una nube de puntos densa y poco usable de primera instancia, lo que requiere limpiar y adecuar la geometría para su uso en un proyecto específico.


La escultura digital es una técnica de modelado que ha crecido en popularidad en los últimos años, ya que permite crear modelos 3D complejos y detallados. Esta técnica implica el uso de herramientas de escultura digital (como empujar, jalar, suavizar, entre otras) para crear modelos a partir de una malla de polígonos, evitando operaciones puntuales sobre vértices, aristas o caras.
Al igual que los objetos escaneados por láser, las esculturas digitales pueden generar modelos con grandes cantidades de caras, lo que puede ser un problema para su uso en algunos medios finales (como los videojuegos). Para abordar este problema, se utiliza un proceso llamado retopología (retopology), que implica la recreación o reconstrucción de una malla 3D de alta resolución en una malla 3D de baja resolución y con una topología limpia y optimizada. El objetivo de este proceso es crear una malla adecuada para animación y renderizado en tiempo real, asegurándose de que el flujo de aristas sea correcto y que no haya triángulos o cuadriláteros deformados. Aunque la retopología puede ser una tarea tediosa, es esencial para crear modelos 3D limpios y bien estructurados.






Como se mencionó en el funcionamiento del sistema de visión humano, para percibir un objeto es necesario que exista una fuente de iluminación, y los rayos de luz que se reflejan al interactuar con un objeto y llegan hasta los ojos, son los que estimulan los conos y los bastones formando la imagen correspondiente.
Entonces es necesario comprender el tipo de interacciones que pueden tener la luz con los objetos, y con esto construir modelos computacionales que pueden aproximar el efecto causado por estás interacciones. En la se observa que las interacciones son: la reflexión difusa, la reflexión especular, la absorción, la transmisión, la refracción y la dispersión.

Cuando la luz incide sobre la superficie de un objeto, una parte de esa luz se dispersa uniformemente en todas las direcciones, un fenómeno conocido como reflexión difusa. Este tipo de reflexión ocurre debido a la capacidad del material para reflejar la luz uniformemente en todas las direcciones, lo cual resulta de la interacción de la luz con una superficie rugosa, y es característica de materiales opacos y con superficies mate, como la madera, las piedras o el papel, que tienen un alto nivel de reflexión difusa.
Cuando un material refleja la luz en una dirección específica que depende directamente de la dirección de la luz incidente, se produce una reflexión especular. Este tipo de reflexión esta determinada por la capacidad de un material para reflejar la luz en una dirección concreta, y se puede observar en metales, plásticos y superficies brillantes, que poseen una alta cantidad de reflejo especular.
La luz puede ser absorbida por un objeto, dependiendo del material del que está hecho, cuando esto sucede, la energía de la luz se transforma en energía interna del objeto, lo que por lo general produce calor. En gran medida todos los objetos de colores, absorben ciertas longitudes de onda y permiten que se reflejen otras, las que al llegar a los ojos son las que se perciben como el color del objeto.
Al llegar la luz a un objeto, una cantidad de luz puede propagarse hacia su interior, lo que se conoce como luz transmitida. La transmisión es la capacidad de un material para permitir el paso de la luz a través de su superficie; los materiales transparentes suelen tener una alta cantidad de transmisión de la luz.
Parte de la luz transmitida puede salir del objeto por el lado opuesto al que entró y a está luz se le llama luz refractada. Lo que se refiere a la desviación de la luz que ocurre cuando pasa a través de un material con un índice de refracción diferente al del medio circundante. Los materiales con alta refracción se utilizan en lentes, prismas y otros objetos ópticos.
Otra parte de la luz transmitida puede dispersarse en direcciones aleatorias debido a la composición interna del material, y a esta luz se le conoce como luz dispersa. La luz dispersa se refiere a la difusión de la luz en todas las direcciones al pasar a través de un medio, lo que puede dar la apariencia de neblina o polvo en suspensión, los materiales con alta cantidad de luz dispersa presentan este efecto.
En ocasiones, parte de la luz dispersada puede salir del material en puntos alejados de donde entra la luz en la superficie, lo que se conoce como dispersión por debajo de la superficie o dispersión subsuperficial (subsurface scattering), essto provoca que el objeto parezca tener luz suspendida en su interior dando una apariencia translúcida, como ocurre por ejemplo en la piel o la leche.
En una escena la luz generalmente no proviene de un solo punto de iluminación, sino de múltiples fuentes de iluminación alrededor de los objetos. La luz se dispersa y se refleja en múltiples direcciones, no solo en lugares directamente frente a la fuente de iluminación, sino que también se refleja en superficies y alcanza otros objetos para ilumnarlos indirectamente.
Los algoritmos que tienen en cuenta la mayor cantidad de interacciones de luz con el ambiente y los materiales de los objetos se conocen como algoritmos o modelos de iluminación global, y suelen ser computacionalmente complejos y costosos, ya que tienen en cuenta muchos cálculos para simular las diversas interacciones de la luz.
Para simplificar la complejidad de la interacción de la luz en gráficas interactivas, o gráficas que se generan en tiempo real, se utilizan comúnmente modelos de iluminación local, los cuales simplifican los cálculos complejos para general imágenes con una apariencia aceptable, pero descartando o simulando muchas de las interacciones de la luz con los objetos. En estos modelos por lo general se da énfasis en la reflexión de la luz sobre la superficie de los objetos.
En graficación por computadora, para la representación y creación de escenas se utilizan algunos tipos básicos de fuentes de iluminación, como son: luz ambiental, luz puntual, luz de reflector o spotlight, luz direccional y luz aérea. Cada tipo de luz ilumina los objetos de una escena de manera diferente, con distintos niveles de carga y complejidad en los cálculos.
La luz ambiental es una técnica que permite simular la luz indirecta, es decir, la cantidad de luz que un objeto recibe a través de las reflexiones de la luz en objetos cercanos, esto permite que los objetos de una escena sean visibles aunque no haya una fuente de iluminación directa. Se trata por lo general de un color que se multiplica por el color de los objetos de la escena y puede ser atenuado o amplificado por un factor de intensidad, y dado que la luz ambiental está compuesta por tres canales (rojo, verde y azul), se puede ajustar cada uno de ellos para conseguir el efecto deseado. Una consecuencia que se obtiene al utilizar la luz ambiental, es que las sombras atenúan su oscuridad, haciendo que no sean completamente negras.
Para representar una luz puntual se utiliza un objeto con un color y posición determinados, el cual emite luz en todas direcciones. Por lo general, las luces puntuales iluminan un modelo con información asociada a sus vértices, y su intensidad puede mantenerse constante o para lograr un efecto más realista, variar proporcionalmente a la inversa de la distancia entre la luz y la superficie al cuadrado.
Durante el cálculo de la iluminación, se utiliza la posición de la luz en el espacio del mundo y las coordenadas del vértice que se desea iluminar para determinar la dirección y la distancia de la luz, que junto con la normal asignada al vértice se calcula la contribución de la luz a la iluminación de la superficie. Un ejemplo común de luz puntual es un foco.

La luz de reflector, también conocida como spotlight, tiene un rango de acción estrecho que limita el ángulo en el que se emite la luz. Para construir una luz de reflector se puede utilizar una luz puntual y limitar su ángulo de emisión. Este tipo de luces se caracteriza por tener una posición, un color y una dirección en la que emiten luz.
La luz emitida por una luz de reflector está compuesta por un cono interior brillante y uno exterior ligeramente más grande, con la intensidad de la luz disminuyendo entre los dos, estas luces están sujetas a factores como la atenuación y el alcance.
La luz direccional es una fuente de luz que solo consta de una dirección, un color y una intensidad, sin tener en cuenta su posición. La luz que emite esta fuente de iluminación viaja a través de una escena siguiendo siempre la misma dirección.
Es posible imaginar una luz direccional como si se tratara de una fuente de luz puntual colocada a una distancia muy lejana, donde la intensidad de la luz se mantiene constante y no se ve atenuada por la distancia, por ejemplo la luz que llega del sol hacia la tierra puede considerarse como una luz direccional.

La luz aérea o de área corresponde a un objeto 3D que emite luz, es decir, son fuentes de iluminación que tiene una forma, usualmente un rectángulo, en lugar de ser simplemente un punto o una dirección.
Este tipo de luz produce sombras suaves y una iluminación más realista que las luces anteriores. Aún así, es importante mencionar que este tipo de fuentes de iluminación son más costosas de calcular, y tener muchas fuentes de este tipo puede ralentizar el render de una escena.
En el mundo real un material corresponde a los componentes que conforman un objeto, es decir, los elementos de los que está hecho. Estos materiales determinan las diversas características que un objeto posee, entre ellas determina su apariencia.
En el contexto de la graficación y animación por computadora, los materiales definen las cualidades visuales de un modelo 3D y determinan cómo interactúan con la luz del entorno, por lo que son fundamentales para representar correctamente la apariencia de la superficie de un modelo.
Para generar una imagen a partir de una escena tridimensional, es necesario proyectar los modelos de la escena en el plano de la vista (viewing plane), siendo este plano análogo a una película de cine, los conos y bastones en los ojos, o los sensores CMOS de una cámara digital, con la diferencia de que se utiliza luz simulada en lugar de luz real para determinar los colores de los píxeles de los objetos virtuales. Los shaders son un conjunto de instrucciones que se utilizan para calcular las propiedades visuales de los modelos en gráficos por computadora, es decir, son programas con los que se obtienen los píxeles que conforman una imagen. Los materiales de los modelos pueden tener una gran variedad de propiedades o parámetros que los shaders deben considerar en sus cálculos para su presentación, algunas de las propiedades más comunes son: el color, el color del ambiente, la transparencia, la reflectividad, la refracción, la translucidez, los reflejos especulares, la incandescencia y el brillo. Estas propiedades permiten al shader determinar la apariencia final de los objetos en la escena renderizada, y pueden ser ajustadas para lograr diferentes efectos visuales.
De forma simplificada un material en graficación y animación por computadora, es un conjunto de parámetros utilizados por los shaders para determinar la apariencia de un objeto.

El color es el atributo más básico de los materiales y proporciona información esencial sobre su apariencia visual. Este atributo puede corresponder a un color directo o a uno obtenido mediante una textura (que consiste en muestrear los píxeles de una imagen para aplicarlos al objeto).

El color del ambiente es un color que afecta de forma general a todas las superficies de una escena, y se refiere a la luz indirecta que se genera en el entorno en el que se encuentra el objeto. Suele ser el valor mínimo que puede tener una sombra dentro de la escena.
La transparencia es un atributo que indica cuánta luz puede atravesar un objeto. Este atributo es fundamental para objetos como cristales o líquidos, ya que determina cuánta luz se refleja y cuánta se transmite a través del objeto.

La reflectividad especifica cómo se refleja la luz cuando colisiona con la superficie de un objeto. Esta propiedad se puede determinar mediante técnicas de trazado de rayos (ray tracing) o mediante mapas de reflexión, donde se muestran los objetos cercanos que se reflejan en la superficie del objeto.

La refracción es el cambio de dirección que experimenta la luz cuando pasa a través de un objeto. Esto puede causar una distorsión de los objetos que se encuentran detrás del objeto que refracta.
La translucidez se refiere a la cantidad de luz que puede atravesar un objeto opaco, como el papel o la piel. Este atributo es importante para simular objetos que permiten que la luz los atraviese, dando un aspecto translúcido.

Los reflejos especulares son zonas brillantes en la superficie de un objeto que reflejan intensamente las fuentes de luz. Estos reflejos se utilizan a menudo para simular objetos con superficies altamente reflectantes, como el metal, el vidrio o el plástico.

La incandescencia es el atributo que se utiliza a menudo para simular la emisión de luz por objetos que están calientes, como las brasas de un fuego. El brillo se refiere a la iluminación propia del objeto, y se utiliza para simular objetos que no son afectados por luces externas dando una apariencia plana al objeto.
La iluminación en el mundo real es un fenómeno complejo que depende de múltiples factores, que en la mayoría de los casos no se pueden calcular con exactitud o que toman mucho tiempo para calcularlos. Cuando la luz incide en una superficie, parte de la luz puede ser absorbida, otra parte puede ser reflejada de forma difusa y otra puede ser reflejada de forma especular. La cantidad de luz reflejada puede variar para diferentes longitudes de onda y la forma en que un material refleja la luz de diferentes longitudes de onda determina su color.
En gráficos por computadora se definen modelos matemáticos que simulan o aproximan la interacción de las luces con los materiales de los objetos, utilizando cálculos simplificados que aproximan la realidad, estos modelos matemáticos se conocen como modelos de iluminación.
Uno de los modelos de iluminación locales más conocidos es el modelo de iluminación de Phong, el cual se utiliza para describir la forma en la que la luz se refleja al interactuar con la superficie de un objeto. Para ello se consideran tres componentes básicos: la luz ambiental, la luz difusa y la luz especular.
Es importante mencionar que el modelo de iluminación de Phong solo considera la luz reflejada por la superficie de un objeto, descartando cosas como la transmisión, refracción o translucidez del material. Esto con la finalidad de presentar una modelo simplificado que pueda calcularse en tiempo real. La cantidad de luz reflejada que llega al observador o a la cámara virtual se expresa como la combinación de la luz ambiental, la luz difusa y la luz especular:
$$L_{\textsf{reflejada}} = L_{\textsf{ambiental}} + L_{\textsf{difusa}} + L_{\textsf{especular}}$$En la mayoría de los entornos naturales hay presencia de luz aunque parezca oscuro, esta luz puede ser proporcionada por fuentes lumínicas lejanas, como la luna, o filtrarse desde fuentes cercanas. La luz ambiental es aquella que no proviene directamente de una fuente de luz particular, sino que es la luz que se refleja y difunde en todas direcciones, esto ocasiona que las sombras no sean completamente negras. Aunque la luz ambiental es una aproximación de la luz indirecta, es decir aquella reflejada múltiples veces, es importante considerarla en lugar de ignorarla por completo, ya que tiene un efecto significativo en la iluminación de los objetos. En graficación por computadora, se utiliza el componente de luz ambiental para simular este efecto, proporcionando un valor constante para iluminar las superficies de los objetos.
Para simular la iluminación directa que proporciona el color a un objeto, se utiliza el componente de luz difusa, que es el más importante del modelo de iluminación. Esta propiedad del material representa la proporción de luz incidente que se refleja difusamente en la superficie. Los colores más brillantes y saturados se muestran en las caras que están orientadas directamente hacia la fuente de iluminación. Las superficies rugosas tienden a reflejar más luz de forma difusa que las superficies suaves, ya que tienen una mayor cantidad de ángulos de reflexión disponibles, en cambio, las superficies suaves tienen menos ángulos de reflexión disponibles.
Entonces la reflexión difusa es el componente direccionalmente independiente de la luz reflejada, lo que significa que la luz que incide en la superficie es reflejada de forma independiente de la dirección de incidencia.
Johann Heinrich Lambert (1728-1777) fue un matemático, físico y astrónomo suizo que publicó trabajos sobre la reflexión de la luz, entre ellos, destaca la ley de Beer-Lambert, que establece la ley de absorción de la luz, donde se dice que un material puramente difuso es aquel que exhibe una reflexión lambertiana. En este modelo, la cantidad de luz reflejada depende únicamente de la dirección de incidencia de la luz. En efecto, una superficie difusa refleja más luz cuando la dirección incidente es perpendicular a la superficie, mientras que la reflexión disminuye a medida que se incrementa el ángulo de inclinación de la dirección de la luz incidente respecto a la normal de la superficie.
Para modelar este fenómeno, se utiliza el coseno del ángulo entre la normal de la superficie y la dirección de incidencia de la luz. La cantidad de luz reflejada $L_{\textsf{difusa}}$ para una superficie se puede expresar mediante la siguiente ecuación:
$$L_{\textsf{difusa}} = L_{\textsf{incidente}} K_{\textsf{difuso}} cos(θ)$$Aquí, $L_{\textsf{incidente}}$ representa la cantidad de luz incidente y $θ$ corresponde al ángulo de inclinación del vector de la luz incidente, es decir, el ángulo formado entre la normal de la superficie y la dirección de la luz. $K_{\textsf{difuso}}$ es una constante que indica que tan difusiva es la superficie.

El término coseno en la ecuación anterior se puede expresar mediante la relación del producto escalar de dos vectores normalizados y el coseno del ángulo entre ellos, de la siguiente forma:
$$cos(θ) = N \cdot L_{\textsf{incidente}}$$De esta manera se obtiene la expresión estándar para la reflexión lambertiana:
$$L_{\textsf{difusa}} = L_{\textsf{incidente}} K_{\textsf{difuso}} (N \cdot L_{\textsf{incidente}})$$La luz especular muestra los puntos brillantes en objetos reflectantes, determinando la intensidad de sus reflejos según la dirección de luz incidente y el coeficiente de reflexión de la superficie. Aunque es más intensa que la luz difusa, su brillo disminuye rápidamente sobre la superficie del objeto, además calcular la iluminación especular es más costoso que calcular la iluminación difusa, pero hay que considerar que añade detalles significativos a la apariencia de una superficie.
La reflexión especular es el componente de la luz reflejada que depende de la dirección de incidencia de la luz y de la dirección en la que se refleja.
En una superficie especular ideal, como un espejo, la luz se refleja con un ángulo de incidencia igual al ángulo de reflexión.

En superficies no ideales, la luz se dispersa alrededor de la dirección del reflejo, considerando un cierto ángulo a su alrededor.

Para expresar la dirección de reflexión de una superficie especular, se emplea el álgebra vectorial, utilizando la siguiente fórmula:
$$R = 2N(N \cdot L) − L$$Donde $N$ es el vector normal a la superficie, $L$ es el vector de la dirección de la luz incidente y $R$ es el vector de la dirección de la reflexión ().



El enfoque del renderizado basado en física (Physically Based Rendering, PBR) consiste en producir gráficos con una mayor precisión en el tratamiento de la luz en el mundo real. Este enfoque se basa en la idea de que todo en el mundo refleja en menor o mayor medida la luz. Para lograr este objetivo, se utiliza la fotogrametría, que consiste en medir las características de los materiales del mundo real a través de fotografías y replicar los rangos de color, brillo y reflexión. El PBR también se enfoca en las microfacetas o microcaras, que son características muy pequeñas del material que proporcionan información adicional y simulan detalles microscópicos. En el renderizado basado en física por lo general se utiliza una de las siguientes funciones matemáticas: la función de distribución de reflectancia bidireccional (BRDF) y la función de distribución de dispersión bidireccional (BSDF), las cuales aproximan de manera cercana las propiedades físicas y ópticas de un material, y son eficientes para su cálculo.
La BRDF describe cómo la luz se refleja en una superficie y se utiliza para simular el comportamiento de la luz en la superficie de un objeto, tomando como entrada la dirección de la luz incidente y la dirección desde la cual se está viendo la superficie (conocida como ángulo de visión o de vista) y devuelve la cantidad de luz reflejada en cada dirección. Esta función esencialmente define cómo la luz es reflejada por un objeto.
Por otro lado, la BSDF tiene en cuenta la dispersión de la luz que ocurre cuando la luz se refleja o refracta en una superficie y se difunde en varias direcciones, tomando como entrada la dirección de la luz incidente y la dirección de vista, similar a la BRDF, pero también incluye información sobre la dirección de dispersión de la luz. Esta función se utiliza principalmente para simular materiales que difunden la luz en múltiples direcciones, como la piel humana o la tela.
La principal diferencia entre la BRDF y la BSDF es que la primera describe la reflexión de la luz en superficies opacas, mientras que la segunda describe tanto la reflexión como la transmisión de la luz en materiales, incluyendo los translúcidos y transparentes. En general, la BSDF suele ser más compleja que la BRDF pero permite una simulación más realista de materiales que difunden la luz en múltiples direcciones.


El renderizado basado en física es un tema avanzado en el campo de la graficación por computadora y para conocer más sobre el tema, se recomienda el libro: “Physically Based Rendering from Theory to Implementation”, actualmente en su cuarta edición que está disponible de forma gratuita para su lectura en el siguiente enlace: https://www.pbrt.org/.

El mapeo de texturas es una técnica comúnmente empleada en la graficación por computadora para otorgar una apariencia más realista y detallada a los modelos 3D. Esta técnica consiste en aplicar una imagen, también conocida como textura, sobre una superficie tridimensional, para ello, se utiliza el proceso de mapeo de texturas donde a cada vértice de un modelo 3D se le asigna un punto de la imagen. Los píxeles de una imagen utilizada como textura se denominan téxeles (texture element).
En la graficación por computadora, las coordenadas de textura o coordenadas UV son un conjunto de valores que se utilizan para asignar una sección específica de una textura a una superficie 3D o un polígono. Generalmente estas coordenadas se especifican en un rango de $0$ a $1$, y se ubican en un sistema de referencia en el que el origen se encuentra en la esquina inferior izquierda de la imagen, y la esquina superior derecha está en la coordenada $(1, 1).$ A esta región se le conoce como espacio de textura y en este espacio cada punto se representa mediante un par de coordenadas $(u, v)$, siendo $u$ la coordenada horizontal y $v$ la coordenada vertical.
¿Qué sucede si se utiliza una coordenada fuera del espacio de textura? En este caso se realiza un mapeo completo de $-∞$ a $∞$ en ambas direcciones llamado envoltura de textura (texture wrapping) y usualmente se puede especificar de dos formas: restringir (clamp) y repetir (repeat).
En el modo de restricción (clamp) las coordenadas de textura se limitan al rango de $0$ a $1$, y si alguna coordenada se encuentra fuera de ese rango, se ajusta al valor más cercano dentro del rango. Por ejemplo, una coordenada de textura de $-0.1$ se ajustaría al valor en $0$, y una coordenada de textura de $1.2$ se ajustaría al valor en $1.$ Esto significa que los píxeles fuera del rango $0$ a $1$ no se repetirán ni se extenderán más allá del límite de la textura.

En cambio, en el modo de repetición (repeat) la textura se replica a lo largo del eje horizontal y/o vertical para rellenar el espacio que está fuera del rango $0$ a $1$ y si una coordenada de textura se encuentra fuera del rango de $[0,1]$ se descarta la parte entera, lo que ocasiona que las coordenadas siempre se encuentren acotadas, dando del efecto de que la textura se repite múltiples veces. Por ejemplo, si una textura se define para repetirse en el eje horizontal y se tiene una coordenada $u$ de $1.2$, el valor que realmente se usa es el de $0.2$, es decir, descartar la parte entera de la coordenada. Este modo es especialmente útil para crear patrones y texturas que se repiten en diversas direcciones.

Los mapas UV son representaciones en dos dimensiones de los polígonos que conforman un objeto tridimensional, se utilizan para asignar coordenadas de textura a cada vértice de la superficie tridimensional, lo que permite mapear una imagen a las caras del modelo. El proceso de mapeo de texturas generalmente implica la creación del mapa UV, la aplicación de la textura al mapa y la posterior asignación del mapa UV a la superficie tridimensional.
Los programas de modelado 3D cuentan con herramientas, como el desenvolvimiento de la malla (unwrap), para crear mapas UV a partir de los polígonos del modelo. También se pueden crear mapas UV mediante funciones de proyección, como la plana, cilíndrica o esférica.

Las texturas se pueden entender como información almacenada en matrices uni, bi y tridimensionales, aunque por lo general se utilizan imágenes para su representación, es decir, texturas bidimensionales. Las texturas pueden ser generadas de forma procedural a partir de funciones que producen patrones variados; o pueden ser mapas de bits que contengan fotografías; o imágenes generadas por editores especializados.
Las texturas procedurales son creadas a través de algoritmos que generan patrones como celdas, gradientes, ondas, fractales, tableros, entre otros (). Estas texturas se crean de forma matemática en lugar de ser creadas manualmente, esto significa que no están basadas en ninguna imagen o fotografía existente y se pueden crear de forma dinámica durante el proceso de renderizado. Las texturas procedurales pueden simular efectos como el ruido, el patrón de madera o el patrón de mármol, lo que las hace muy útiles para crear materiales complejos y orgánicos. Además, al ser generadas en tiempo real, pueden ser muy eficientes en cuanto a la memoria y la velocidad de procesamiento.
Las texturas procedurales tienen la ventaja de ser independientes de la resolución, no presentar patrones repetitivos al cubrir las superficies y ser proyectables, es decir, se pueden mapearse a la superficie sin la necesidad de utilizar mapas UV explícitos.
Sin embargo, la desventaja de las texturas procedurales radica en la dificultad para controlar con precisión la ubicación de los detalles en el modelo. Por ejemplo, si se desea crear una pequeña mancha en una parte específica del modelo, con una textura procedural la mancha aparecerá en todo el modelo ya que no se tiene un control fino para su colocación.

En cuanto a la creación de texturas, existe otro tipo conocido como texturas basadas en mapas de bits. En este caso, estas texturas se generan a partir de una imagen o fotografía existente y se aplican a una superficie 3D mediante la utilización de coordenadas de textura asignadas a los vértices de la superficie 3D. La principal ventaja de las texturas basadas en mapas de bits es que pueden ser muy detalladas y realistas, lo que las hace ideales para la creación de materiales como madera, piedra y metal. A pesar de ello, su uso puede ser menos eficiente en términos de memoria y rendimiento, especialmente si se utilizan imágenes de alta resolución. Además, estas texturas son dependientes de la resolución en la que fueron creadas, lo que puede causar efectos de pixelado y distorsión al ampliar su tamaño.
Ambos tipos de texturas se utilizan para especificar diversos mapeos de información en los shaders y por ello son conocidos como mapas de texturas. Es importante entender que las texturas no solo permiten representar información de color, sino que también pueden representar atributos como: el relieve, el valor especular, la transparencia, el desplazamiento, las normales, la reflexión, entre otros más.
Un mapa de color es una textura básica que proporciona información sobre los colores de la geometría del modelo. Este tipo de mapa de textura es comúnmente utilizado para agregar detalles de color y apariencia a una superficie 3D.

Un mapa de relieve (bump map) utiliza una imagen en escala de grises para crear la ilusión de profundidad en la superficie de un modelo. Los tonos claros y oscuros de la imagen determinan qué áreas parecen más levantadas o profundas, respectivamente. Este mapa de textura es útil para simular la profundidad y textura de una superficie sin necesidad de agregar geometría adicional, ya que al aplicar este mapa de textura se desplazan los píxeles de la superficie 3D en función de las variaciones de luz y sombra presentes en la textura.

Un mapa especular afecta la forma en que se muestran los brillos especulares en la superficie, añadiendo ruido y detalles al modelo. Se utiliza para controlar la cantidad y posición del brillo de la reflexión especular en una superficie simulando el reflejo de la luz, lo que es particularmente útil para representar el brillo de un objeto metálico o la luz que refleja una superficie húmeda.

Los mapas de transparencia controlan la opacidad de una superficie 3D, siendo útiles para agregar color o suciedad a objetos de cristal, como vidrio o agua.
Los mapas de desplazamiento se utilizan para agregar detalles y complejidad a la superficie de un modelo 3D mediante el desplazamiento de los vértices de la geometría. Son imágenes en escala de grises que se aplican durante los cálculos realizados en los shader de vértices; de esta forma se puede crear la ilusión de una superficie con profundidad y rugosidad.

Los mapas de normales proporcionan información sobre las normales de las caras del modelo, utilizando los componentes RGB de la imagen para representar las coordenadas $X$, $Y$ y $Z$ de los vectores normales. Estos mapas de textura permiten modificar la dirección de las normales de la superficie 3D, lo que ayuda a mejorar la iluminación de la superficie y simular la rugosidad, ya que una textura puede contener mucha información fina sobre las normales de una superficie.

Para lograr una animación efectiva de objetos 3D, se requiere un sistema que permita a los animadores controlar y ajustar la posición de la geometría con flexibilidad. Todos los objetos 3D destinados a ser animados necesitan contar con algún tipo de mecanismo que permita a los animadores mover la geometría en la posición deseada.
A este sistema se le conoce comúnmente como rig y es esencial para animar personajes articulados. De hecho, el rig es el mecanismo más utilizado para animar este tipo de personajes.


El rigging es una técnica que tiene como objetivo facilitar el trabajo del animador, permitiéndole transformar la geometría de los modelos 3D a través de un número limitado de elementos de control. Los rigs son sistemas de control que se crean y aplican a los objetos 3D para permitir un movimiento natural y realista de los personajes y otros objetos en una animación. Existen varios tipos de rigs que se adaptan a diferentes necesidades y requisitos de animación. Por ejemplo, los rigs para personajes humanoides tienen una estructura similar a la del esqueleto humano y presentan articulaciones en los hombros, codos, muñecas, caderas, rodillas y tobillos. El rigging es un proceso complejo que requiere una comprensión detallada de la anatomía y la física del movimiento, por lo que es importante que los riggers (las personas encargadas de construir los rigs) trabajen en estrecha colaboración con los animadores para garantizar que el rig se adapte a las necesidades específicas de la producción.
Una vez que se tiene el rigging, se utiliza una herramienta conocida como skinning para conectar la geometría del modelo 3D al sistema de articulaciones (o huesos) y que el modelo siga los cambios y transformaciones del rigging. El skinning es un proceso importante para la animación de personajes y criaturas, ya que permite que el modelo siga los movimientos del esqueleto de manera realista.
En el rigging, se utiliza una jerarquía de sistemas y controles que funcionan secuencialmente para crear la articulación de un objeto. La jerarquía básica consiste en una relación padre-hijo, donde el proceso de emparentamiento crea esta relación. Cuando se emparentan dos o más objetos, se crea un grupo, y cualquier objeto hijo puede transformarse independientemente de su padre, mientras que los hijos siguen la cadena de transformaciones del padre.
La posición de pivote o punto de pivote es crucial para establecer la posición correcta de manipulación del objeto, ya que determina la posición alrededor de la cual rota y desde la cual otros manipuladores transforman el objeto. Normalmente, el pivote se establece en el origen del sistema de referencia del modelo, es decir, el espacio del modelo.
El esqueleto, también conocido como armature en Blender, es un sistema jerárquico de huesos que se configura para utilizar diferentes deformadores en la malla. Se utiliza para cualquier tipo de modelo, ya sean objetos orgánicos o no orgánicos, y su función principal es facilitar la manipulación y animación del modelo 3D.

Existen dos categorías para crear el movimiento de los huesos (o articulaciones): cinemática directa o hacia adelante (forward kinematics, FK) y cinemática inversa o hacia atrás (inverse kinematics, IK). Ambos tipos de movimiento ofrecen al animador diferentes formas de abordar tareas específicas de animación.
La cinemática directa implica la transformación de los huesos en el orden jerárquico establecido, expresando explícitamente las transformaciones de cada hueso para conseguir una configuración determinada. Este método se utiliza para animar modelos 3D moviendo sus articulaciones, desde la raíz hasta las extremidades, en una dirección hacia adelante. El movimiento se logra moviendo los huesos del esqueleto, lo que a su vez mueve el modelo.
La cinemática inversa se refiere a la transformación de los huesos en el orden inverso de su jerarquía original, donde se expresa la configuración final dentro del espacio deseado, y se calcula automáticamente la secuencia de transformaciones de los huesos necesarias para llegar a dicha configuración. El animador establece la posición y orientación de la extremidad final (como la mano o el pie), y el software de animación calcula automáticamente los movimientos necesarios de los huesos del esqueleto para llegar a esa posición. La cinemática inversa es una técnica que simplifica la creación de poses y animaciones, pero en algunos casos es necesario ajustar manualmente algunos huesos, por lo que un sistema robusto de animación debe permitir utilizar ambos enfoques.

Una vez creado un sistema de esqueleto para un personaje, se aplican deformadores para que la geometría siga al esqueleto. Los deformadores permiten vincular el rigging con los componentes de la geometría, como los vértices, aristas y caras que componen la malla poligonal.
Entre los deformadores más utilizados se encuentran el skinning o envoltura, la jaula (o red o lattice) y los blendshapes.
Un deformador de skinning permite asignar pesos a los vértices que indican el nivel de influencia que cada hueso tiene sobre cada vértice en particular. Se utiliza para vincular la “piel” de un modelo a su esqueleto, permitiendo que la piel se deforme y se mueva de manera realista con los movimientos del esqueleto. Para ello, se utiliza la herramienta de pintado de pesos (weight painting, ).

Un deformador de lattice es una jaula de vértices que envuelve a la malla original, y al modificar los vértices que la componen se modifica la geometría del modelo envuelto. Con este deformador, es posible modificar la forma de un modelo 3D entero o en partes, mediante la modificación de un conjunto reducido de vértices que conforman la lattice.

Otra forma de deformadores que usualmente se utiliza para crear animaciones faciales son los blendshapes o shapekeys. En este tipo de deformador, se crean una serie de formas faciales predefinidas y luego se animan en diferentes proporciones para crear una variedad de expresiones faciales. Es necesario definir una malla en su configuración inicial (o base), y a partir de esta configuración inicial se modifican los vértices, aristas o caras para crear nuevas formas utilizando la misma geometría. De esta forma, se obtienen variaciones de la misma malla base.

Además de utilizarse para la creación de expresiones faciales, también se emplea para corregir problemas que puedan surgir en zonas donde la malla se doble de forma incorrecta durante la animación. Asimismo, es posible utilizar este tipo de deformador para crear la transición suave entre diferentes modelos tridimensionales mediante el morphing.

En resumen, el flujo de trabajo de rigging es el siguiente:




Un animador es responsable de dar vida a los personajes en la pantalla, logrando que los modelos 3D cambien de forma adecuada cuadro a cuadro para que se genere la ilusión de movimiento y se presente una animación. En la creación de una animación, por ejemplo, en la industria de los videojuegos, hay dos tipos de enfoques: la animación durante el juego (in-game animation) y la animación de las escenas cinemáticas (cut-scene animation), ambos tipos buscan presentar movimientos creíbles de los personajes. En la animación durante el juego se desarrollan movimientos generales para que el usuario pueda interactuar con el videojuego, mientras que en las escenas cinemáticas se crean movimientos y actuaciones coreografiadas para comunicar una historia.
En la industria del cine también se distingue entre dos tipos de animación: la animación de criaturas que se enfoca en movimientos realistas de seres vivos (reales o ficticios), y la animación actuada que utiliza acciones dirigidas y coreografiadas para comunicar una historia.
Estas diferencias sutiles en el enfoque de la animación requieren habilidades ligeramente distintas por parte del animador para construir los movimientos adecuados y lograr presentar de forma creíble los diferentes tipos de animación. A pesar de estas diferencias, los animadores utilizan las mismas herramientas para llevar a cabo su trabajo.
La mayoría de las aplicaciones de modelado y animación (como Blender, Maya, 3D Studio Max, entre otros) así como motores de videojuegos modernos (como Unreal, Unity, Godot, etc.) ofrecen un conjunto de herramientas para crear, modificar y controlar las animaciones.
En los editores de animación, se suele incluir una línea de tiempo (timeline) que muestra todos los fotogramas que conforman una animación. Es posible crear, editar y borrar fotogramas clave en esta línea de tiempo para construir secuencias de animación, es esencial en la animación, ya que permite controlar la duración de una animación y la ubicación de cada fotograma clave en el tiempo. Cada cuadro se muestra en una escala de tiempo horizontal, lo que permite ajustar el tiempo de forma individual para crear una animación suave y realista. Además, se pueden añadir capas y ajustar su opacidad para superponer diferentes elementos animados. El acto de moverse a través de la línea de tiempo se conoce como scrubbing.

En la mayoría de los programas de animación se incluye una herramienta conocida como editor de gráficos (graph editor) que permite manipular la interpolación utilizada para generar los fotogramas intermedios. Esta herramienta de animación permite ajustar los valores de una animación de manera más precisa y visual, y muestra las curvas de animación de los diferentes parámetros en función del tiempo, lo que permite modificar la velocidad y la aceleración de la animación en cualquier momento. También permite ajustar la amplitud y la escala de los valores de animación para asegurar una transición suave entre los diferentes fotogramas clave.
Las funciones de curva también conocidas como FCurves son representaciones visuales del método de interpolación utilizado entre los fotogramas clave. Corresponden a las curvas que se utilizan en el editor de gráficos para representar los valores de animación a lo largo del tiempo. Se suelen presentar tres tipos básicos de curvas: las curvas escalonadas, las curvas lineales y las curvas spline.
Las curvas escalonadas mantienen un valor constante hasta la aparición del siguiente fotograma clave, generando cambios abruptos y súbitos en la animación. Se pueden utilizar para controlar con precisión la posición en la que aparece un objeto o para animar el cambio de una textura que representa expresiones faciales en personajes caricaturescos.
Las curvas lineales cambian el valor de un objeto a una velocidad constante y homogénea, creando fotogramas intermedios a través de interpolación lineal. Este tipo de curvas se utiliza para controlar movimientos rápidos y mecánicos.
Las curvas spline usualmente usan curvas de Bézier, permiten una interpolación más suave y natural entre los fotogramas intermedios, lo que genera movimientos de aceleración o desaceleración (easing). Estas curvas suaves se ajustan a los puntos de control definidos en el editor de gráficas, y los valores de la curva entre cada par de puntos se calculan automáticamente para crear una animación más fluida y natural.
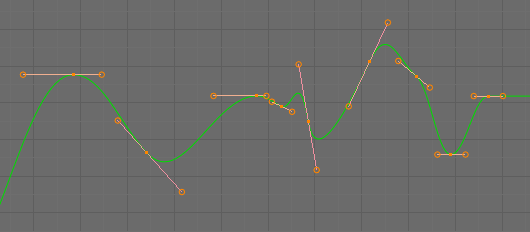
Una vez que se definen los keyframes así como el tipo y rango de movimiento, siempre es bueno ajustar las FCurves para conseguir mayor control en la animación final.
La hoja de información (dope sheet) es una herramienta de animación derivada de las hojas de exposición (exposure sheet) utilizadas en el mundo del cine y la animación tradicional. Su función es mostrar todos los cuadros clave de una animación en una tabla, lo que permite una vista detallada y precisa de los movimientos de los personajes. Permite ajustar fácilmente el tiempo de los cuadros clave y la velocidad de la animación. Además, es posible seleccionar varios cuadros clave para moverlos, escalarlos o copiarlos en bloques, lo que permite una animación más eficiente.
En la versión para animación por computadora la hoja de información muestra todos los keyframes de todos los objetos y controles, lo que permite manipular el tiempo en el que ocurren dichos fotogramas en la línea de tiempo.

Los doce principios de animación son un conjunto de técnicas y conceptos desarrollados por animadores de Disney en los años 30, específicamente por Frank Thomas y Ollie Johnston en su libro “The illusion of life: Disney Animation”. Estos principios continúan siendo considerados fundamentales para crear animaciones atractivas y creíbles, proporcionando criterios para realizar mejores animaciones.

Las técnicas de animación derivadas de estos principios permiten a los animadores crear movimientos más suaves y creíbles, lo que ayuda a crear animaciones más fluidas y realistas. Al seguir estos principios, los animadores pueden crear personajes con vida propia, capaces de transmitir emociones y sentimientos. Además, los principios de animación proporcionan una guía clara y concisa para los animadores, lo que les permite estructurar y planificar su trabajo, asegurándose de que están creando una animación coherente y atractiva.
Estos principios son una base sólida para el aprendizaje de la animación y son utilizados por muchos programas educativos en animación. Son fundamentales para la creación de animaciones de alta calidad y son aplicables a cualquier tipo de animación, desde la tradicional hasta la generada por computadora, esto debido a que se basan en observaciones de la vida real y los movimientos de los seres vivos, lo que los convierte en principios generales
En 1987, se publicó un artículo titulado “Principles of traditional animation applied to 3D computer animation” por John Lasseter. En él, se presentaron los doce principios de la animación tradicional y se explica cómo aplicarlos a la animación generada por computadora en 3D. La importancia de estos principios radica en que permiten producir animaciones de calidad en diferentes medios, incluyendo 2D, stop motion y animación por computadora, por lo tanto, estos principios son esenciales para producir animaciones de alta calidad en cualquier medio. Este artículo fue fundamental en el desarrollo de la animación en 3D, y John Lasseter, quien es uno de los fundadores de Pixar Animation Studios, fue uno de los primeros en aplicar estos principios en la producción de animaciones de alta calidad, como se evidencia en la película Toy Story.
Los doce principios son:
El principio de compresión y extensión (squash and stretch) se utiliza en la animación para proporcionar la ilusión de peso y volumen a personajes en movimiento.
Este principio se refiere a la deformación que experimentan los objetos cuando realizan una acción, ya sea comprimiéndose o estirándose. La aplicación de esta técnica ayuda a enfatizar el peso, la velocidad y la dirección del movimiento de un objeto. Por ejemplo, al saltar, un personaje se estira en el aire y se comprime al caer al suelo.

La anticipación (anticipation) es un principio de animación que consiste en preparar al público para una acción próxima mediante la presentación de los movimientos previos necesarios para su realización.
Este principio se refiere a la preparación que realiza un personaje antes de llevar a cabo una acción significativa. Por ejemplo, si un personaje va a lanzar una pelota, primero hará un movimiento hacia atrás para cargar su brazo antes del lanzamiento. De esta manera, la anticipación ayuda a que la acción principal sea más clara y efectiva para el espectador.
La puesta en escena (staging) es el principio que se encarga de presentar una idea de manera clara para el espectador.
Se utilizan técnicas de composición visual para lograr una presentación efectiva de la información. Esto incluye la composición de los elementos de la animación, la iluminación y la cámara, con el fin de garantizar que la acción sea fácil de entender.
La animación directa (straight ahead action) y la animación pose a pose (pose to pose) son dos técnicas básicas de animación. En la animación directa, el animador dibuja cada cuadro de forma secuencial, generando una sensación de movimiento fluido. Por otro lado, en la técnica pose a pose, el animador crea una serie de poses clave que definen los momentos importantes de la acción, y luego completa los espacios intermedios con dibujos adicionales.

Las acciones complementarias y superpuestas (follow through and overlapping action) son los movimientos que permiten expresar la inercia en una animación. Se refieren a los movimientos que se producen después de que un objeto o personaje haya completado su movimiento principal.
Una acción complementaria hace referencia a los movimientos adicionales que un objeto realiza después de haber completado su movimiento principal, mientras que la acción superpuesta se refiere a los movimientos adicionales que se producen mientras un objeto está en movimiento.

Acelerar y desacelerar (slow in and slow out) es un principio que indica que los objetos necesitan tiempo para acelerar al iniciar una acción y desacelerar al finalizarla, para dar una apariencia más natural a la animación.
El principio se refiere a la forma en que los objetos en el mundo real aceleran y desaceleran durante su movimiento; ya que los objetos no inician ni terminan un movimiento de forma abrupta, sino que lo hacen de forma gradual. Este principio ayuda a crear una sensación de peso y de inercia en los objetos animados.

Los arcos (arcs) son la forma natural en la que se realizan la mayoría de los movimientos. Esto se refiere a que los objetos se mueven a través del espacio siguiendo trayectorias curvas suaves, lo que los hace parecer más naturales y realistas que si se movieran en línea recta.
Los movimientos en línea recta por lo general se utilizan para representar movimientos mecánicos (robotizados).

La acción secundaria (secondary action) es una acción adicional que complementa a la acción principal, lo que da mayor profundidad al movimiento.
Se refiere a los movimientos adicionales que se agregan a una acción para enfatizar sus características y mejorar su interpretación.

La sincronización (timing) es el tiempo que toma completar una acción, lo que se refiere a la duración y velocidad de los movimientos en una animación.
Controlar el timing es importante para mantener un ritmo adecuado y coherente con la situación que se representa. Por ejemplo, un personaje que corre debe tener un timing rápido, mientras que un personaje que camina debe tener un timing más lento y fluido.

La exageración (exaggeration) consiste en amplificar los movimientos y expresiones de los personajes para crear una mayor sensación de energía y emoción.
La exageración puede utilizarse para hacer que una escena sea más interesante y enfatizar la personalidad, acciones y características del personaje.

El dibujo sólido (solid drawing) se refiere a la habilidad para crear personajes y objetos con una sensación de peso, volumen y profundidad.
Es importante tener en cuenta la perspectiva, la luz y las sombras para dar una sensación de tridimensionalidad a la animación y evitar que los objetos se vean planos.

El atractivo (appeal) se refiere a la capacidad de un personaje para ser interesante y atractivo para el público. Un personaje atractivo tiene un diseño visual interesante y una personalidad única y distintiva, lo que es importante para que el público se sienta identificado con el personaje y se interese en la historia que se está contando.

A continuación se presentan algunos ejemplos que ilustran los doce principios de animación, es importante destacar que el dominio de estos principios requiere no solo su comprensión, sino también mucha práctica y atención al detalle en su aplicación.




Las películas de Disney suelen presentar animaciones que intentan representar lo mejor posible la realidad, lo que implica un alto costo y tiempo de producción; en este sentido, los 12 principios de animación surgieron como una guía para lograr animaciones de alta calidad. Pero para multiples estudios de animación los costos que generaba la creación de animaciones tan detalladas no eran sostenibles, por lo que se buscaron nuevos métodos para optimizar el proceso de creación de una animación, intentando no perder la calidad ni la esencia en el camino.
El término animación limitada o limited animation se refiere a una técnica de animación que se popularizó en las décadas de 1950 y 1960 como respuesta a los altos costos y las restricciones de tiempo que se enfrentaban en la producción de animaciones para televisión. Esta técnica consiste en reducir la cantidad de movimiento y detalle en los personajes y fondos, para lograr una animación más rápida y económica, sin redibujar toos los cuadros por completo y recreando solo aquellas partes que cambian entre cuadros. En particular, se utilizan técnicas como la repetición del fondo de manera cíclica; el enfoque dramático en la expresión de los personajes; o la reducción en el número de cuadros por segundo utilizados para representar diferentes secuencias animadas.
A pesar de que algunos animadores tradicionales criticaron la técnica de animación limitada por su aparente falta de calidad y detalle, esta técnica se convirtió en una herramienta importante para la producción en masa de animaciones para televisión. La animación limitada permitió la producción de animaciones de manera más rápida y a menor costo, abriendo la puerta a nuevas formas de contenido animado que de otra forma no habrían sido posibles.
La animación limitada tiene un estilo visual característico que se utiliza principalmente en animaciones 2D para simplificar la creación de los diferentes cuadros que componen la animación. Estas animaciones hacen un amplio uso de los diálogos y la narración para contar la historia.
Hay que mencionar que, aunque la animación limitada surge principalmente en los estudios de animación estadounidenses, la técnica se popularizó en Asia, particularmente en Japón, donde gracias a la creación de nuevas formas de aprovechar la animación limitada crearon el boom en el Anime.


En el apartado correspondiente a los
En las animaciones en 3D, se pueden utilizar varias estrategias de la animación limitada, aunque el estilo de la animación suele ser menos fluido y más “caricaturesco”, lo que no se recomienda para animaciones con representaciones realistas.
Si se desea emular completamente el aspecto artístico de una animación 2D en una animación 3D, lo que incluye su representación visual y la forma en que se anima, se requiere un esfuerzo adicional, es decir, es necesario evitar que la computadora interpole suavemente la información entre los diferentes cuadros de la animación, lo que implica definir muchos más fotogramas clave de los que se utilizan normalmente en una animación 3D. A pesar de esto, diversos estudios de animación (y videojuegos) han logrado recrear satisfactoriamente este estilo visual tan característico ().

La captura de movimiento, también conocida como motion capture o simplemente mocap, es una técnica utilizada en la animación por computadora que consiste en registrar el movimiento de un actor o un objeto en el mundo real y aplicarlo a un modelo 3D en la computadora. Se utiliza para animar personajes y objetos de manera realista y detallada, y es particularmente útil para animaciones que requieren movimientos complejos y naturales de humanos o animales.
La rotoscopia es una de las primeras técnicas para reproducir movimientos de personas reales y utilizar esa información para copiar los movimientos en personajes animados, lo que se considera una forma primitiva de captura de movimiento.
La técnica conocida como captura de actuación (performance capture) consiste en registrar no solo el movimiento físico de un actor, sino también sus expresiones faciales, voz e interpretación emocional, permitiendo crear una grabación completa de la actuación que puede utilizarse para animar personajes en 3D de manera realista y detallada. Es una técnica avanzada que resulta muy útil en la animación de personajes en 3D, ya que permite crear personajes que se parezcan y actúen de manera similar a los actores reales, así como animaciones que incluyan emociones y expresiones faciales complejas, difíciles de lograr mediante técnicas de animación tradicionales.

Actualmente existen algunos métodos para realizar la captura de movimiento, que se pueden clasificar en dos grandes tipos: captura de movimiento óptica y captura de movimiento no óptica.
Los sistemas de captura de movimiento óptica registran el movimiento de objetos o actores por medio de marcadores físicos, tales como luces LED, reflectores, pelotas adheridas o marcas sobre la piel o ropa, colocados en lugares clave como las articulaciones. Estos sistemas utilizan cámaras especiales para registrar los marcadores y, mediante técnicas de procesamiento digital de imágenes, identificarlos y triangular sus posiciones.
La principal ventaja de estos sistemas es su comodidad, ya que no requieren un traje pesado y son menos costosos que los sistemas no ópticos. Sin embargo, una de sus desventajas es la baja precisión en la captura de algunos movimientos debido a factores como una iluminación deficiente o falta de contraste, lo que puede impedir el procesamiento adecuado de las imágenes capturadas para extraer información de movimiento.

Los sistemas de captura de movimiento no ópticos utilizan trajes mecánicos o exoesqueletos para capturar el movimiento directamente, así como sensores magnéticos para detectar las variaciones en el movimiento sobre un campo magnético. Estos sistemas utilizan dispositivos como acelerómetros, giroscopios y magnetómetros para medir la aceleración, rotación y orientación del sujeto en tiempo real, sin necesidad de marcadores adicionales colocados en el cuerpo.
La principal ventaja de los sistemas de captura de movimiento no ópticos es la gran precisión que ofrecen en comparación con los métodos ópticos, ya que los sensores permiten obtener información más precisa durante el movimiento. No obstante, su mayor desventaja es el elevado costo, debido a que los sensores son componentes especializados que tienen un precio más alto que los marcadores ópticos. Además, los sensores suelen ser más grandes o, en el caso de los exoesqueletos, más incómodos para el actor, lo que puede limitar la libertad de movimientos.

Sinbad: Beyond the Veil of Mists (2000) narra la historia del legendario marinero Sinbad, quien ayuda a una hermosa princesa a salvar a su padre y su reino costero de las garras de un mago malvado. Es notable por ser la primera película utilizo únicamente la técnica de captura de movimiento para la animación de sus personajes.

Uno de los personajes más icónicos y un ejemplo destacado de la captura de movimiento es Sméagol/Gollum en las trilogías cinematográficas de El Señor de los Anillos y El Hobbit. Andy Serkis, como actor, fue responsable de proporcionar la voz y los movimientos a este emblemático personaje, lo que enriqueció enormemente la caracterización del personaje.

En la actualidad, se pueden encontrar numerosas películas que emplean la captura de movimiento en su animación. Avengers: Endgame (2019), por ejemplo, utiliza sofisticadas técnicas de captura de movimiento y actuación para dar vida a diversos personajes animados.

En el ámbito de los videojuegos, varios títulos han utilizado la técnica de rotoscopia para generar los movimientos de sus personajes.
Prince of Persia creado en 1989 por Jordan Mechner, fue uno de los primeros videojuegos en utilizar la captura de movimiento para animar a sus personajes. Para ello, Mechner contrató a su hermano para que realizara las acrobacias necesarias para los movimientos del personaje principal del juego, fotografiando cada acción y posteriormente digitalizando las fotografías. De esta forma, se logró que los movimientos del personaje fueran muy realistas y fluidos, lo que ayudó a dar vida al Principe y aumentando con esto la inmersión del jugador en el juego.

El primer videojuego en 3D que aprovechó las técnicas modernas de captura de movimiento óptica fue Virtua Fighter 2, lanzado en 1994. En este juego, se capturaron los movimientos de los luchadores para transferirlos a los modelos 3D del juego, logrando movimientos de pelea realistas que proporcionaban un mayor detalle. Gracias a las innovadoras gráficas 3D, los personajes se movían con una gracia y fluidez impresionantes convirtiéndose en todo un éxito.

En el mundo de los videojuegos, al igual que en el cine, se pueden encontrar numerosos ejemplos en los que se utiliza la captura de movimiento. Devil May Cry 4 (2008) y Devil May Cry 5 (2019) son ejemplos de títulos que emplean diversas técnicas de captura de movimiento y actuación para dotar a sus personajes de animaciones fluidas y realistas.
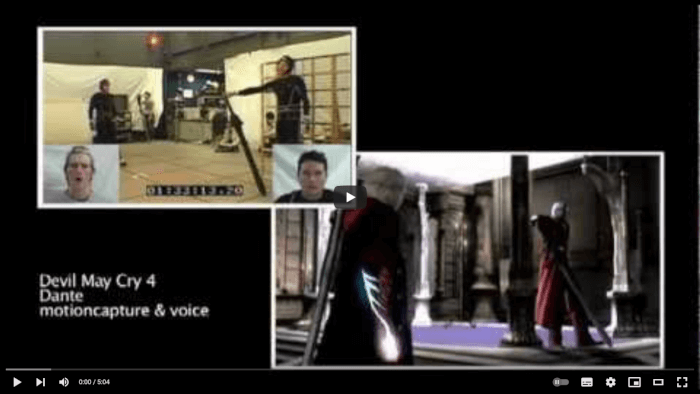

La captura de movimiento también tiene aplicaciones en el deporte, en particular en la biomecánica, que es el estudio de los movimientos humanos y su impacto en la anatomía del cuerpo. En este campo, se utiliza la captura de movimiento para recopilar datos sobre los movimientos humanos, analizar la mecánica propia del movimiento y mejorar la técnica y el rendimiento del atleta. Esto permite la evaluación de actividades deportivas con el objetivo de mejorar los movimientos específicos del deporte y prevenir lesiones, así como analizar de manera precisa las destrezas motoras, evaluar la técnica y corregir cualquier falla detectada.
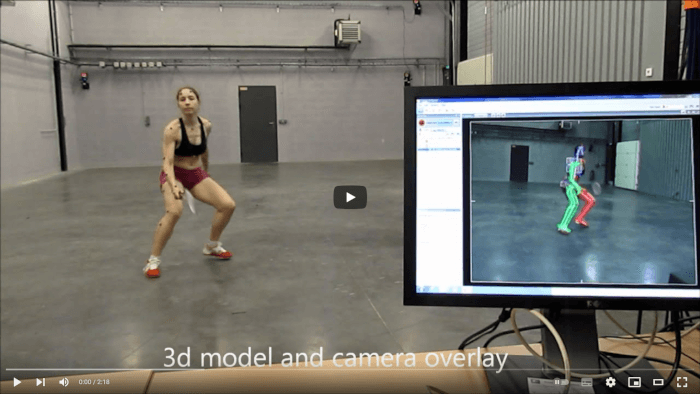

Hay sitios web que ofrecen archivos de captura de movimiento en formato BVH de forma gratuita, como por ejemplo http://mocap.cs.sfu.ca/ y http://mocap.cs.cmu.edu/. Sin embargo, estos archivos gratuitos a menudo tienen un conjunto de movimientos muy específicos que pueden resultar difíciles de adaptar a las necesidades particulares de una producción, y también pueden complicar su incorporación en animaciones ya existentes debido a la complejidad de trasladar la información de movimiento a esqueletos o rigs previamente creados.
En 2022 Bandai-Namco libero un conjunto de archivos de captura de movimiento que se pueden acceder a través de https://github.com/BandaiNamcoResearchInc/Bandai-Namco-Research-Motiondataset; y pueden ser utilizados de manera no comercial.
En la actualidad han comenzado a proliferar diversos servicios de captura de movimiento ya sea ofreciendo hardware y aplicaciones especializadas como: https://www.rokoko.com/; o por medio de la inteligencia artificial, como: https://plask.ai/.
Los efectos visuales 3D, las luces y el rendering son parte fundamental de las etapas finales de la fase de producción de una animación.
Los efectos visuales 3D permiten la creación y animación de procesos naturales que, en muchos casos, resultarían demasiado complejos para ser creados manualmente.

En términos generales, los efectos visuales 3D se pueden clasificar en cinco categorías principales: sistemas de partículas; cabello y pelo; fluidos; cuerpos rígidos y cuerpos suaves.
El término sistemas de partículas fue acuñado en torno al trabajo de William T. Reeves, investigador de Lucasfilm, mientas realizaba la película Star Trek II: The Wrath of Khan en 1982. En dicha película, gran parte de la trama gira en torno al dispositivo Génesis, un torpedo que puede terraformar (es decir, transformarlo en un planeta habitable) un planeta muerto; y durante la secuencia en que se activa el dispositivo, se presenta un muro de fuego ondeando sobre el planeta mientras éste está siendo terraformado. Actualmente los sistemas de partículas son muy común en graficación y animación por computadora.

La simulación de sistemas de partículas es una técnica ampliamente utilizada en la animación por computadora para representar el comportamiento de una gran cantidad de objetos pequeños y discretos (partículas) que se encuentran en un sistema dinámico.
Desde principios de la década de 1980, los sistemas de partículas han sido empleados en videojuegos, animaciones, piezas de arte digital, así como en el modelado y simulación de fenómenos naturales como fuego, humo, cascadas, niebla, pasto, burbujas, entre otros. El primer sistema de partículas en animación por computadora se utilizó en la serie de televisión de 1980 Cosmos: A Personal Voyage de Carl Sagan.

En una simulación de sistemas de partículas, cada partícula se modela como un objeto independiente con sus propias propiedades físicas, como la masa, la velocidad, la posición y la dirección del movimiento. Se aplican fuerzas a cada partícula para simular la interacción entre ellas y con su entorno, como la gravedad, la fricción, la fuerza del viento, la atracción magnética o eléctrica, entre otras.
Las partículas suelen ser representadas por puntos u objetos simples y son generadas por un emisor. Estas partículas se animan mediante campos o fuerzas que actúan sobre ellas. Para representar visualmente las partículas, se utilizan shaders que determinan su apariencia, de manera similar a los materiales que se aplican a objetos geométricos formados por polígonos. Es importante destacar que los puntos pueden representar solamente una posición y tener asociada una geometría o imagen externa, lo que permite representar diferentes tipos de partículas, como polvo, fuego, lluvia, nieve, parvadas de aves, enjambres de insectos, entre otros.
El emisor por su parte, puede ser cualquier objeto geométrico, desde un único punto hasta una malla poligonal, y tiene la propiedad de crear y emitir partículas desde él. Durante una simulación, el emisor es el elemento encargado de determinar las propiedades de cada partícula del sistema y también indica cuántas partículas se emiten por unidad de tiempo. Los emisores, por lo general, no tienen una representación visual, por lo que durante la simulación no son renderizados y solo se observa su efecto al crear nuevas partículas. Asimismo, es posible animar el emisor de forma individual, realizando transformaciones que afectan el estado inicial en el que se emiten las partículas.
Los campos y fuerzas que se aplican a las partículas son elementos que simulan el comportamiento de la naturaleza, tales como un campo de gravedad, viento o fricción, así como cualquier otra fuerza física que pueda mover o manipular las partículas.
A nivel de implementación, cada partícula en un sistema presenta los siguientes atributos:
El funcionamiento general de un sistema de partículas se basa en que cada partícula nace en un cuadro determinado y a partir de ahí modifica su edad en cada cuadro de la animación. Considerando su posición inicial, velocidad, aceleración y las fuerzas que se encuentren en su entorno, la partícula modifica su posición en cada cuadro. Una vez que una partícula alcanza el tiempo de vida máximo asignado por el emisor, está deja de actualizarse y desaparece del sistema.
Para crear un sistema de partículas en un programa de animación o simulación, es necesario realizar los siguientes pasos:




La segunda ley de Newton es una de las leyes fundamentales de la mecánica clásica, y establece la relación entre la fuerza, la masa y la aceleración de un objeto. Esta ley es de gran importancia en la física, ya que permite predecir el movimiento de un objeto al aplicarle una fuerza conocida.
La fórmula $f = ma$ ó $a = \dfrac{f}{m}$ indica que la aceleración es directamente proporcional a la fuerza e inversamente proporcional a la masa. Es decir, mientras más fuerza se aplique a un objeto, mayor será su velocidad; mientras que entre objetos de diferentes masas, aquellos más grandes se moverán más lentamente si se les aplica la misma fuerza que a objetos más pequeños.
En los sistemas de partículas, la segunda ley de Newton se usa para calcular la aceleración individual de cada partícula, en respuesta a las distintas fuerzas que actúan sobre ella. Para ello, se deben sumar todas las fuerzas que actúan sobre la partícula y calcular su aceleración resultante. A partir de esta información se puede actualizar su posición y velocidad en función del tiempo transcurrido en el sistema, mediante las ecuaciones de movimiento de la cinemática. Este proceso se repite en pequeños intervalos de tiempo para simular el movimiento de las partículas a lo largo del tiempo.
Es importante tener en cuenta que la segunda ley de Newton se aplica a cada partícula del sistema de forma individual, lo que implica que para simular el comportamiento del sistema, es necesario calcular la aceleración y posición de cada una de las partículas que lo conforman, y luego combinarlas para obtener el movimiento del sistema completo.
Cuando se configura un sistema de partículas, normalmente el animador especifica todas las posibles fuerzas que actúan sobre el ambiente, y con esta información se calcula cada cuadro de la animación. Una vez que se determinan las fuerzas que actúan sobre las partículas, se calcula la aceleración y con ello la velocidad y la posición.
Dada la velocidad actual de una partícula ($v$) y la nueva aceleración calculada (con $a = \frac{f}{m}$) se calcula la nueva velocidad $v'$ por medio de: $$v' = v + a Δt$$
La nueva posición $p'$ se obtiene a través de la posición anterior $p$, y el promedio entre la velocidad actual y la siguiente:
$$p' = p + \frac{1}{2} (v + v')Δt$$Una forma sencilla de representar estos cambios en código sería de la siguiente manera:
// se actualiza la aceleración de una partícula, // considerando que es un vector de la dimensión de // los objetos con los que se trabaja, es decir, 2, 3 // o más dimensiones Aceleración = Fuerza / Masa; // se actualiza la velocidad utilizando el valor de // la aceleración, considerando que la velocidad del // objeto aumenta respecto a la aceleración Velocidad = Velocidad + Aceleración; // por último se actualiza la posición de la partícula //utilizando la velocidad Posición = Posición + Velocidad;
En el libro interactivo “Nature of Code” de Daniel Shiffman (https://natureofcode.com/book/) se presenta la teoría y ejemplos de implementación de sistemas físicos. Este libro se centra en la exploración de cómo los principios de la física pueden aplicarse en la creación de arte, diseño y programación de sistemas complejos. Está dirigido a programadores, diseñadores y artistas interesados en la creación de sistemas dinámicos que imiten el comportamiento de la naturaleza, y es especialmente útil para aquellos que desean aprender a crear simulaciones de fenómenos naturales como el movimiento de partículas, la gravedad, la fricción, la oscilación y la ondulación, entre otros.
A lo largo del libro, se aborda la teoría detrás de los sistemas físicos y se presentan ejemplos prácticos de cómo implementar estos sistemas. Cada capítulo del libro contiene un conjunto de conceptos clave, ejemplos de código y actividades prácticas que permiten a los lectores experimentar con los conceptos presentados. Los temas cubiertos en el libro incluyen el movimiento de partículas, la simulación de sistemas de resortes y masas, la creación de sistemas de partículas y la simulación de sistemas de fluidos, así como también se exploran temas como la inteligencia artificial y la simulación de sistemas complejos.

En animación por computadora, la creación realista de cabello o pelo en personajes 3D es un desafío importante. Es posible crear cabello o pelo, a partir de modelos poligonales; lo cual es útil para crear personajes estilizados o caricaturescos, simplificando en gran medida la representación para gráficos en tiempo real, pero no permite una representación realista en la apariencia ni movimiento del cabello.



Para lograr una representación más realista y menos caricaturesca del cabello y el pelo, es necesario pensar en ellos como un conjunto de elementos individuales que interactúan con campos y fuerzas, teniendo en cuenta su comportamiento individual y en grupo. Para esto, la técnica de los sistemas de partículas es útil, representando cada pelo como una partícula única que interactúa con campos y fuerzas. En lugar de modelos poligonales, se utilizan segmentos o curvas para representar cada pelo o conjunto de pelos, y cada partícula se genera una sola vez al inicio de la simulación y se mantiene en el sistema durante toda la animación.



Esta misma técnica se puede utilizar para crear otros elementos de la naturaleza, como pasto, flores y árboles en un terreno, donde se representa cada planta o elemento individual como una partícula única y se define su comportamiento físico utilizando campos y fuerzas.

También es posible colocar elementos similares (o idénticos) sobre superficies, como chispas de chocolate en una dona, o gotas de agua sobre una manzana.


La simulación de fluidos se emplea en gráficos por computadora para generar animaciones de fluidos en movimiento, incluyendo agua, aire, lava, y otros fenómenos descritos como fluidos newtonianos (fluidos cuya viscosidad se considera constante). Esta técnica es ampliamente utilizada en la creación de efectos visuales para la industria del cine y los videojuegos, y se basa en la resolución de las ecuaciones de Navier-Stokes, que son ecuaciones diferenciales parciales con las que se describe el movimiento de un fluido en términos de su velocidad, presión, densidad, viscosidad y temperatura. Su solución permite predecir el movimiento del fluido en el espacio y en el tiempo. Las ecuaciones son:
$$\begin{align} \frac{\partial \overrightarrow{u}}{\partial t} + \overrightarrow{u} \cdot \nabla \overrightarrow{u} + \frac{1}{\rho} \nabla p &= \overrightarrow{g} + \nu \nabla \cdot \nabla \overrightarrow{u} \\ \nabla \cdot \overrightarrow{u} &= 0 \end{align}$$Donde la variable $u$ representa la velocidad del fluido.
La variable $ρ$ representa la densidad del fluido, para el agua se considera un valor de $1000kg/m^3$, y para el aire un valor de $1.3kg/m^3$.
La variable $p$ corresponde a la presión, es decir, la fuerza por unidad de área que el fluido ejerce sobre todo lo que está a su alrededor.
La variable $g$ es la aceleración causada por la gravedad, que suele tener el valor de $(0, −9.81, 0) m/s^2$.
La letra griega $ν$ representa la viscosidad cinemática, que es una propiedad que indica qué tan viscoso es el fluido y cuánto se resiste a la deformación mientras fluye.
La primera ecuación de Navier-Stokes surge de la segunda ley de Newton y relaciona los campos de velocidad y presión con la conservación del momento. Gracias a esta relación, se puede entender cómo la viscosidad, la gravedad y la presión están vinculadas con la aceleración que se ejerce sobre cada punto del fluido.
Por su parte, la segunda ecuación indica que el gradiente de la velocidad del fluido debe ser igual a $0$, lo que garantiza que la masa siempre se conserve, es decir, que el fluido sea incompresible.
Al realizar una simulación de fluidos, es común tomar en cuenta ciertas consideraciones debido al alto costo de resolución de las ecuaciones diferenciales. Para modelar el movimiento del fluido en un espacio tridimensional, se define un volumen que delimita el área de cálculo, el cual a su vez se divide en pequeñas celdas, donde se colocan las partículas a las que se les aplica las ecuaciones Navier-Stokes para determinar su movimiento dentro del volumen; el número de celdas y de partículas determina la resolución de la simulación.




La simulación de cuerpos rígidos es una técnica empleada para generar animaciones de objetos sólidos en un espacio tridimensional, que se comportan como cuerpos rígidos. Un cuerpo rígido es un objeto sólido que mantiene su forma y tamaño, y no se deforma ante fuerzas externas. En este tipo de simulación, se modela cada cuerpo rígido como un objeto con un centro de masa, una orientación y una velocidad, al cual se le aplican fuerzas y momentos para simular su movimiento y colisión con otros objetos. Dichas fuerzas y momentos se calculan utilizando las leyes de la mecánica de Newton y la ley de conservación del momento angular.
Por lo general, los cuerpos rígidos se incorporan en la animación por computadora mediante motores de física que utilizan las leyes de la mecánica clásica para simular el efecto de diversas fuerzas sobre los cuerpos. Estas simulaciones tienen aplicaciones en una amplia variedad de campos, como la animación de objetos en videojuegos y películas, la simulación de robots y maquinaria, la simulación de colisiones en ingeniería y física, así como en la creación de efectos visuales realistas, como la destrucción de objetos, el movimiento de vehículos y maquinaria, entre otros.




La simulación de cuerpos suaves se utiliza para simular objetos deformables como gomas, globos y otros materiales no rígidos. A diferencia de los cuerpos rígidos, los cuerpos suaves sí se deforman ante fuerzas externas y no mantienen por completo su forma y tamaño original mientras estén sometidos a ellas. En esta técnica cada objeto se modela como un sistema de partículas conectadas por resortes elásticos, donde se aplican fuerzas a cada partícula para simular la deformación y la tensión del objeto, tratando de preservar en la medida de lo posible su estructura inicial.
La simulación de cuerpos suaves se utiliza en diversas aplicaciones, tales como la animación de telas y ropa, la simulación de globos y juguetes blandos, así como en la simulación de órganos y tejidos biológicos.


Los sistemas de partículas, cuerpos rígidos y cuerpos suaves son herramientas muy versátiles en la creación de efectos visuales en la animación, simulación y graficación por computadora. A continuación, se presenta información adicional sobre cómo se pueden utilizar para crear diferentes efectos:
La simulación de humo y fuego se puede lograr mediante la generación de partículas pequeñas que se asemejan a la forma y el movimiento de las llamas y el humo. Estas partículas se pueden animar para simular la propagación del fuego y el humo en la escena. Además, se pueden utilizar técnicas de renderizado avanzadas, como el ray tracing y la iluminación volumétrica, para crear un efecto de representación realista de las partículas que componen la simulación de fuego y humo.



La combinación de sistemas de partículas con cuerpos rígidos y/o suaves puede crear efectos de explosión realistas. Por ejemplo, se puede simular la detonación de una bomba mediante la creación de partículas que representen los fragmentos de la explosión y el polvo que se produce. También se pueden utilizar sistemas de partículas para simular la onda expansiva de la explosión y su impacto en los objetos circundantes.


Los sistemas de partículas se pueden utilizar para simular la fractura de objetos en una escena. Por ejemplo, se puede crear una bola de cristal y simular su rotura en varias piezas utilizando partículas que representen los fragmentos. Además, se pueden utilizar sistemas de partículas para simular la dinámica de los objetos fracturados, como la forma en que rebotan o caen en la escena.

La simulación de ropa se realiza de forma similar a la simulación de cuerpos suaves, a través del modelo masa-resorte (mass-spring model) donde básicamente en cada vértice del modelo que simula la tela se asigna una masa y se agregan resortes como aristas que unen los vértices, de tal manera que variando la masa de cada nodo y la resistencia o elasticidad de los resortes, se pueden simular diferentes tipos de telas.



El rendering o síntesis de imágenes es un proceso crucial en la producción audiovisual, especialmente en la animación y los efectos visuales. Una vez creados los modelos 3D, rigs, animaciones, shaders, texturas, efectos especiales 3D y luces, es necesario convertir toda esta información en una imagen o serie de imágenes que puedan ser mostradas en un pantalla.
Para llevar a cabo este proceso se requiere de un motor de render (render engine), un software especializado que utiliza técnicas y algoritmos para calcular cómo se verá la escena en 3D, es decir, utiliza los principios de graficación presentados en secciones anteriores. El motor de render toma todos los datos y parámetros proporcionados por el artista 3D y genera las imágenes finales. Existen varios tipos de motores de render, siendo los más comunes los que se basan en dos métodos principales: rasterización y raytracing.
El método de rasterización es ampliamente utilizado en la industria del CGI debido a su velocidad y eficiencia para renderizar escenas complejas. Este proceso funciona mediante la división de la escena en pequeños triángulos que se procesan y dibujan individualmente, y que luego se combinan para formar la imagen final. Es ideal para escenas con muchos objetos y geometrías, ya que puede renderizar grandes cantidades de polígonos rápidamente. Además, se utiliza comúnmente para previsualizar escenas y realizar pruebas rápidas debido a su capacidad para producir resultados casi inmediatos.

No obstante, el método de rasterización presenta algunas limitaciones, ya que no proporciona un alto nivel de realismo en términos de efectos de iluminación y sombras, ya que se enfoca principalmente en la geometría y la textura de la escena, sin tener en cuenta la interacción compleja de la luz con los objetos. Además, este método no puede calcular efectos de iluminación global realistas, como la iluminación indirecta y las reflexiones/refracciones complejas. Para obtener resultados más realistas en términos de iluminación, se utilizan otros métodos de renderizado, como el raytracing o el path tracing.
A pesar de estas limitaciones, el método de rasterización sigue siendo muy útil en la industria de la animación y la graficación por computadora, especialmente para la generación de imágenes con modelos de iluminación simplificados o locales. Cabe destacar que la mayoría de las tarjetas de video (GPU) modernas utilizan el método de rasterización para la renderización en tiempo real de videojuegos y aplicaciones interactivas.
El método de raytracing se ha consolidado como un estándar en la industria de la animación y graficación por computadora debido a que ofrece resultados más realistas y detallados en comparación con el método de rasterización. El raytracing permite simular de manera precisa la interacción de la luz con los objetos de la escena, lo que se traduce en una mayor calidad visual y la creación de efectos de iluminación complejos, como sombras suaves, iluminación global y reflejos, que son difíciles de lograr con el método de rasterización. La forma en la que funciona es siguiendo la trayectoria de los rayos de luz para calcular cómo se reflejan y refractan dichos rayos a medida que atraviesan los objetos de la escena, lo que permite generar sombras precisas y detalladas, contribuyendo significativamente a la percepción de profundidad y realismo de la escena. El raytracing también es adecuado para la simulación de materiales complejos, como vidrios, metales, líquidos y superficies reflectantes, con lo que se pueden crear escenas mucho más realistas. Sin embargo, debido a que el raytracing es más preciso y complejo que el método de rasterización, requiere más recursos de hardware y tiempo para generar la una imagen, y es necesario ajustar cuidadosamente los parámetros de la escena y de los materiales utilizados en la misma para obtener resultados óptimos.


La iluminación global es una técnica empleada para simular la interacción de la luz con los objetos en una escena tridimensional. Su objetivo es crear efectos de iluminación realistas, como la luz reflejada, refractada y difusa en los objetos de la escena. Entre los métodos más conocidos, se encuentran el mapeado de fotones photon mapping e iluminación basada en imágenes.
El mapeado de fotones (Photon mapping) es un algoritmo de iluminación global que simula la propagación de partículas de luz, llamadas fotones, a través de la escena. Estos fotones son enviados desde las fuentes de luz y dejan marcas de brillo que después son muestreadas para determinar la intensidad final de la iluminación. Esta técnica es particularmente útil para simular la iluminación en escenas con superficies reflectantes y refractivas, como vidrio, agua y metal. Más información en: Real-Time Global Illumination with Photon Mapping.

La iluminación basada en imágenes (image based lighting) permite crear una esfera (o domo) alrededor de la escena con una imagen asignada, de tal manera que la imagen proporciona la información de iluminación. En esta técnica, se utiliza una imagen de alto rango dinámico (High-dynamic-range imaging, HDRI) para simular la iluminación ambiental en la escena. Esta imagen contiene información sobre la intensidad y el color de la luz en diferentes partes de la escena, y se utiliza para iluminar los objetos de la misma. Esta técnica es particularmente útil para simular la iluminación en escenas exteriores, donde la iluminación ambiental es la fuente principal de iluminación.
En la técnica de iluminación basada en imágenes, desde la cámara se muestrean rayos en la escena, y para cada uno de ellos se generan nuevos rayos de forma aleatoria. Estos nuevos rayos recolectan información de iluminación de todas aquellas superficies que alcanzan, normalmente la esfera que contiene la escena y la HDRI, y por último regresan la información de luz al punto que generó el rayo original.

Una imagen de alto rango dinámico es una imagen que utiliza un rango de valores mayor a las imágenes tradicionales, por ejemplo, en una imagen regular de 8 bits, los valores entre el negro y el blanco se encuentran en el intervalo $[0, 1]$. Sin embargo, en una HDRI se utilizan 32 bits de información, lo que da un rango $[0, 4 294 967 295]$. Esto permite que se pueda representar de mejor forma la información lumínica del entorno.
Hay algunos sitios que ofrecen de forma gratuita HDRIs, por ejemplo:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}